







在进行html的学习的时候,对于用什么软件来进行html的编写每个人都用自己的看法。有的人用记事本,有的人用dw,sw..等等。但是在我看来记事本过于简陋了,dw,sw比较笨重(当然实际的网站开发肯定是用着一类软件的)所以我选择了一个用的人比较多的文本编辑器:sublime text。 好了废话不多说,开始进入正题吧!
问题描述:
编写如图代码:
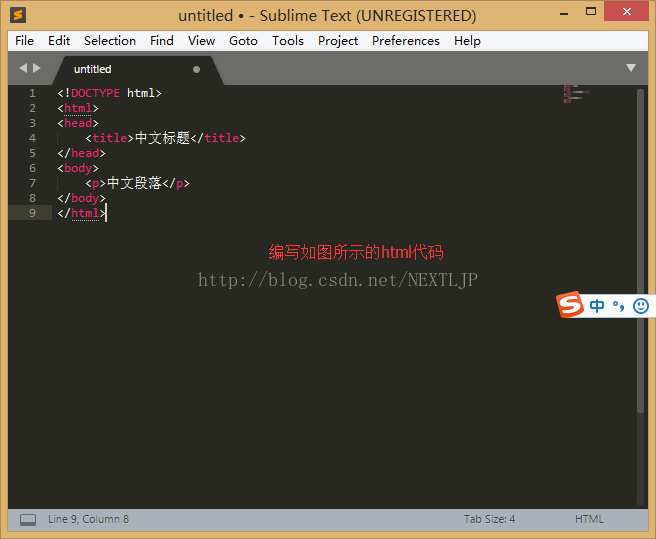
编写好了以后按Ctrl+s进行保存,生成.html文件也就是网页
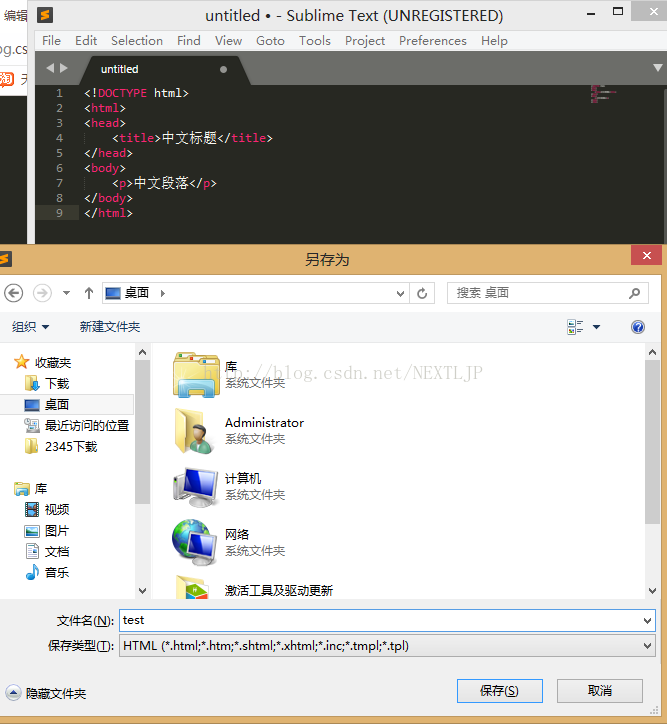
如图

好了现在我们的一个简单的网页就编写成功了,看看我们的效果吧!
