







官网:Apache Doris: Open source data warehouse for real time data analytics - Apache Doris
一、Doris概述
Apache Doris 是一款基于 MPP 架构的高性能、实时分析型数据库。它以高效、简单和统一的特性著称,能够在亚秒级的时间内返回海量数据的查询结果。Doris 既能支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
基于这些优势,Apache Doris 非常适合用于报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等场景。用户可以基于 Doris 构建大屏看板、用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
1、核心特性
基于MPP(Massively Parallel Processing,即大规模并行处理)
- 分布式部署
- 列式存储
- 支持sql,兼容MySQL协议,支持JDBC/ODBC连接,易于集成BI工具,注重分析
- 海量数据
OLAP数据库
仅需亚秒级响应时间即可获得查询结果,有效的支持实时数据分析
分布式架构
易于运维和扩容,并且可以支持10PB以上的超大数据集
2、使用场景
实时数据分析
-
实时报表分析:实时数据看板;为企业内外部提供实时更新的报表和仪表盘,支持自动化流程中的实时决策需求。
-
即席查询: 提供多维数据分析能力,支持对数据进行快速的商业智能分析和即席查询(Ad Hoc),帮助 用户在复杂数据中快速发现洞察,比如小米公司基于Doris构建了增长分析平台,利用用户行为数据对业务进行增长分析,平均查询延时 10s,95 分位的查询延时 30s 以内,每天的 SQL 查询量为数万条。
-
用户行为与画像分析: 分析用户参与、留存、转化等行为,支持人群洞察和人群圈选等画像分析场景,高并发查询用户画像、漏斗分析。
湖仓融合与联邦查询
一个平台满足统一的湖仓一体架构,简化繁琐的大数据技术栈,海底捞基于Doris构建的统一数仓,替换了原来由Spark、Hive、Hbase等组成的旧架构,架构大大简化。
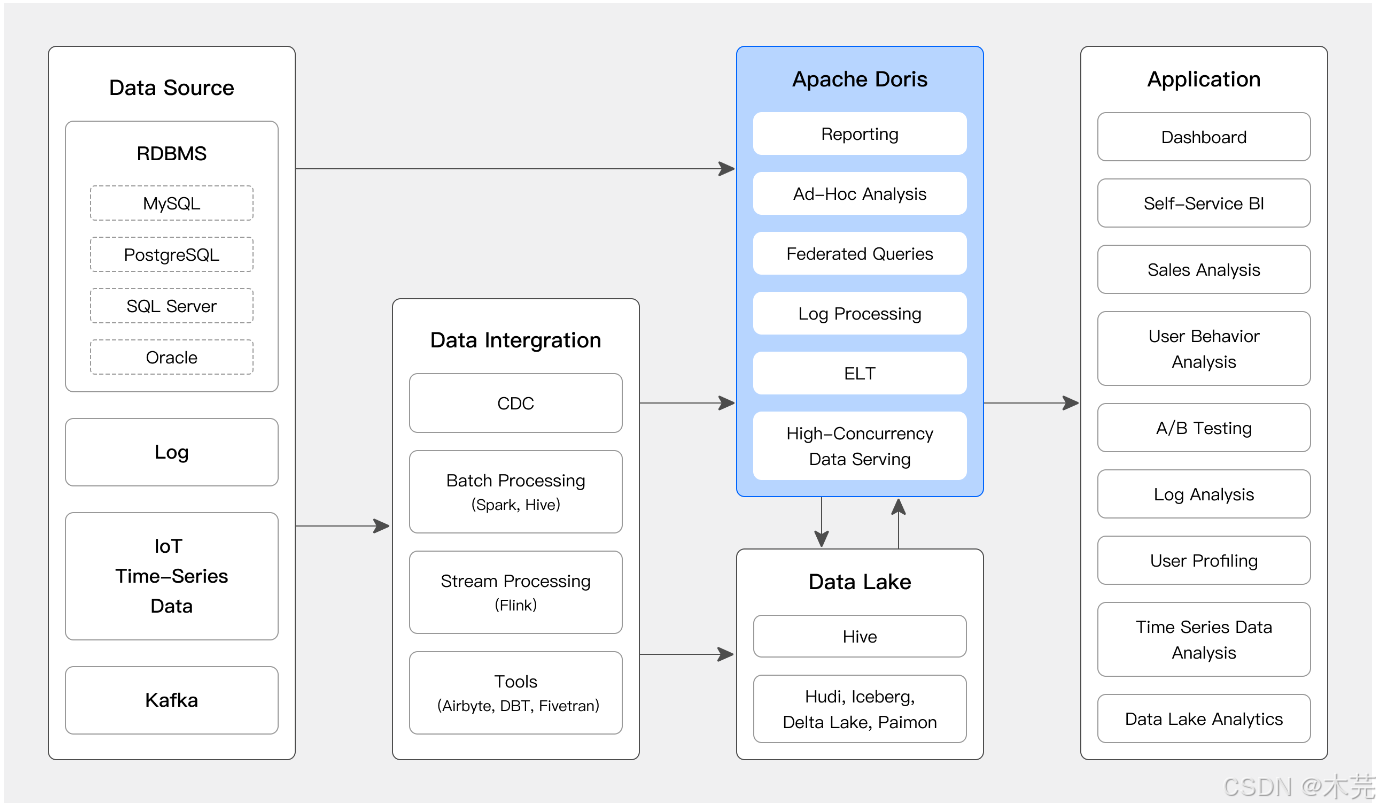
- 联邦查询能力:通过外接 Hive、Iceberg、Hudi等数据源,实现跨湖仓统一分析,避免数据冗余。
- 存算分离架构:3.0 版本支持存算分离部署,计算与存储资源独立扩展,可挂载 S3、HDFS 等共享存储,降低 TCO(总拥有成本)。
- 湖仓无界理念:既可作为高效查询引擎,也可作为开放数据湖,支持外部引擎直接读写数据,打破传统数据孤岛。
- 基于doris的湖仓一体典型企业实践案例
浙江霖梓(金融科技)采用 Doris + Apache Paimon 构建实时/离线一体化湖仓架构,替代原有 CDH 体系,解决计算延迟、运维复杂等问题。参考链接:https://zhuanlan.zhihu.com/p/23434421138
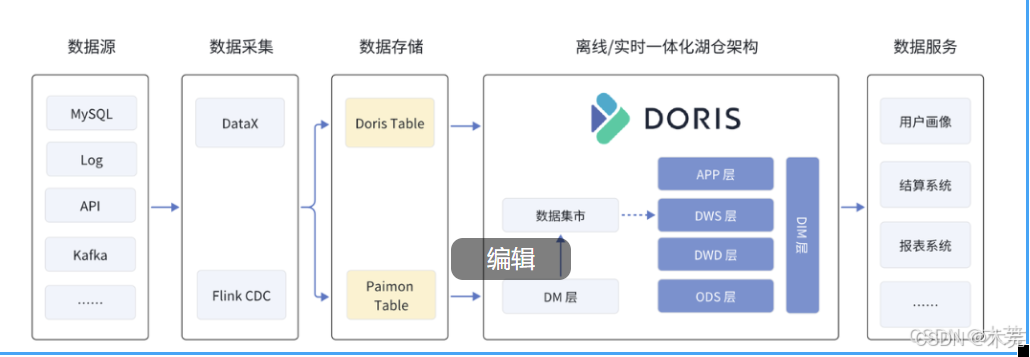
网易游戏引入 Doris 替换 ClickHouse,升级为湖仓一体架构,满足实时数据分析、高并发查询需求。参考链接:网易游戏如何基于 Apache Doris 构建全新湖仓一体架构-腾讯云开发者社区-腾讯云
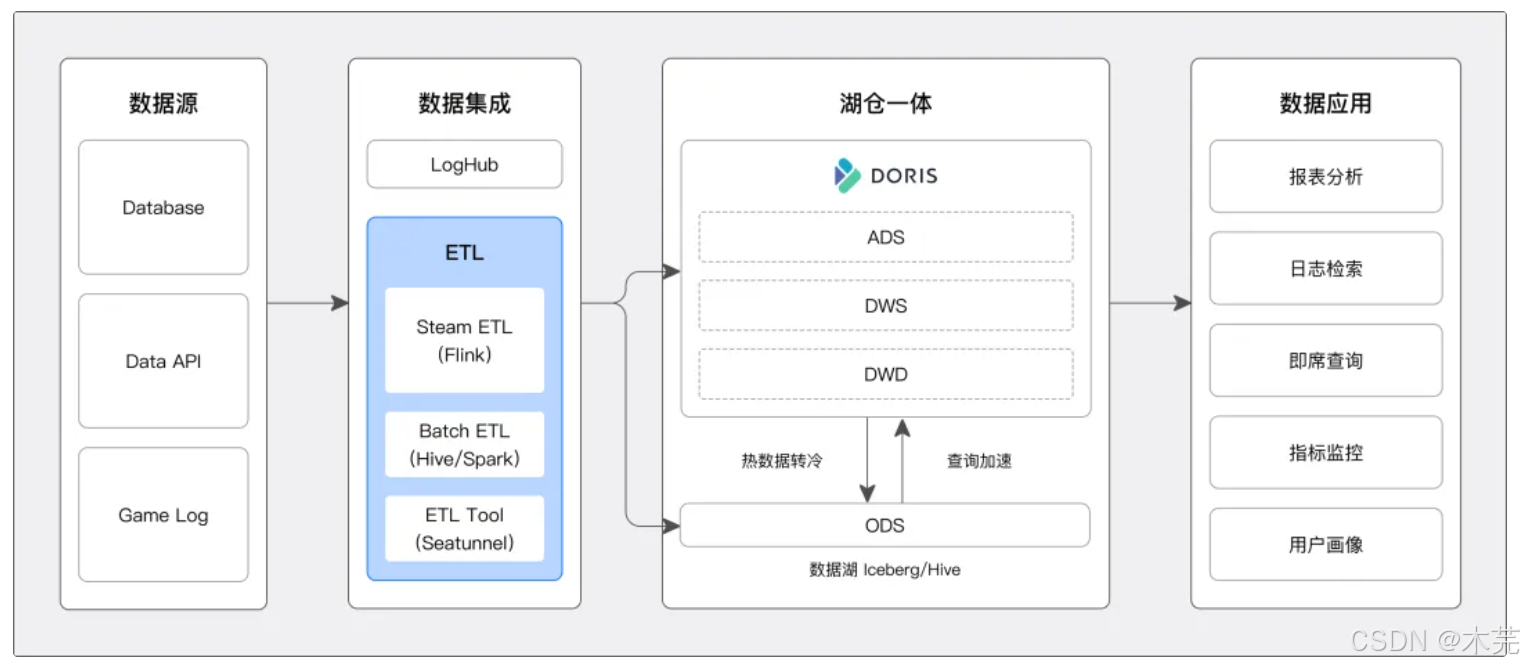
BI与可视化
支持Tableau、Superset等工具。
3、架构
doris的架构分为FE(Frontend)前端进程和BE(Backend)后端进程两个角色,两个后台的服务进程,不依赖于外部组件,方便部署和运维,FE和BE都可在线性扩展。
- FE(Frontend):负责元数据管理、查询解析、查询优化、任务调度和集群管理,包含三种角色:
