






1.jdk环境配置
1.1 下载一个1.8版本的jdk(如果系统自带1.8版本的话 可以忽略这一条)
我提供一个官网的版本 也是我确定可以用的版本:https://www.oracle.com/cn/java/technologies/javase-jdk8-downloads.html
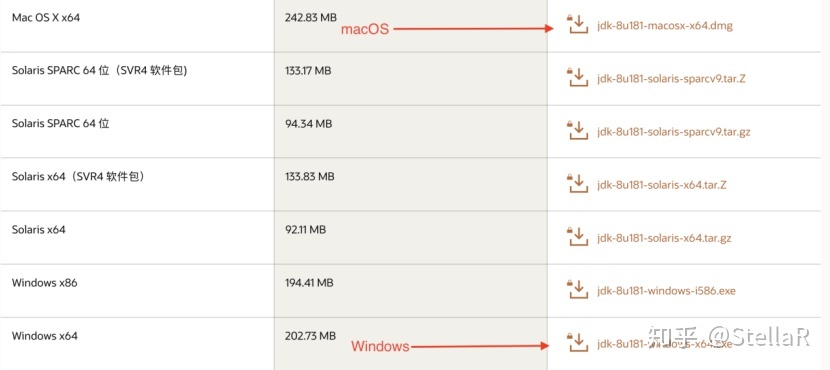
因为我所学的Hadoop只能在jdk 1.8环境下跑,进行远程连接如果jdk版本过高的话是无法成功的,所以要求ide的jdk版本与Hadoop一致 选择1.8
可以通过终端指令查看本机上的jdk版本
在terminal输入 ls /Library/Java/JavaVirtualMachines/
2.intelllij idea配置指定jdk
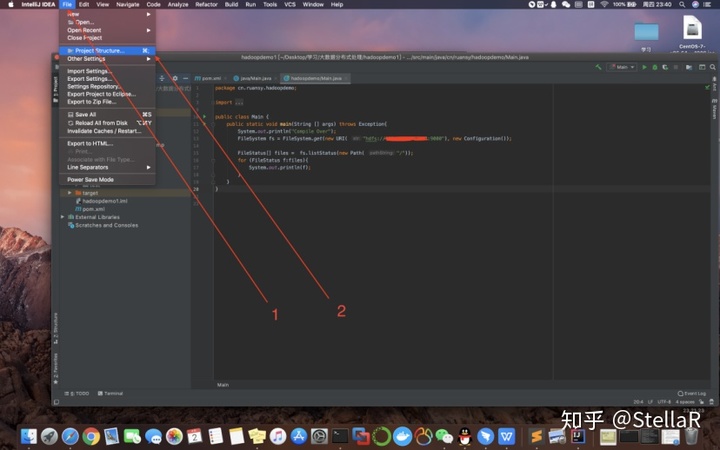
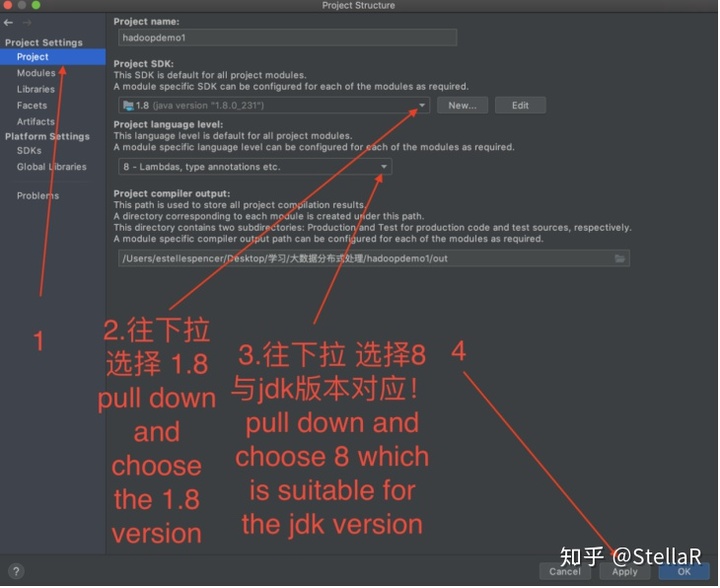
2.1 添加指定SDK
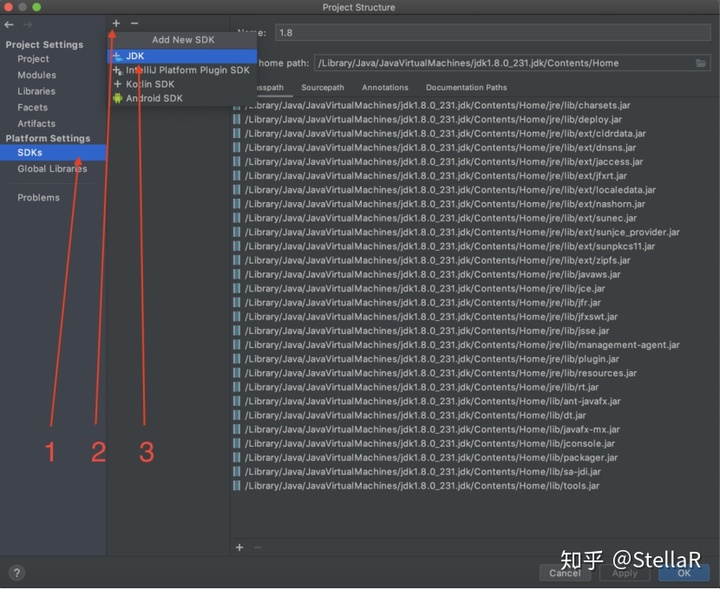
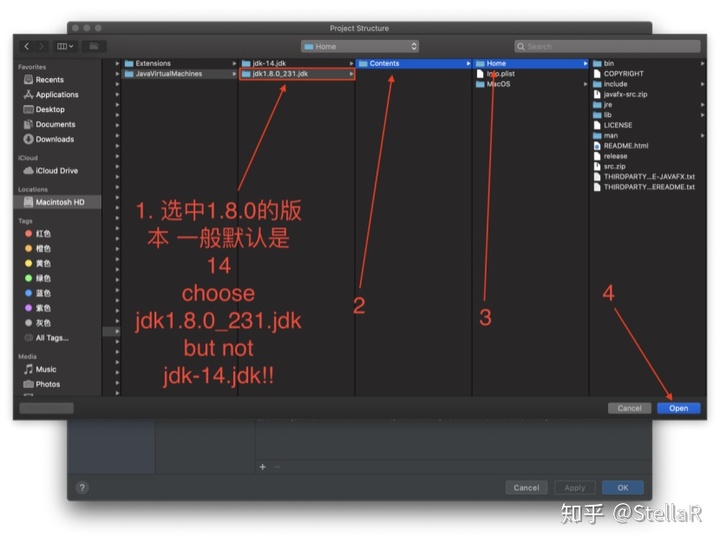
2.2 project 下的project SDK,是否为项目需要的jdk 并且language level不能比jdk版本高