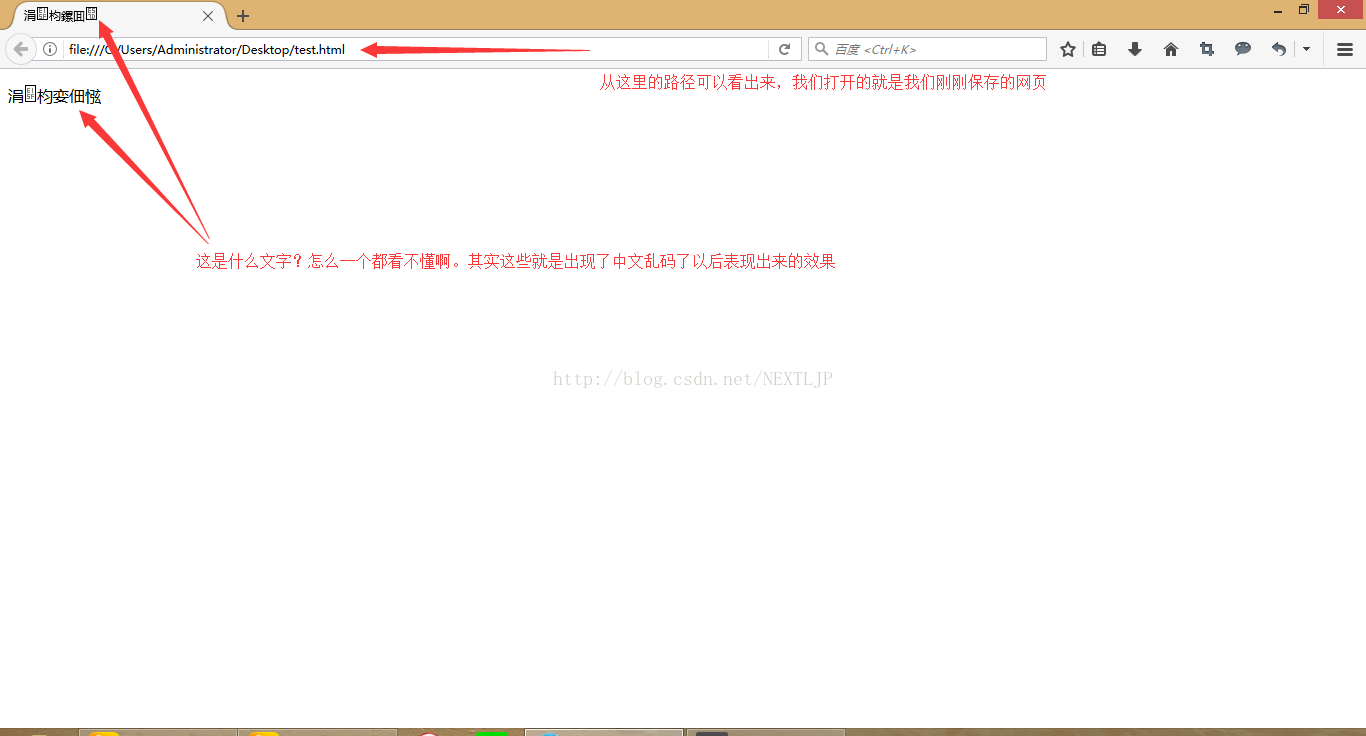
问题解决:
出现中文乱码的问题不仅是一个只在html网页文件的过程中才会出现的问题,可以说在计算机内涉及到中文显示或者输出都可能出现这种问题,例如数据库的存储,高级语言代码的编写等等。
首先我们必须知道我们的计算机存储中文的时候,计是不可能在计算机内直接存储中文的。而是通过某种编码方式(utf-8,gbk..)对中文进行编码,生成相应的二进制数字然后存储到计算机中。当我们需要显示这些存储的中文的时候,再通过译码将这些二进制数字翻译成相应的中文。
所以不管是什么时候出现这种问题。中文乱码的本质是你存储中文的时候使用的编码方式,在某个“译码的东西”下面对这种编码方式存储的中文进行译码的时候译不出来。至于这个“译码的东西”到底是什么呢?