Leader/Follower:通过选举机制实现元数据高可用,Leader 负责写入和元数据变更,Follower 同步数。
Observer:扩展查询节点,仅处理读请求,不参与元数据写入。
- BE(Backend):负责数据存储、计算和分布式执行,支持横向扩展至数百节点,存储容量可达数十 PB。
- Mysql Client:借助Mysql协议,用户可以任意Mysql的ODBC/JDBC以及Mysql的客户端,都可以访问doris。用户通过 MySQL 协议提交查询,FE 解析 SQL 并生成分布式执行计划,调度 BE 并行执行后返回结果。
- Broker:一个独立的无状态的进程。封装了文件系统接口,提供Doris读取远程存储系统中的文件能力,包括HDFS,S3,BOS等。
4、默认端口
| 端口 | 用途 | 说明 |
|---|---|---|
| 8030 | HTTP 服务端口 | 用于 Web 界面访问(如 Doris Manager)、集群监控、API 调用(如 Stream Load)。 |
| 9020 | FE 节点间 RPC 通信端口 | FE 节点元数据同步、心跳检测、Leader 选举等内部通信。 |
| 9030 | MySQL 协议查询端口 | 客户端通过 MySQL 协议连接 Doris(如 JDBC、MySQL 客户端),执行 SQL 查询。 |
| 8040 | HTTP 服务端口 | BE 节点监控指标查询、调试接口(如 Tablet 状态查看)。 |
| 9060 | BE 节点间 RPC 通信端口 | BE 节点数据同步、副本修复、数据分片迁移等内部通信。 |
| 9070 | BE 与 FE 的 RPC 通信端口 | FE 向 BE 下发查询任务、元数据同步等操作。 |
二、安装与部署
移步:单机安装及部署Doris3.0.2(最新最全超级详细图文解说)-CSDN博客
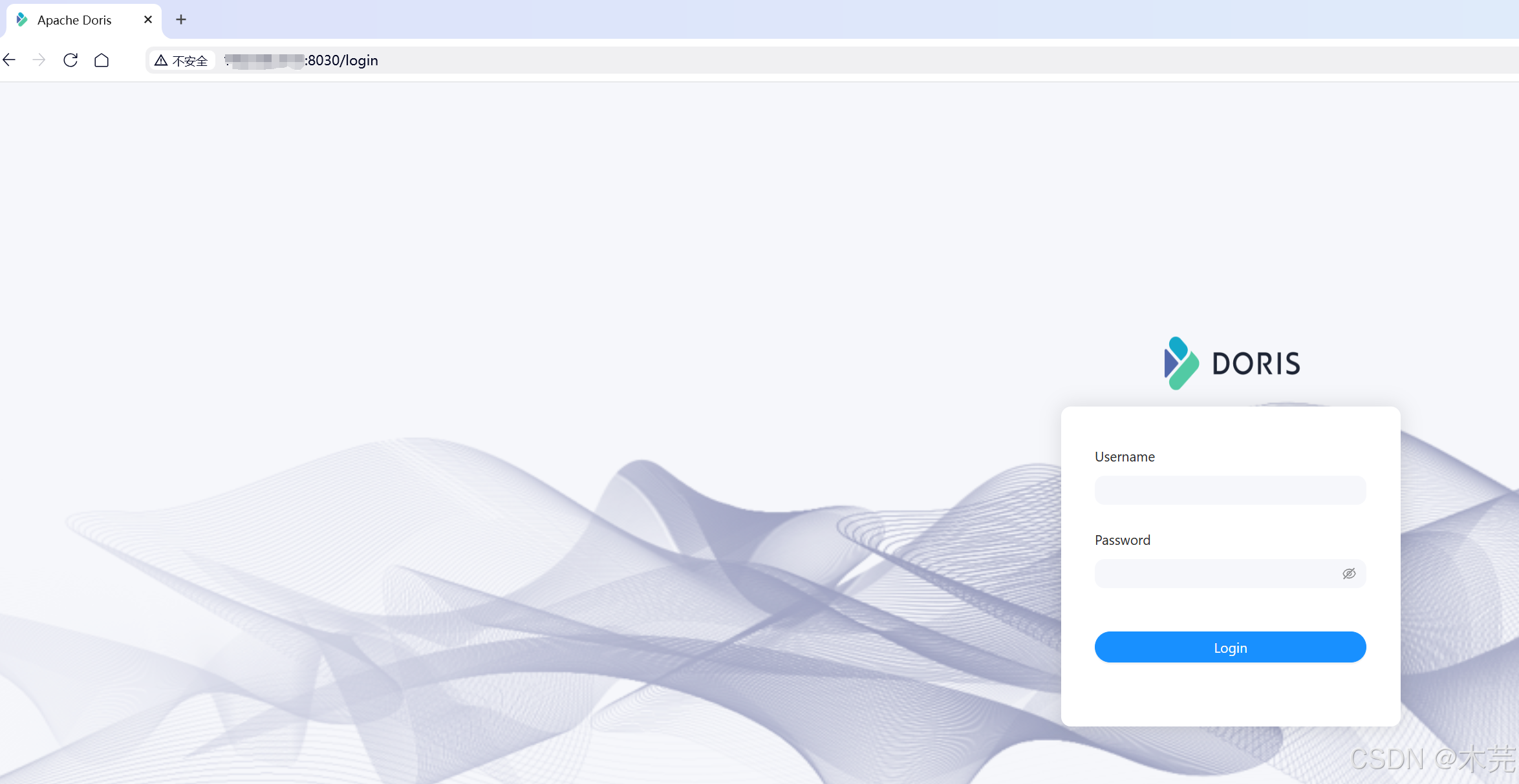
查看前端页面:
http://doris01(服务器ip):8030
账号root,密码123456
三、数据库表设计
1、数据类型
数值类型
| 类型名 | 存储空间(字节) | 描述 |
|---|---|---|
| BOOLEAN | 1 | 布尔值,0 代表 false,1 代表 true。 |
| TINYINT | 1 | 有符号整数,范围 [-128, 127]。 |
| SMALLINT | 2 | 有符号整数,范围 [-32768, 32767]。 |
| INT | 4 | 有符号整数,范围 [-2147483648, 2147483647] |
| BIGINT | 8 | 有符号整数,范围 [-9223372036854775808, 9223372036854775807]。 |
| LARGEINT | 16 | 有符号整数,范围 [-2^127 + 1 ~ 2^127 - 1]。 |
| FLOAT | 4 | 浮点数,范围 [-3.410^38 ~ 3.410^38]。 |
| DOUBLE | 8 | 浮点数,范围 [-1.7910^308 ~ 1.7910^308]。 |
| DECIMAL | 4/8/16 | 高精度定点数,格式:DECIMAL(M[,D])。其中,M 代表一共有多少个有效数字(precision),D 代表小数位有多少数字(scale)。有效数字 M 的范围是 [1, 38],小数位数字数量 D 的范围是 [0, precision]。0 < precision <= 9 的场合,占用 4 字节。9 < precision <= 18 的场合,占用 8 字节。16 < precision <= 38 的场合,占用 16 字节。 |
日期类型
| 类型名 | 存储空间(字节) | 描述 |
|---|---|---|
| DATE | 16 | 日期类型,目前的取值范围是 ['0000-01-01', '9999-12-31'],默认的打印形式是 'yyyy-MM-dd'。 |