3.新建项目
以下步骤参考链接:https://github.com/Philogag/blogs/blob/master/IDEA%20Hadoop%20开发环境构建.md
3.1回到最开始的界面 create a project
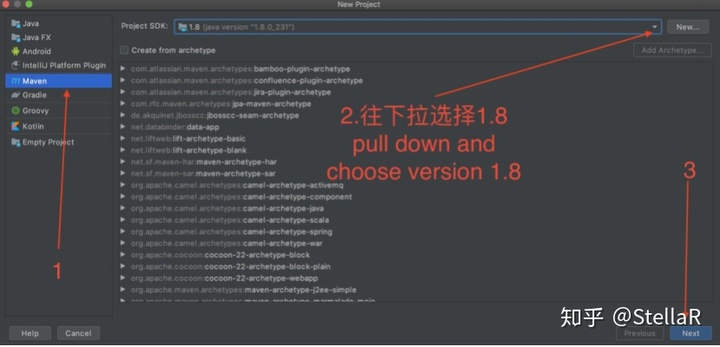
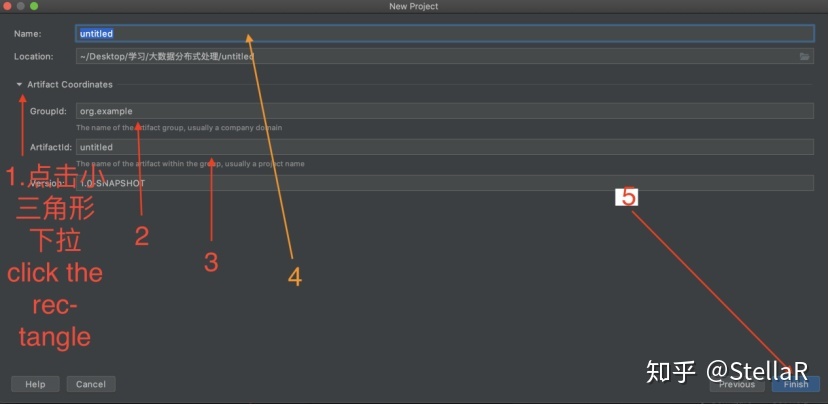
location可以自己写 找得到即可 但是最好这样子写 例如name:aaa location: ~/xxxxxxx/aaa
4.构建远程连接的环境
(先解压hadoop-2.7.1.tar.gz 可以跳过4.1直接到4.2)
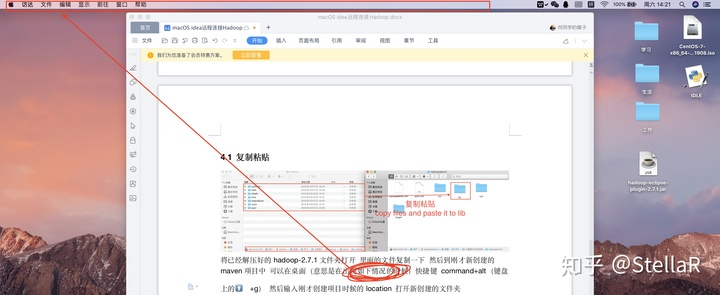
4.1 复制粘贴
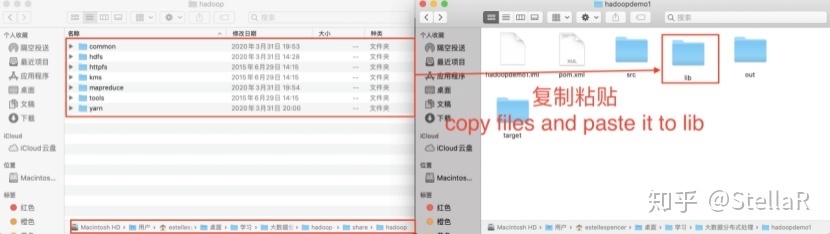
将已经解压好的hadoop-2.7.1文件夹打开 里面的文件复制一下 然后到刚才新创建的maven项目中 可以点击桌面任意空白处,出现如下情况的时候,快捷键 command+alt(键盘上的⬆️+g) 然后输入刚才创建项目时候的location 打开新创建的文件夹
4.2 导入依赖包
打开intellij idea file下面的project structure 在2.里面做过