在不同的情况下面是不同的东西,在这里指的就是浏览器。所以你应该知道这个问题的原因了吧!原因就是:你在用sublime编写html的时候,在对这个html文件进行存储的时候sublime对中文用某种编码方法进行存储以后,在我们的浏览器上无法对中文编码进行译码。
所以我们怎么解决呢?解决方法就是:在进行存储的时候我们自己选定一下中文的编码方式就可以了。
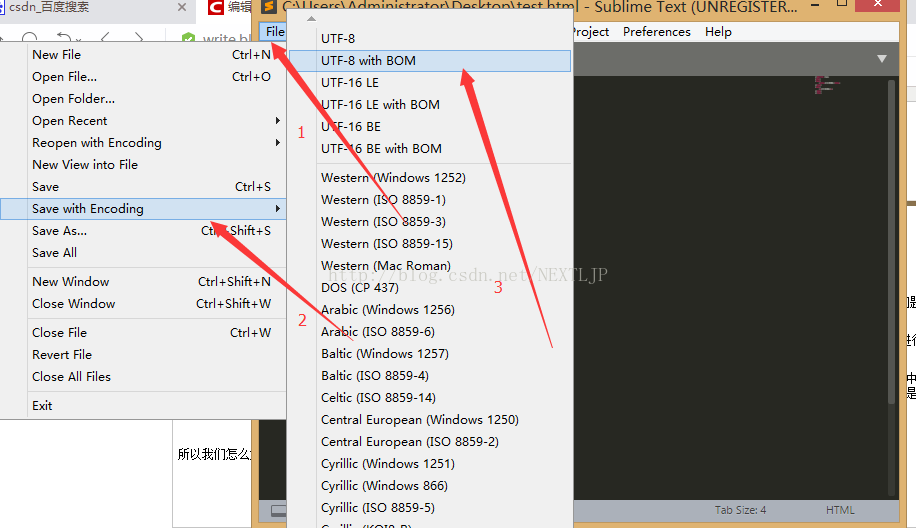
来看一下修改后的效果吧:
小疑问:
为什么我们要选择utf8 with bom,而不是utf8呢?这个bom是什么意思?
大家可以自行去找相应的资料
===============================================更新================