| DATETIME | 16 | 日期时间类型,格式:DATETIME([P])。可选参数 P 表示时间精度,取值范围是 [0, 6],即最多支持 6 位小数(微秒)。不设置时为 0。 取值范围是 ['0000-01-01 00:00:00[.000000]', '9999-12-31 23:59:59[.999999]']。打印的形式是 'yyyy-MM-dd HH:mm:ss.SSSSSS'。 |
字符串类型
| 类型名 | 存储空间(字节) | 描述 |
|---|---|---|
| CHAR | M | 定长字符串,M 代表的是定长字符串的字节长度。M 的范围是 1-255。 |
| VARCHAR | 不定长 | 变长字符串,M 代表的是变长字符串的字节长度。M 的范围是 1-65533。变长字符串是以 UTF-8 编码存储的,因此通常英文字符占 1 个字节,中文字符占 3 个字节。 |
| STRING | 不定长 | 变长字符串,默认支持 1048576 字节(1MB),可调大到 2147483643 字节(2GB)。可通过 BE 配置 string_type_length_soft_limit_bytes 调整。String 类型只能用在 Value 列,不能用在 Key 列和分区分桶列。 |
半结构类型
| 类型名 | 存储空间(字节) | 描述 |
|---|---|---|
| ARRAY | 不定长 | 由 T 类型元素组成的数组,不能作为 Key 列使用。目前支持在 Duplicate 和 Unique 模型的表中使用。 |
| MAP | 不定长 | 由 K, V 类型元素组成的 map,不能作为 Key 列使用。目前支持在 Duplicate 和 Unique 模型的表中使用。 |
| STRUCT | 不定长 | 由多个 Field 组成的结构体,也可被理解为多个列的集合。不能作为 Key 使用,目前 STRUCT 仅支持在 Duplicate 模型的表中使用。一个 Struct 中的 Field 的名字和数量固定,总是为 Nullable。 |
| JSON | 不定长 | 二进制 JSON 类型,采用二进制 JSON 格式存储,通过 JSON 函数访问 JSON 内部字段。长度限制和配置方式与 String 相同 |
| VARIANT | 不定长 | 动态可变数据类型,专为半结构化数据如 JSON 设计,可以存入任意 JSON,自动将 JSON 中的字段拆分成子列存储,提升存储效率和查询分析性能。长度限制和配置方式与 String 相同。Variant 类型只能用在 Value 列,不能用在 Key 列和分区分桶列。这个类型是doris2+以后的版本才有 |
2、表的基本概念
行与列
row一行数据,column用于描述一行数据中不同的字段
doris的列分为两类:key和value
*建表语句中的指定key,不是主键的意思,如果是agg模型(聚合模型),key就是分组聚合使用;是unique模型(主键模型)的key是唯一值(主键作用);是duplicate模型(明细模型)key有两个作用,第一作用是分区、分桶必须是key字段,第二个作用主要是用于排序
分区
partition(分区)
- 是在逻辑上将一张表按行(横向)划分
- 分区可以指定一列或者多列,在聚合模型中,分区列必须是key列。
- 无论分区列是什么类型,写分区值时都必须加双引号
- 分区数量理论上没有上限
- 在不使用partition建表时,系统会自动生成一个和表名同名的全值范围的分区,该分区对用户不可见,并且不可删改。
- 创建分区不可范围重复(range分区)
Range分区(范围分区)
有四种写法,具体了解请往官网
常用分区写法LESS THAN:仅定义分区上界。下界由上一个分区的上界决定。
PARTITION BY RANGE(col1[, col2, ...])
(
PARTITION partition_name1 VALUES LESS THAN MAXVALUE | ("value1", "value2", ...),
