







学习任务:
一、理解偏差和方差
- 概括:
算法的预测误差, 或者说泛化误差(generalization error)可以分解为三个部分: 偏差(bias), 方差(variance) 和噪声(noise). 在估计学习算法性能的过程中, 我们主要关注偏差与方差. 因为噪声属于不可约减的误差 (irreducible error). - 偏差:
这里的偏指的是 偏离 , 那么它偏离了什么到导致了误差? 潜意识上, 当谈到这个词时, 我们可能会认为它是偏离了某个潜在的 “标准”, 而这里这个 “标准” 也就是真实情况 (ground truth). 在分类任务中, 这个 “标准” 就是真实标签 (label).
$$ - 方差:
方差描述的是预测结果的稳定性,即数据集的变化对于预测结果的影响,同样也度量了数据集变化对于模型学习性能的变化,方差越小,说明我们的模型对于数据集的变化越不敏感,也就是对于新数据集的学习越稳定.

二、学习误差为什么是偏差和方差而产生的,并且推导数学公式

泛化误差:
以回归任务为例, 学习算法的平方预测误差期望为:
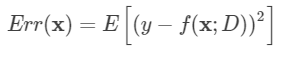
方差:
在一个训练集 D上模型 f对测试样本 x的预测输出为 f(x;D), 那么学习算法 f对测试样本 x 的 期望预测 为:
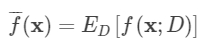
上面的期望预测也就是针对不同数据集 D, f 对 x 的预测值取其期望.
使用样本数相同的不同训练集产生的方差为:

噪声:
噪声为真实标记与数据集中的实际标记间的偏差:

偏差:
期望预测与真实标记的误差称为偏差(bias), 为了方便起见, 我们直接取偏差的平方:
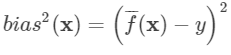
对算法的期望泛化误差进行分解:
三、过拟合,欠拟合,分别对应bias和variance什么情况

四、学习鞍点,复习上次任务学习的全局最优和局部最优
- 鞍点附近的某些点比鞍点有更大的代价,而其他点则有更小的代价。
- 一个不是局部极值点的驻点称为鞍点。

五、学习Mini-Batch与SGD
六、写出SGD和Mini-Batch的代码
七、学习回归模型评价指标
…未完待续















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