================================================================
大家对我上面的这个小疑问有没有去找相应的资料呢?是不是搞清楚了呢?我想还是我在这里说明一下吧。
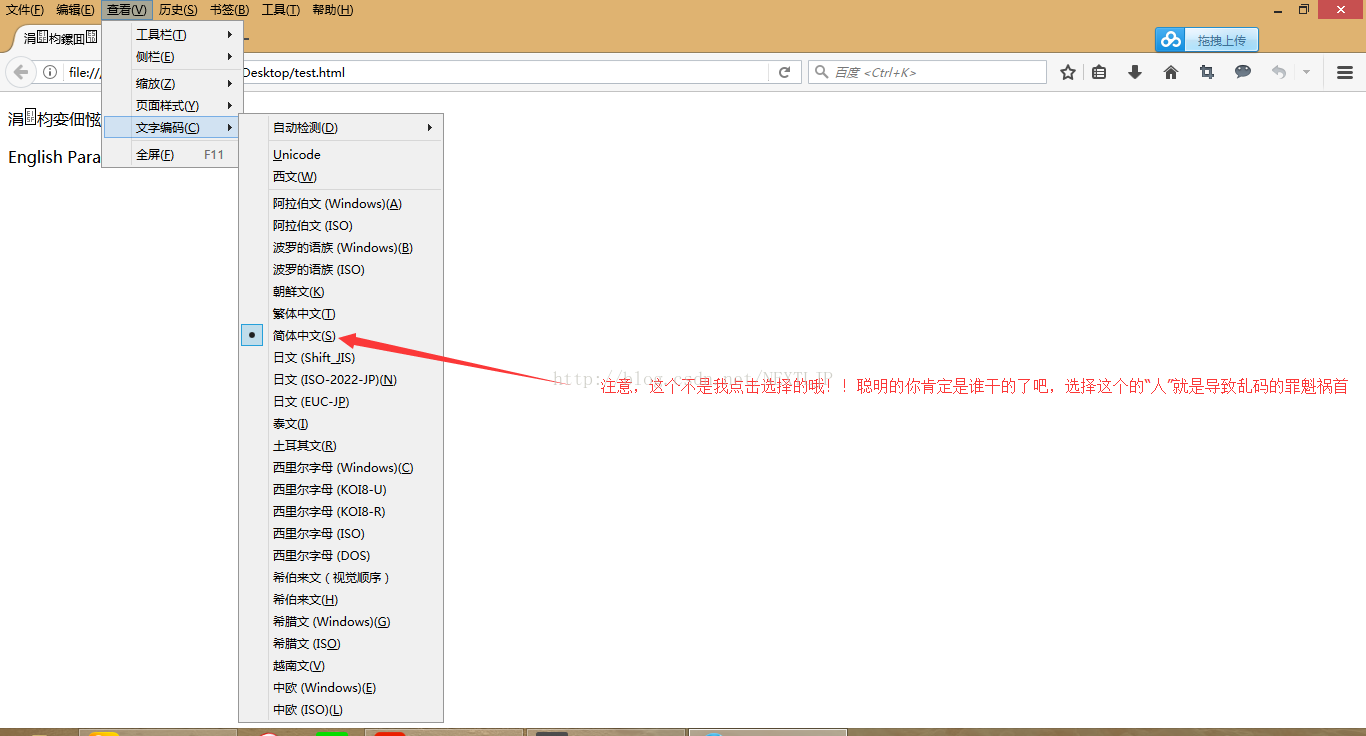
bom是一种标志。当你的浏览器在打开每一个html网页文件的时候,浏览器需要做的一件事就是确认这个html网页文件的编码方式是什么?是gb2312,还是utf8呢?而这个bom作用就是告诉浏览器这个html文件的编码方式,这样浏览器就知道该怎么去解释这个html文件里面的
![]() 内容了。反之如果这个html文件没有bom标志,浏览器就只能自己猜了,猜这个html的编码方式。运气不好就猜错了你就会出现乱码了!!!