PARTITION partition_name2 VALUES LESS THAN MAXVALUE | ("value1", "value2", ...)
)
示例如下:
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01"),
PARTITION `p2018` VALUES [("2018-01-01"), ("2019-01-01")),
PARTITION `other` VALUES LESS THAN (MAXVALUE)小于2017-04-01,前闭后开【2017-03-01,2017-04-01)
List分区
分区列支持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。
Partition 支持通过 VALUES IN (...) 来指定每个分区包含的枚举值。
举例如下:
PARTITION BY LIST(city)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
List 分区也支持多列分区,示例如下:
PARTITION BY LIST(id, city)
(
PARTITION p1_city VALUES IN (("1", "Beijing"), ("1", "Shanghai")),
PARTITION p2_city VALUES IN (("2", "Beijing"), ("2", "Shanghai")),操作示例:
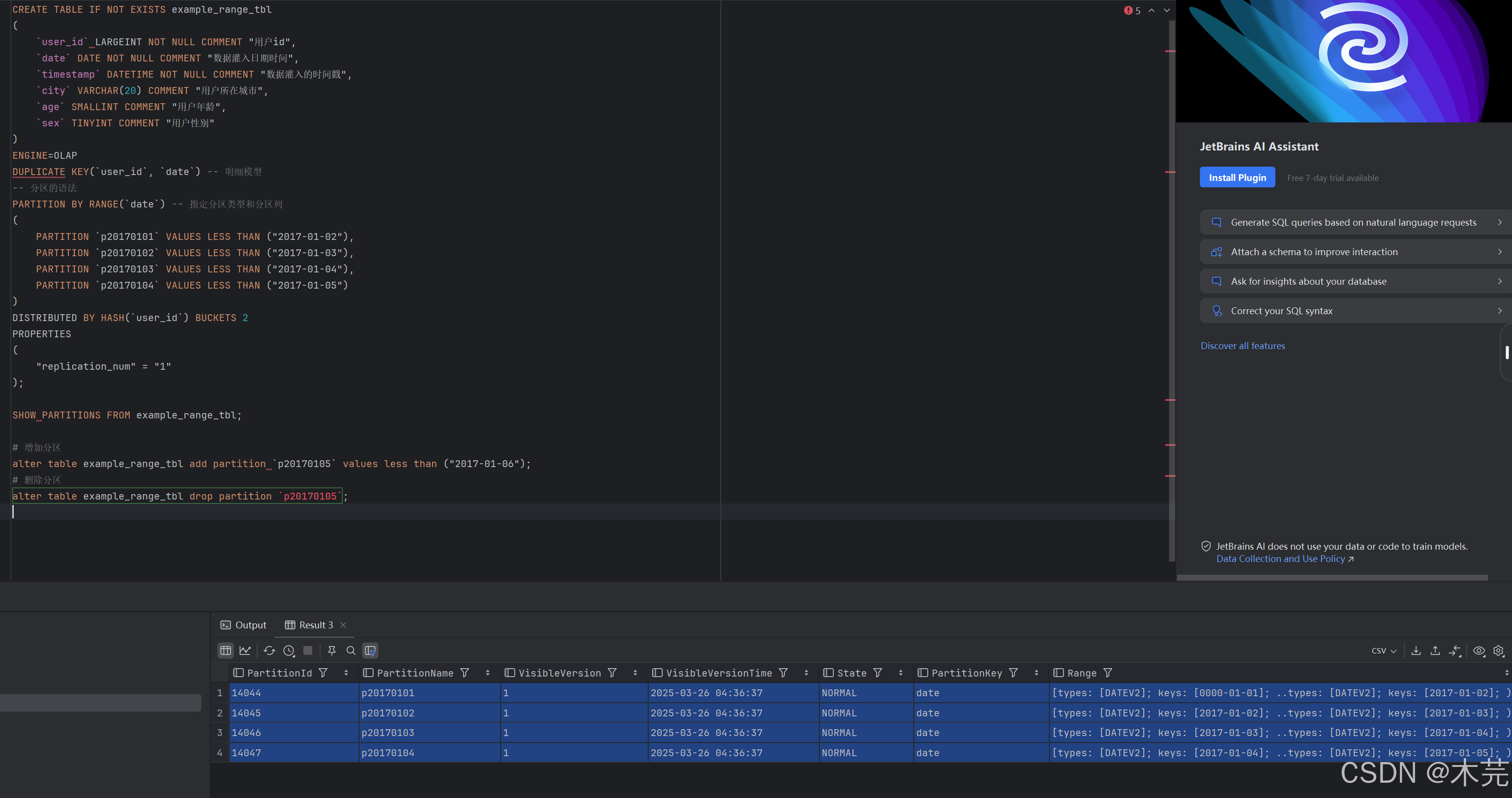
CREATE TABLE IF NOT EXISTS example_range_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别"
)
ENGINE=OLAP
DUPLICATE KEY(`user_id`, `date`) -- 明细模型
-- 分区的语法
PARTITION BY RANGE(`date`) -- 指定分区类型和分区列
(
PARTITION `p20170101` VALUES LESS THAN ("2017-01-02"),
PARTITION `p20170102` VALUES LESS THAN ("2017-01-03"),
PARTITION `p20170103` VALUES LESS THAN ("2017-01-04"),
PARTITION `p20170104` VALUES LESS THAN ("2017-01-05")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 2
PROPERTIES
(
"replication_num" = "1"
);
SHOW PARTITIONS FROM example_range_tbl;
增删分区:
# 增加分区
alter table example_range_tbl add partition `p20170105` values less than ("2017-01-06");
# 删除分区
alter table example_range_tbl drop partition `p20170105`;
分桶
bucket,又称(tablet)分片
- 一个分区可以根据业务需求进一步划分为多个数据分桶(bucket)。每个分桶都作为一个物理数据分片(tablet)存储。合理的分桶策略可以有效降低查询时的数据扫描量,提升查询性能并增加并发处理能力。
- 只有 Hash 分桶需要选择分桶键,Random 分桶不需要选择分桶键。分桶可以多列,但必须是key列,分桶的数量理论上没有上限。
手动分桶
一个表的Tablet总数量等于(Partition num * Bucket num)
在决定分桶数量时,通常遵循数量与大小两个原则,当发生冲突时,优先考虑大小原则:
-
大小原则:建议一个 tablet 的大小在 1-10G 范围内。过小的 tablet 可能导致聚合效果不佳,增加元数据管理压力;过大的 tablet 则不利于副本迁移、补齐,且会增加 Schema Change 操作的失败重试代价;
-
数量原则:在不考虑扩容的情况下,一个表的 tablet 数量建议略多于整个集群的磁盘数量。
在建表时,每个分区的分桶数量统一指定,一旦指定不可更改,但是在动态增加分区(add partition),可以单独指定新分区的分桶数量,可以利用这个功能翻遍的应对数据缩小或膨胀
例如,假设有 10 台 BE 机器,每个 BE 一块磁盘,可以按照以下建议进行数据分桶:
| 单表大小 | 建议分桶数量 |
|---|---|
| 500MB | 4-8 个分桶 |
| 5GB | 6-16 个分桶 |
| 50GB | 32 个分桶 |
| 500GB | 建议分区,每个分区 50GB,每个分区 16-32 个分桶 |
| 5TB | 建议分区,每个分区 50GB,每个分桶 16-32 个分桶 |
提示
表的数据量可以通过 SHOW DATA 命令查看。结果需要除以副本数,即表的数据量。
示例场景
- 场景1:日增100GB数据,按天分区,集群有20个BE节点。
- 分桶数计算:100GB / 2GB = 50分桶(满足单分桶2GB)。
- 总Tablet数:50分桶×3副本=150,符合集群资源要求。
- 场景2:维度表500MB,查询频繁。
分桶数设为5,单分桶100MB,避免小文件问题
DISTRIBUTED BY HASH(id) BUCKETS 10
自动分桶
用户经常设置不合适的 bucket,导致各种问题,这里提供一种方式,来自动设置分桶数。当前只对 OLAP 表生效。
新增的配置参数 estimate_partition_size 表示一个单分区的数据量。该参数是可选的,如果没有给出则 Doris 会将 estimate_partition_size 的默认值取为 10GB。从上文中已经得知,一个分桶在物理层面就是一个 Tablet,为了获得最好的性能,建议 Tablet 的大小在 1GB - 10GB 的范围内,创建语句如下:
DISTRIBUTED BY HASH(site) BUCKETS AUTO
properties("estimate_partition_size" = "2G")CREATE TABLE if not exists user_behavior (
user_id INT,
item_id INT,
dt DATETIME
)
DUPLICATE KEY(user_id,item_id)
PARTITION BY RANGE(dt)()
DISTRIBUTED BY HASH(user_id) BUCKETS AUTO -- 启用自动分桶
PROPERTIES ("replication_num" = "1",
"estimate_partition_size" = "2G"); -- 可选:预分区大小提示
--查看分区分桶,分桶情况看Buckets,Datasize字段
SHOW PARTITIONS FROM user_behavior;
选择建议
| 维度 | 手动分桶 | 自动分桶 |
|---|---|---|
| 适用场景 | 数据量稳定、查询模式固定、需精细化控制的场景 | 数据量波动大、需快速部署的场景 |
| 运维复杂度 | 高(需持续调整) | 低(自动适配) |
| 性能优化 | 可针对业务需求调优 | 依赖系统预估,可能次优 |
| 版本要求 | 无特殊限制 | Doris 1.2.2+ 支持 |
最佳实践
混合使用:对历史数据使用自动分桶,新增分区时手动调整分桶数以应对数据膨胀。
监控与调优:定期检查Tablet大小(SHOW TABLET),避免单个Tablet超过10GB。
分桶列选择:优先选择区分度高、Join 查询频繁的列(如用户ID、地区),避免数据倾斜。