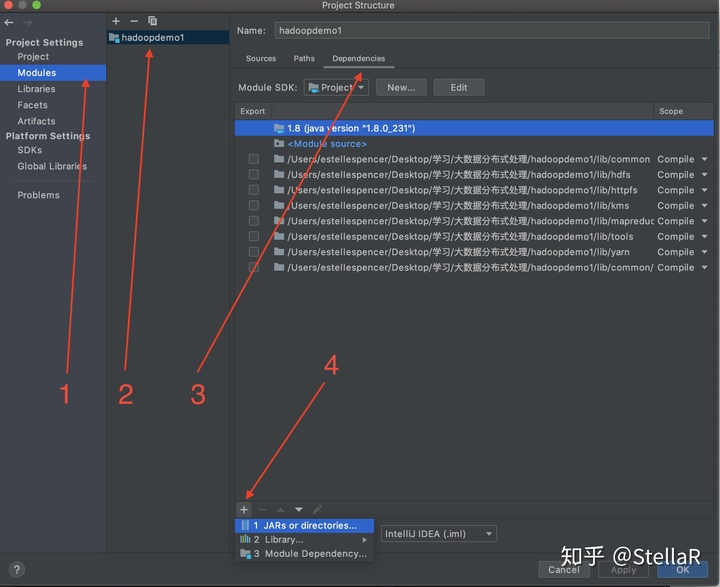
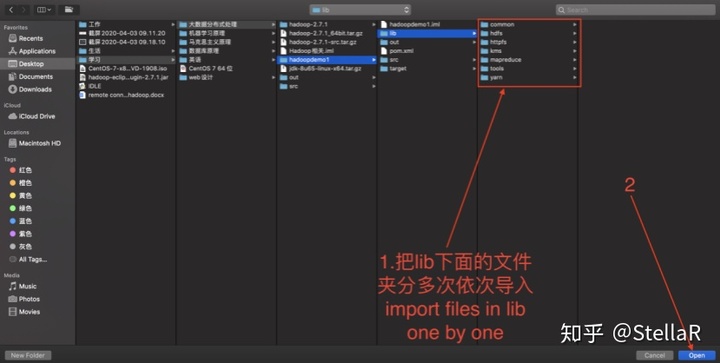
如果跳过了4.1的复制粘贴的话,这一步是到解压后的hadoop-2.7.1的目录下 hadoop-2.7.1 --> share --> hadoop 将hadoop目录下的所有文件夹依次导入 点击apply
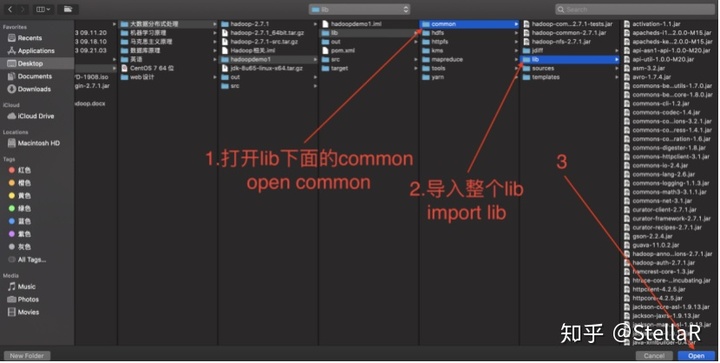
4.3 额外导入 ./common/lib文件夹 跳过了4.1的可以在 hadoop-2.7.1 --> share --> hadoop --> common 下将整个lib文件夹导入
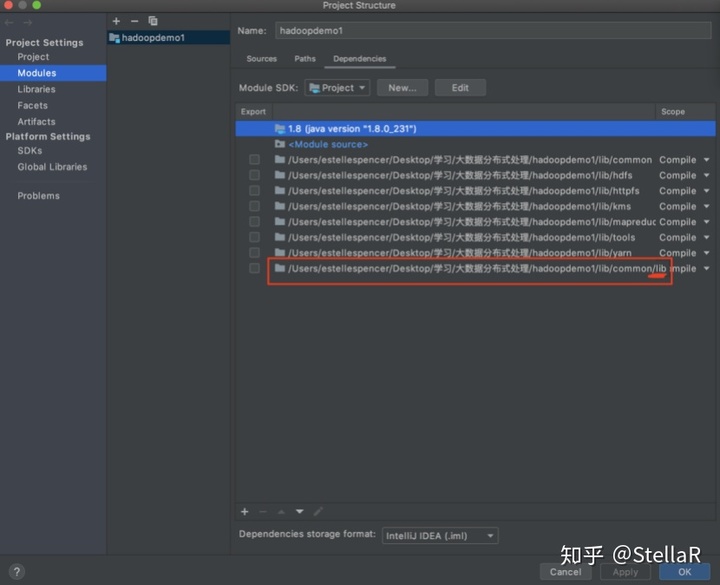
4.4 进行代码的开发(src目录下才能new 一个 java class)
(远程连接需要将Hadoop启动:打开虚拟机 输入 start-all.sh 输入jps后应有五个进程)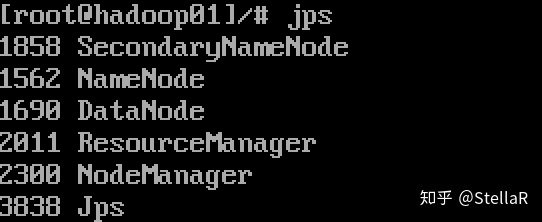
5.编译配置
File --> project structure
6.检验及一些说明
intellij idea输出的结果:
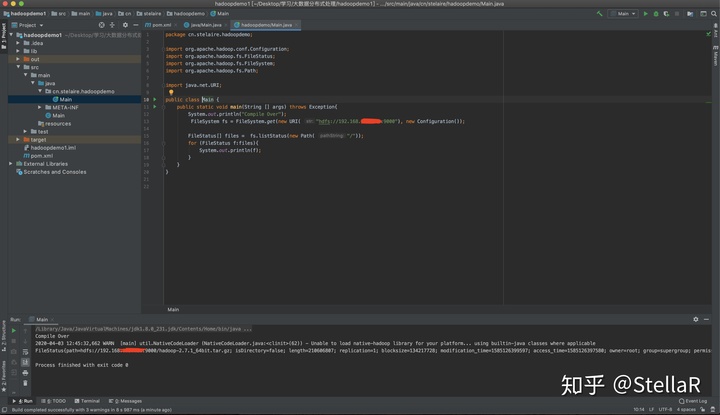
Hadoop的根目录下的内容:

两者一致 连接成功
代码如下:
public static void main(String [] args) throws Exception{
System.out.println("Compile Over");
FileSystem fs = FileSystem.get(new URI( "hdfs://hostname或者ip 我用的ip地址 :9000"), new Configuration());
FileStatus[] files = fs.listStatus(new Path( "/"));
for (FileStatus f:files){
System.out.println(f);
}如果出现红字 双击会自动导入 或者输入的时候手动选择org.apache.hadoop的
这个代码是用来输出Hadoop的根目录下面的文件与文件夹的
在Linux系统上输入指令
hadoop fs -ls /
如果没有内容的话 idea会返回compile over
有内容的话idea会返回 compile over + hadoop根目录下的内容














 1581
1581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