内容了。反之如果这个html文件没有bom标志,浏览器就只能自己猜了,猜这个html的编码方式。运气不好就猜错了你就会出现乱码了!!!
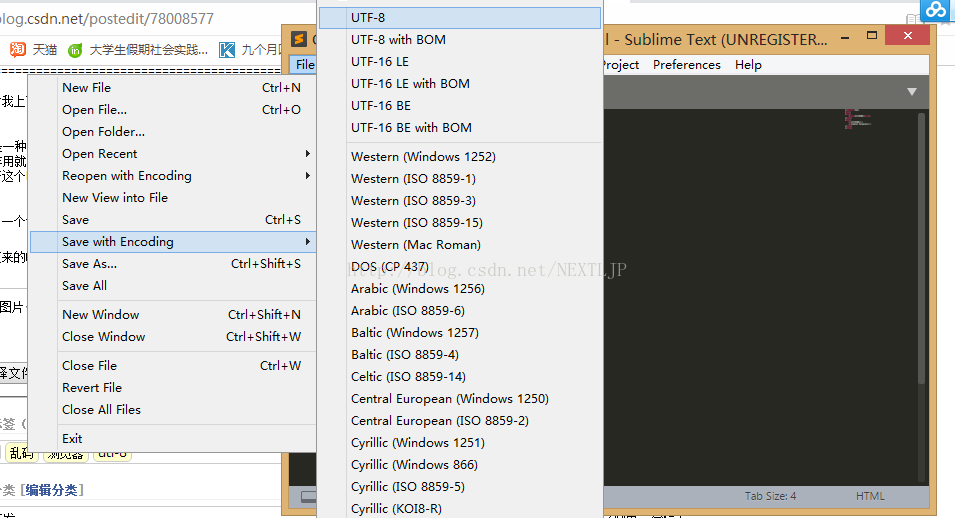
我们用一个例子来讲解一下吧:
还是原来的哪个test.html文件。我们这次用utf8 不带bom保存。如图
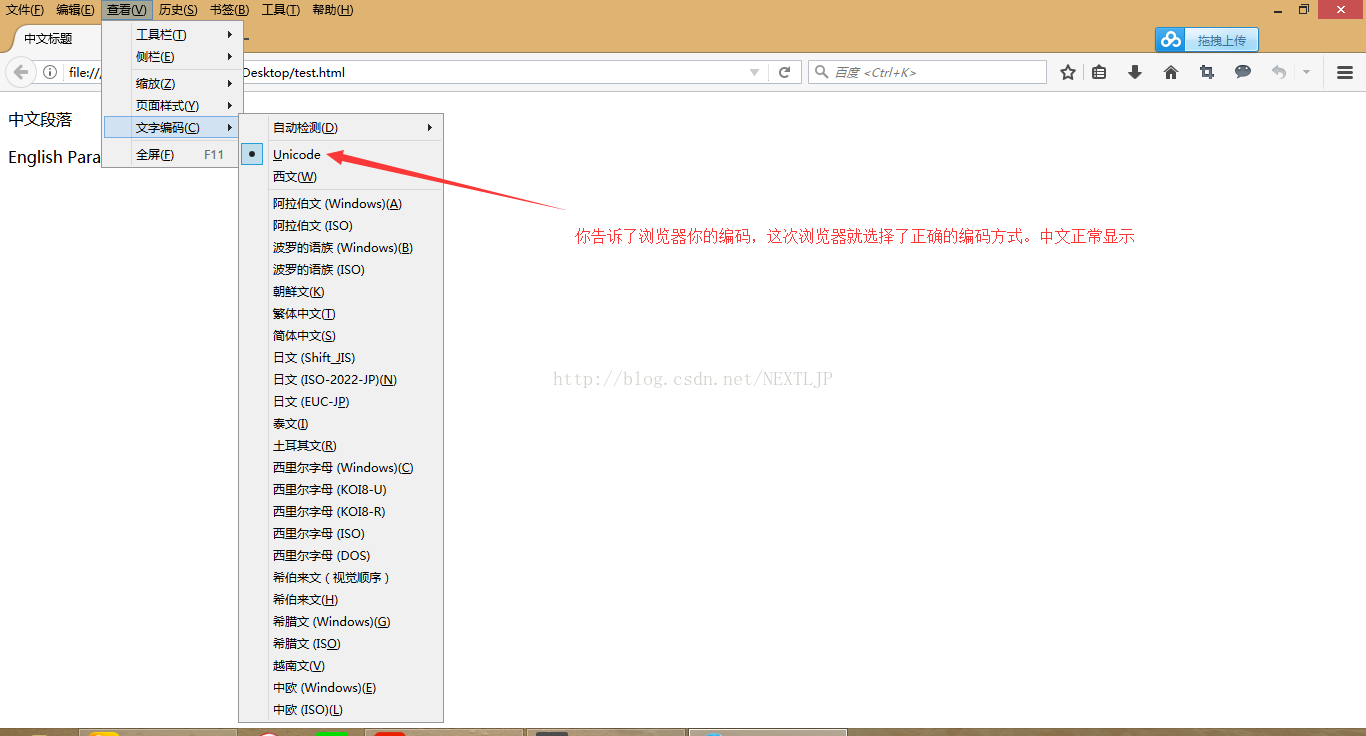
我们来看一下显示的效果:
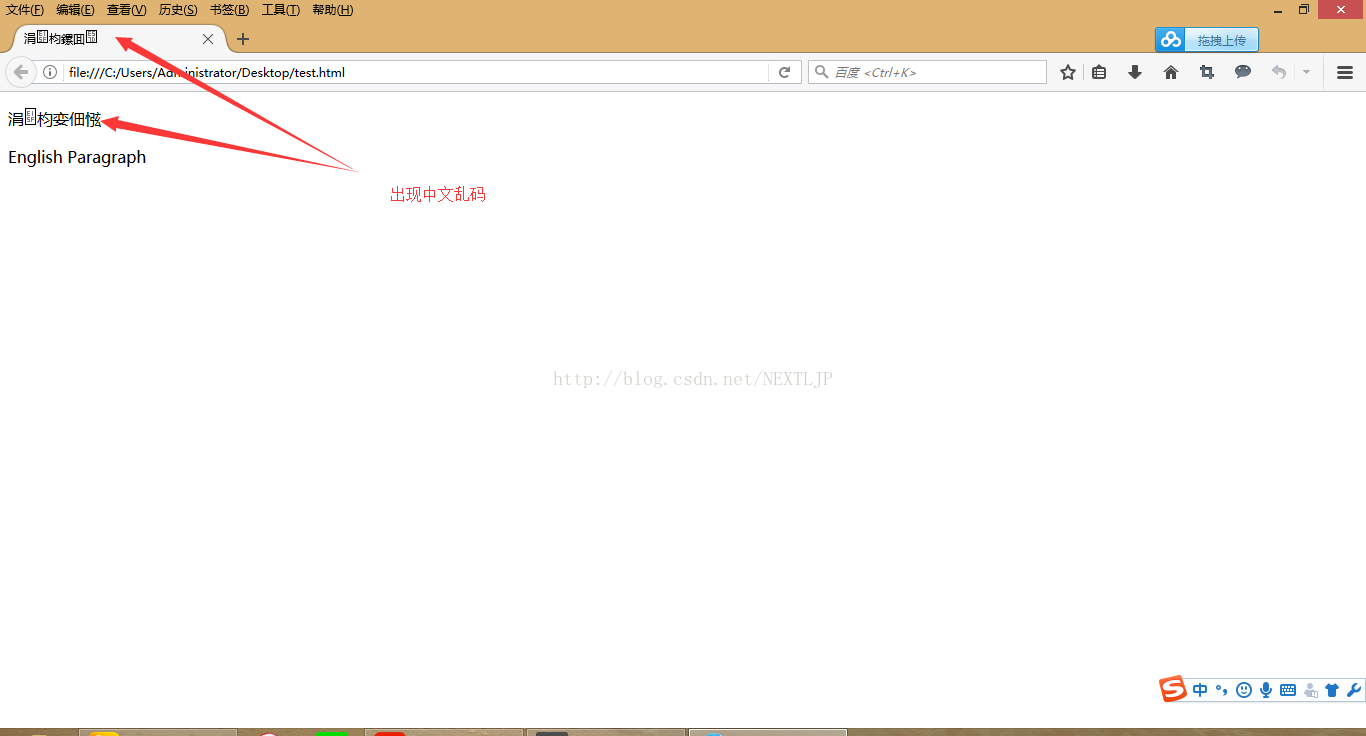
这个是怎么回事呢?给你看个好东西你就知道了的 哈哈。
现在我们来修改一下我们的代码
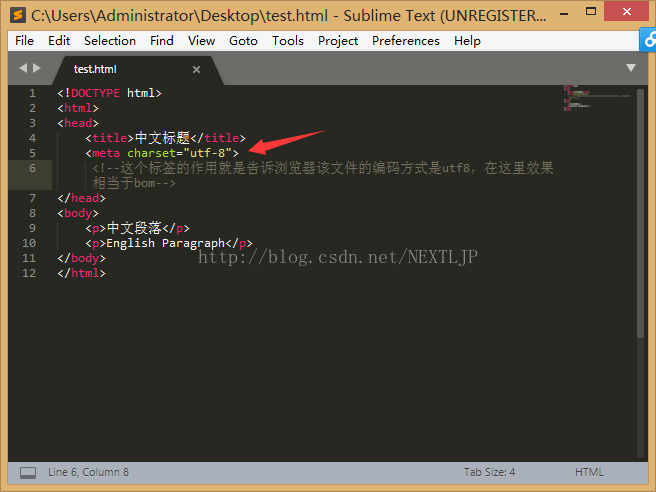
效果就是正确的了。
所以我们解决中文乱码的方法在这里讲解了俩中,第二种是比较常见的。但是不管是怎么解决,问题的本质都是一样的!!!
题外话:
我在这里说的编码方式不是一个专业名词,只是为了让你好理解哦。Unicode是字符集。utf-8是一种编码方式。字符集的意思分广义和狭义。从广义的方法来说字符集包括编码方式。从狭义的来说字符集和编码方式是完全不同的东西。而且我们在很多讲解文字编码的时候字符集和编码方式并不区分。就好像你说这个文件的编码方式是utf8那么肯定就是Unicode字符集。
比较详细的讲解在这里,有兴趣的可以看一下:点击打开链接















 799
799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