PROPERTIES
- replication_num(分片副本数)
每个tablet的副本数量,默认为3,建议保持默认即可,如果单机部署的doris,在建表语句里面"replication_num" = "1"
- storage_medium(存储介质)
- storage_cooldown_time(热数据冷却时间)
建表时,可以统一指定所有 Partition 初始存储的介质及热数据的冷却时间,如:
"storage_medium" = "SSD"
"storage_cooldown_time" = "2023-04-20 00:00:00" 要在当前时间之后,并且是一个datetime类型默认初始存储介质可通过 fe 的配置文件 fe.conf 中指定 default_storage_medium=xxx,如果没有指定,则默认为 HDD。如果指定为 SSD,则数据初始存放在 SSD 上。没设storage_cooldown_time,则默认 30 天后,数据会从 SSD自动迁移到 HDD上。如果指定了 storage_cooldown_time,则在到达 storage_cooldown_time 时间后,数据才会迁移。
注意,当指定 storage_medium 时,如果 FE 参数 enable_strict_storage_medium_check 为False 该参数只是一个“尽力而为”的设置。即使集群内没有设置 SSD 存储介质,也不会报错,而是自动存储在可用的数据目录中。 同样,如果 SSD 介质不可访问、空间不足,都可能导致数据初始直接存储在其他可用介质上。而数据到期迁移到 HDD 时,如果 HDD 介质不 可 访 问 、 空 间 不 足 , 也 可 能 迁 移 失 败 ( 但 是 会 不 断 尝 试 ) 。 如 果 FE 参 数enable_strict_storage_medium_check 为 True 则当集群内没有设置 SSD 存储介质时,会报错Failed to find enough host in all backends with storage medium is SSD。
3、数据表模型
Doris 的数据模型主要分为3类:
- Aggregate 聚合模型
- Unique 主键模型
- Duplicate 明细模型
聚合模型(Aggregate )
是相同key的数据进行自动聚合的表模型。Doris 存储层保留聚合后的数据,从而可以减少存储空间和提升查询性能;通常用于需要汇总或聚合信息(如总数或平均值)的情况。
使用场景
-
明细数据进行汇总:用于电商平台的月销售业绩、金融风控的客户交易总额、广告投放的点击量等业务场景中,进行多维度汇总;
-
不需要查询原始明细数据:如驾驶舱报表、用户交易行为分析等,原始数据存储在数据湖中,仅需存储汇总后的数据。
可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
数据导入时,Key 列会聚合成一行,Value 列会按照指定的聚合类型进行维度聚合,在聚合表中支持以下类型的维度聚合:
| 聚合类型 | 描述 |
|---|---|
| SUM | 求和,多行的 Value 进行累加。 |
| REPLACE | 替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。 |
| MAX | 保留最大值。 |
| MIN | 保留最小值。 |
| REPLACE_IF_NOT_NULL | 非空值替换。与 REPLACE 的区别在于对 null 值,不做替换。 |
| HLL_UNION | HLL 类型的列的聚合方式,通过 HyperLogLog 算法聚合。 |
| BITMAP_UNION | BITMAP 类型的列的聚合方式,进行位图的并集聚合。 |
执行原理
-
数据导入阶段:数据按批次导入,每批次生成一个版本,并对相同聚合键的数据进行初步聚合(如求和、计数);
-
