






1.2.3.2.5 索引跳跃式扫描
索引跳跃式扫描(INDEX SKIP SCAN)适用于所有类型的复合B树索引(包括***性索引和非***性索引),它使那些在where条件中没有对目标索引的前导列指定查询条件但同时又对该索引的非前导列指定了查询条件的目标SQL依然可以用上该索引,这就像是在扫描该索引时跳过了它的前导列,直接从该索引的非前导列开始扫描一样(实际的执行过程并非如此),这也是索引跳跃式扫描中"跳跃"(SKIP)一词的含义。
为什么在where条件中没有对目标索引的前导列指定查询条件但Oracle依然可以用上该索引呢?这是因为Oracle帮你对该索引的前导列的所有distinct值做了遍历。
我们来看一个索引跳跃式扫描的实例。创建一个测试表EMPLOYEE:
SQL>create table employee(gender varchar2(1),employee_id number);
Table created
将该表的列EMPLOYEE_ID的属性设为NOT NULL:
SQL>alter table employee modify(employee_id not null);
Table altered
创建一个名为IDX_EMPOLYEE的复合B树索引,其中列GENDER是该索引的前导列,列EMPLOYEE_ID是该索引的第二列:
SQL>create index idx_employee on employee(gender,employee_id);
Index created
使用如下PL/SQL代码往表EMPLOYEE中插入10,000条记录,其中5,000条记录的列GENDER的值为"F",另外5,000条记录的列GENDER的值为"M":
begin
for i in 1..5000 loop
insert into employee values ('F',i);
end loop;
commit;
end;
/
begin
for i in 5001..10000 loop
insert into employee values ('M',i);
end loop;
commit;
end;
/
然后我们来看如下的范例SQL 9:
select * from employee
whereemployee_id=100;
对于范例SQL 9而言,其where条件是"employee_id = 100",即它只对复合B树索引IDX_EMPOLYEE的第二列EMPLOYEE_ID指定了查询条件,但并没有对该索引的前导列GENDER指定任何查询条件。这种情况下Oracle在执行范例SQL 9时是否能用上索引IDX_EMPOLYEE呢?
我们现在来执行范例SQL 9:
SQL>set autotrace traceonly
SQL>select * from employee whereemployee_id=100;
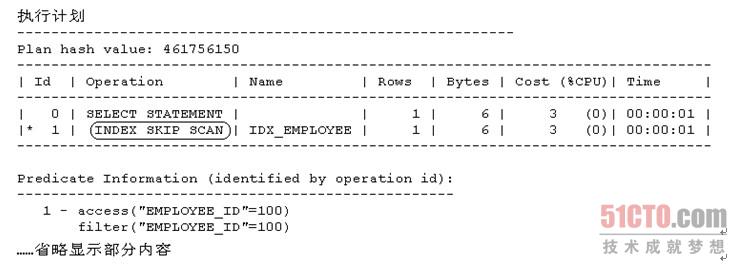
从上述显示内容可以看出,Oracle在执行范例SQL 9时已经用上了索引IDX_EMPOLYEE,并且其执行计划走的就是对该索引的索引跳跃式扫描。
这里在没有指定前导列的情况下还能用上述索引,就是因为Oracle帮我们对该索引的前导列的所有distinct值做了遍历。
所谓的对目标索引的所有distinct值做遍历,其实际含义相当于对原目标SQL做等价改写(即把要用的目标索引的所有前导列的distinct值都加进来)。索引IDX_EMPOLYEE的前导列GENDER的distinct值只有"F"和"M"两个值,所以这里能使用索引IDX_EMPOLYEE的原因可以简单地理解成是Oracle将范例SQL 9等价改写成了如下形式:
select * from employee wheregender='F'andemployee_id=100
union all
select * from employee wheregender='M'andemployee_id=100;
从上述分析过程可以看出,Oracle中的索引跳跃式扫描仅仅适用于那些目标索引前导列的distinct值数量较少、后续非前导列的可选择性又非常好的情形,因为索引跳跃式扫描的执行效率一定会随着目标索引前导列的distinct值数量的递增而递减。
【责任编辑:book TEL:(010)68476606】
点赞 0















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