底层BE进行数据合并阶段(Compaction):BE会对已导入的不同批次数据进行进一步的聚合;
-
查询阶段:查询时,系统会聚合同一聚合键的数据,确保查询结果准确。
操作示例
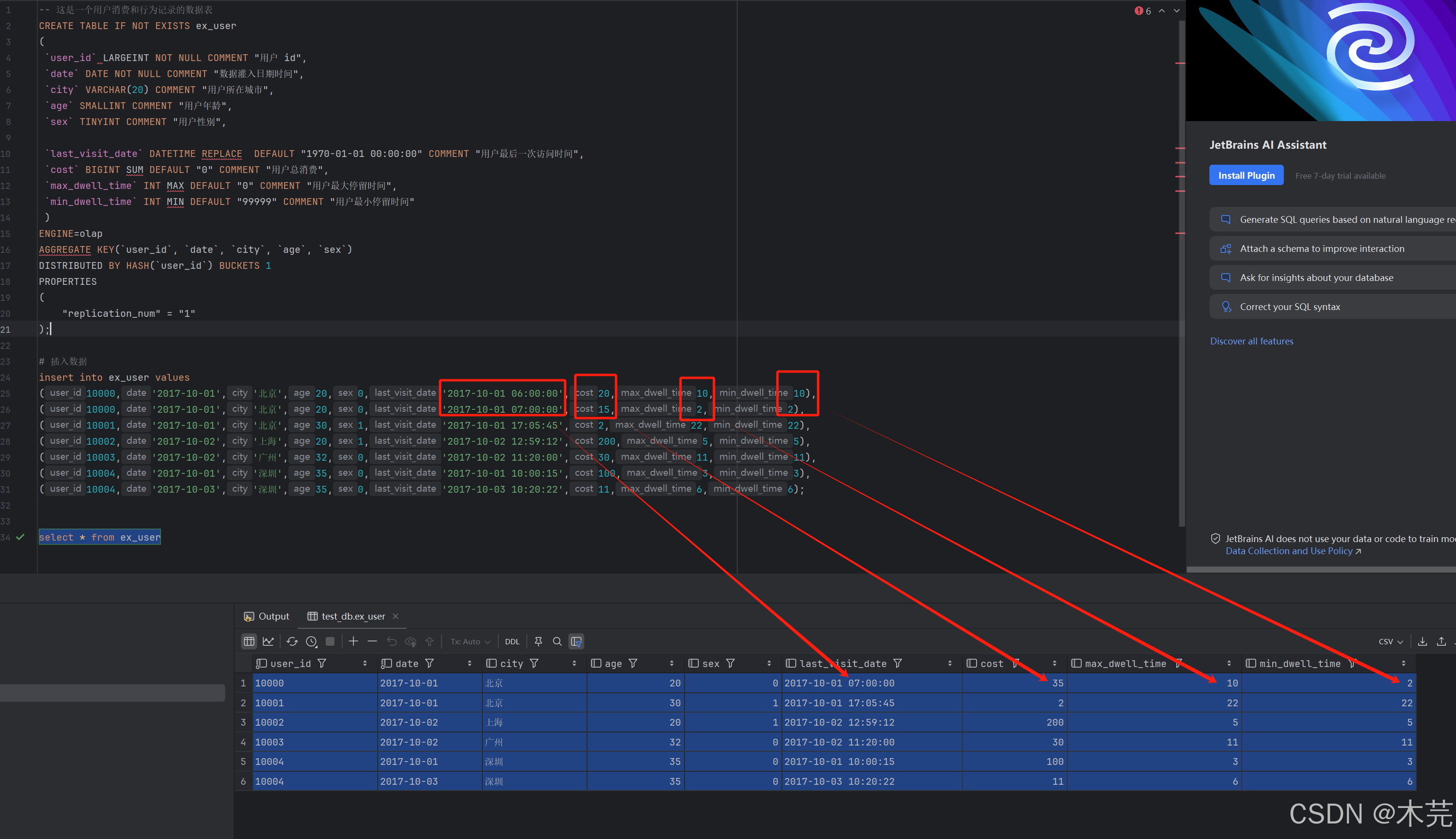
-- 这是一个用户消费和行为记录的数据表
CREATE TABLE IF NOT EXISTS ex_user
(
`user_id` LARGEINT NOT NULL COMMENT "用户 id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES
(
"replication_num" = "1"
);
# 插入数据
insert into ex_user values
(10000,'2017-10-01','北京',20,0,'2017-10-01 06:00:00',20,10,10),
(10000,'2017-10-01','北京',20,0,'2017-10-01 07:00:00',15,2,2),
(10001,'2017-10-01','北京',30,1,'2017-10-01 17:05:45',2,22,22),
(10002,'2017-10-02','上海',20,1,'2017-10-02 12:59:12',200,5,5),
(10003,'2017-10-02','广州',32,0,'2017-10-02 11:20:00',30,11,11),
(10004,'2017-10-01','深圳',35,0,'2017-10-01 10:00:15',100,3,3),
(10004,'2017-10-03','深圳',35,0,'2017-10-03 10:20:22',11,6,6);
select * from ex_user
主键模型(Unique)
是相同key的数据进行自动去重的表模型。该模型保证 Key 列的唯一性,插入或更新数据时,新数据会覆盖具有相同 Key 的旧数据,确保数据记录为最新。与其他数据模型相比,主键模型适用于数据的更新场景,在插入过程中进行主键级别的更新覆盖。
主键模型特点
-
基于主键进行 UPSERT:在插入数据时,主键重复的数据会更新,主键不存在的记录会插入;
-
基于主键进行去重:主键模型中的 Key 列具有唯一性,会对根据主键列对数据进行去重操作;
-
高频数据更新:支持高频数据更新场景,同时平衡数据更新性能与查询性能。
使用场景
-
高频数据更新:适用于上游 OLTP 数据库中的维度表,实时同步更新记录,并高效执行 UPSERT 操作;
-
数据高效去重:如广告投放和客户关系管理系统中,使用主键模型可以基于用户 ID 高效去重;
-
需要部分列更新:如画像标签场景需要变更频繁改动的动态标签,消费订单场景需要改变交易的状态。通过主键模型部分列更新能力可以完成某几列的变更操作。
操作示例
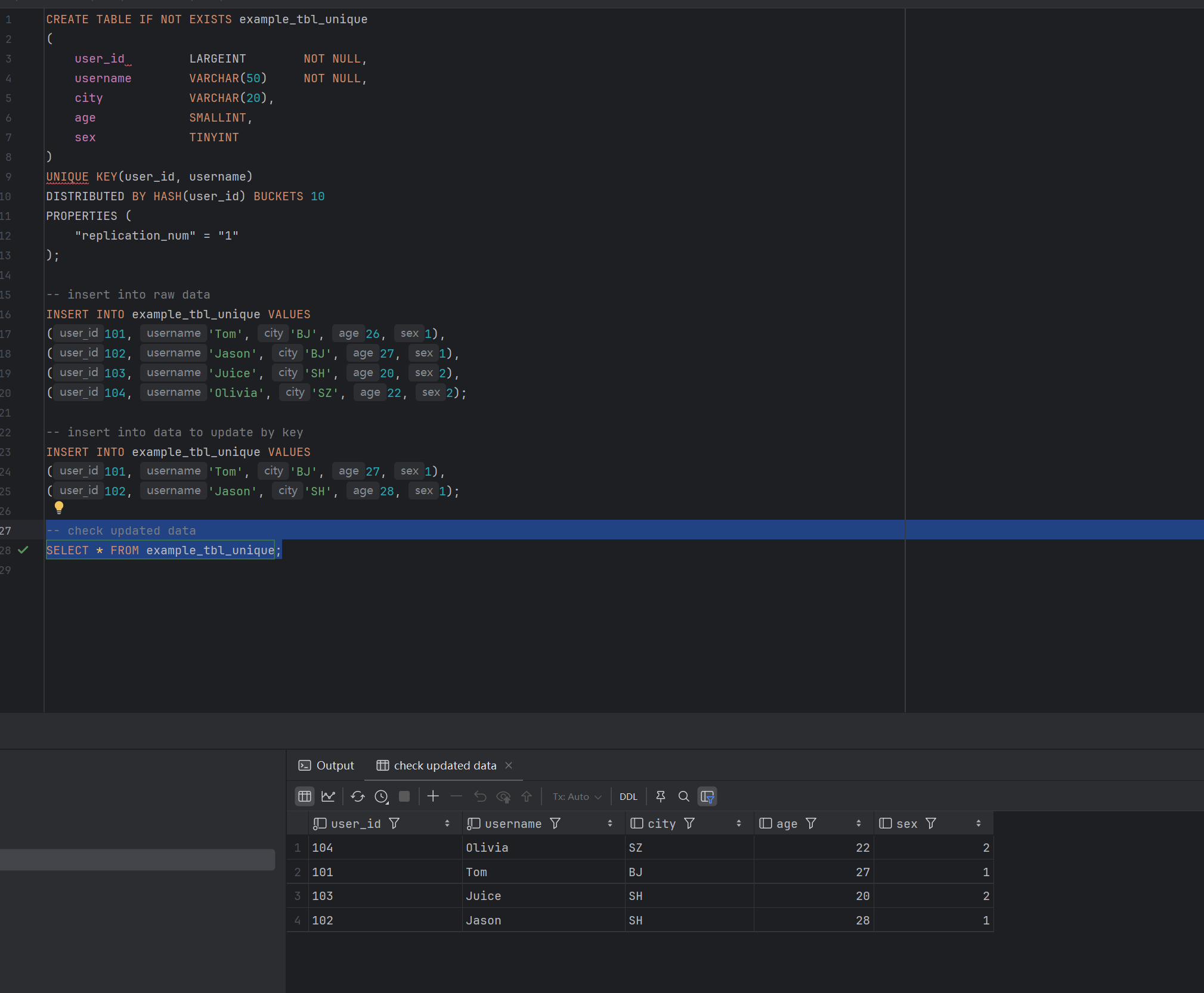
CREATE TABLE IF NOT EXISTS example_tbl_unique
(
user_id LARGEINT NOT NULL,
username VARCHAR(50) NOT NULL,
city VARCHAR(20),
age SMALLINT,
sex TINYINT
)
UNIQUE KEY(user_id, username)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);
-- 插入数据
INSERT INTO example_tbl_unique VALUES
(101, 'Tom', 'BJ', 26, 1),
(102, 'Jason', 'BJ', 27, 1),
(103, 'Juice', 'SH', 20, 2),
(104, 'Olivia', 'SZ', 22, 2);
-- 插入数据并按key更新
INSERT INTO example_tbl_unique VALUES
(101, 'Tom', 'BJ', 27, 1),
(102, 'Jason', 'SH', 28, 1);
-- check updated data
SELECT * FROM example_tbl_unique;
明细模型(Duplicate)
是存明细数据的表模型,既不做聚合也不做去重。明细模型是 Doris 中的默认建表模型,用于保存每条原始数据记录。在建表时,通过 DUPLICATE KEY 指定数据存储的排序列,以优化常用查询。一般建议选择三列或更少的列作为排序键,具体选择方式参考排序键。
明细模型特点
-
保留原始数据:明细模型保留了全量的原始数据,适合于存储与查询原始数据。对于需要进行详细数据分析的应用场景,建议使用明细模型,以避免数据丢失的风险;
-
不去重也不聚合:与聚合模型与主键模型不同,明细模型不会对数据进行去重与聚合操作。即使两条相同的数据,每次插入时也会被完整保留;
-
灵活的数据查询:明细模型保留了全量的原始数据,可以从完整数据中提取细节,基于全量数据做任意维度的聚合操作,从而进行元数数据的审计及细粒度的分析。
使用场景
一般明细模型中的数据只进行追加,旧数据不会更新。明细模型适用于需要存储全量原始数据的场景:
- 日志存储:用于存储各类的程序操作日志,如访问日志、错误日志等。每一条数据都需要被详细记录,方便后续的审计与分析;
- 用户行为数据:在分析用户行为时,如点击数据、用户访问轨迹等,需要保留用户的详细行为,方便后续构建用户画像及对行为路径进行详细分析;
- 交易数据:在某些存储交易行为或订单数据时,交易结束时一般不会发生数据变更。明细模型适合保留这一类交易信息,不遗漏任意一笔记录,方便对交易进行精确的对账。
操作示例
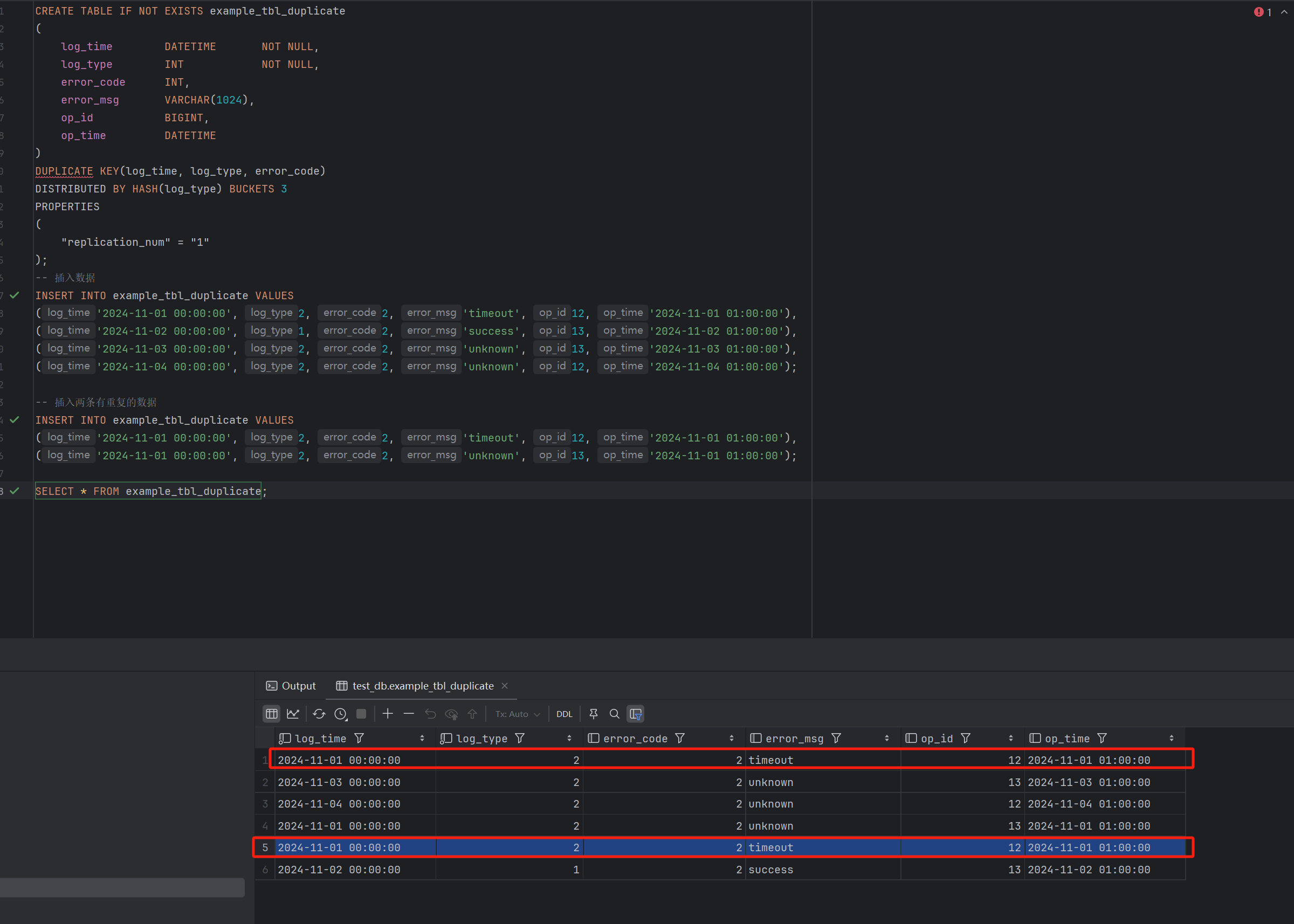
CREATE TABLE IF NOT EXISTS example_tbl_duplicate
(
log_time DATETIME NOT NULL,
log_type INT NOT NULL,
error_code INT,
error_msg VARCHAR(1024),
op_id BIGINT,
op_time DATETIME
)
DUPLICATE KEY(log_time, log_type, error_code)
DISTRIBUTED BY HASH(log_type) BUCKETS 3
PROPERTIES
(
"replication_num" = "1"
);
-- 插入数据
INSERT INTO example_tbl_duplicate VALUES
('2024-11-01 00:00:00', 2, 2, 'timeout', 12, '2024-11-01 01:00:00'),
('2024-11-02 00:00:00', 1, 2, 'success', 13, '2024-11-02 01:00:00'),
('2024-11-03 00:00:00', 2, 2, 'unknown', 13, '2024-11-03 01:00:00'),
('2024-11-04 00:00:00', 2, 2, 'unknown', 12, '2024-11-04 01:00:00');
-- 插入两条有重复的数据
INSERT INTO example_tbl_duplicate VALUES
('2024-11-01 00:00:00', 2, 2, 'timeout', 12, '2024-11-01 01:00:00'),
('2024-11-01 00:00:00', 2, 2, 'unknown', 13, '2024-11-01 01:00:00');
SELECT * FROM example_tbl_duplicate;


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











