






本节引言:
前面两节我们对Android内置的Http请求方式:HttpURLConnection和HttpClient,本来以为OkHttp
已经集成进来了,然后想讲解下Okhttp的基本用法,后来发现还是要导第三方,算了,放到进阶部分
吧,而本节我们来学习下Android为我们提供的三种解析XML数据的方案!他们分别是:
SAX,DOM,PULL三种解析方式,下面我们就来对他们进行学习!
1.XML数据要点介绍
首先我们来看看XML数据的一些要求以及概念:
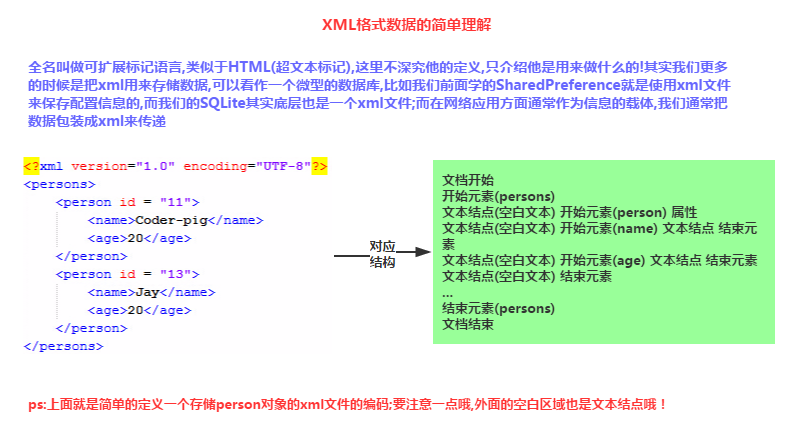
2.三种解析XML方法的比较

3.SAX解析XML数据

核心代码:
SAX解析类:SaxHelper.java:
/**
* Created by Jay on 2015/9/8 0008.
*/
public class SaxHelper extends DefaultHandler {
private Person person;
private ArrayList persons;
//当前解析的元素标签
private String tagName = null;
/**
* 当读取到文档开始标志是触发,通常在这里完成一些初始化操作
*/
@Override
public void startDocument() throws SAXException {
this.persons = new ArrayList();
Log.i("SAX", "读取到文档头,开始解析xml");
}
/**
* 读到一个开始标签时调用,第二个参数为标签名,最后一个参数为属性数组
*/
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if (localName.equals("person")) {
person = new Person();
person.setId(Integer.parseInt(attributes.getValue("id")));
Log.i("SAX", "开始处理person元素~");
}
this.tagName = localName;
}
/**
* 读到到内容,第一个参数为字符串内容,后面依次为起始位置与长度
*/
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
//判断当前标签是否有效
if (this.tagName != null) {
String data = new String(ch, start, length);
//读取标签中的内容
if (this.tagName.equals("name")) {
this.person.setName(data);
Log.i("SAX", "处理name元素内容");
} else if (this.tagName.equals("age")) {
this.person.setAge(Integer.parseInt(data));
Log.i("SAX", "处理age元素内容");
}
}
}
/**
* 处理元素结束时触发,这里将对象添加到结合中
*/
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if (localName.equals("person")) {
this.persons.add(person);
person = null;
Log.i("SAX", "处理person元素结束~");
}
this.tagName = null;
}
/**
* 读取到文档结尾时触发,
*/
@Override
public void endDocument() throws SAXException {
super.endDocument();
Log.i("SAX", "读取到文档尾,xml解析结束");
}
//获取persons集合
public ArrayList getPersons() {
return persons;
}
}
然后我们在MainActivity.java中写上写上这样一个方法,然后要解析XML的时候调用下
就好了~
private ArrayList readxmlForSAX() throws Exception {
//获取文件资源建立输入流对象
InputStream is = getAssets().open("person1.xml");
//①创建XML解析处理器
SaxHelper ss = new SaxHelper();
//②得到SAX解析工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//③创建SAX解析器
SAXParser parser = factory.newSAXParser();
//④将xml解析处理器分配给解析器,对文档进行解析,将事件发送给处理器
parser.parse(is, ss);
is.close();
return ss.getPersons();
}
一些其他的话:
嗯,对了,忘记给大家说下我们是定义下面这样一个person1.xml文件,然后放到assets目录下的!
文件内容如下:person1.xml
SAX解析
18
XML1
43
我们是把三种解析方式都糅合到一个demo中,所以最后才贴全部的效果图,这里的话,贴下打印的Log,
相信大家会对SAX解析XML流程更加明了:

另外,外面的空白文本也是文本节点哦!解析的时候也会走这些节点!
4.DOM解析XML数据

核心代码:
DomHelper.java
/**
* Created by Jay on 2015/9/8 0008.
*/
public class DomHelper {
public static ArrayList queryXML(Context context)
{
ArrayList Persons = new ArrayList();
try {
//①获得DOM解析器的工厂示例:
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
//②从Dom工厂中获得dom解析器
DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();
//③把要解析的xml文件读入Dom解析器
Document doc = dbBuilder.parse(context.getAssets().open("person2.xml"));
System.out.println("处理该文档的DomImplemention对象=" + doc.getImplementation());
//④得到文档中名称为person的元素的结点列表
NodeList nList = doc.getElementsByTagName("person");
//⑤遍历该集合,显示集合中的元素以及子元素的名字
for(int i = 0;i < nList.getLength();i++)
{
//先从Person元素开始解析
Element personElement = (Element) nList.item(i);
Person p = new Person();
p.setId(Integer.valueOf(personElement.getAttribute("id")));
//获取person下的name和age的Note集合
NodeList childNoList = personElement.getChildNodes();
for(int j = 0;j < childNoList.getLength();j++)
{
Node childNode = childNoList.item(j);
//判断子note类型是否为元素Note
if(childNode.getNodeType() == Node.ELEMENT_NODE)
{
Element childElement = (Element) childNode;
if("name".equals(childElement.getNodeName()))
p.setName(childElement.getFirstChild().getNodeValue());
else if("age".equals(childElement.getNodeName()))
p.setAge(Integer.valueOf(childElement.getFirstChild().getNodeValue()));
}
}
Persons.add(p);
}
} catch (Exception e) {e.printStackTrace();}
return Persons;
}
}
代码分析:
从代码我们就可以看出DOM解析XML的流程,先整个文件读入Dom解析器,然后形成一棵树,
然后我们可以遍历节点列表获取我们需要的数据!
5.PULL解析XML数据

使用PULL解析XML数据的流程:

核心代码:
public static ArrayList getPersons(InputStream xml)throws Exception
{
//XmlPullParserFactory pullPaser = XmlPullParserFactory.newInstance();
ArrayList persons = null;
Person person = null;
// 创建一个xml解析的工厂
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
// 获得xml解析类的引用
XmlPullParser parser = factory.newPullParser();
parser.setInput(xml, "UTF-8");
// 获得事件的类型
int eventType = parser.getEventType();
while (eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
case XmlPullParser.START_DOCUMENT:
persons = new ArrayList();
break;
case XmlPullParser.START_TAG:
if ("person".equals(parser.getName())) {
person = new Person();
// 取出属性值
int id = Integer.parseInt(parser.getAttributeValue(0));
person.setId(id);
} else if ("name".equals(parser.getName())) {
String name = parser.nextText();// 获取该节点的内容
person.setName(name);
} else if ("age".equals(parser.getName())) {
int age = Integer.parseInt(parser.nextText());
person.setAge(age);
}
break;
case XmlPullParser.END_TAG:
if ("person".equals(parser.getName())) {
persons.add(person);
person = null;
}
break;
}
eventType = parser.next();
}
return persons;
}
使用Pull生成xml数据的流程:

核心代码:
public static void save(List persons, OutputStream out) throws Exception {
XmlSerializer serializer = Xml.newSerializer();
serializer.setOutput(out, "UTF-8");
serializer.startDocument("UTF-8", true);
serializer.startTag(null, "persons");
for (Person p : persons) {
serializer.startTag(null, "person");
serializer.attribute(null, "id", p.getId() + "");
serializer.startTag(null, "name");
serializer.text(p.getName());
serializer.endTag(null, "name");
serializer.startTag(null, "age");
serializer.text(p.getAge() + "");
serializer.endTag(null, "age");
serializer.endTag(null, "person");
}
serializer.endTag(null, "persons");
serializer.endDocument();
out.flush();
out.close();
}
6.代码示例下载:
运行效果图:

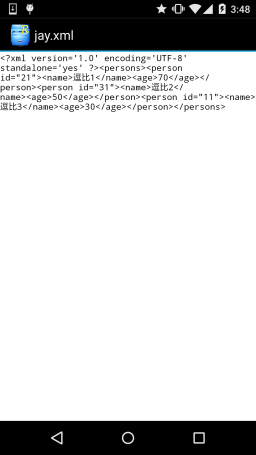
代码下载:
XMLParseDemo.zip:下载 XMLParseDemo.zip
本节小结:
本节介绍了Android中三种常用的XML解析方式,DOM,SAX和PULL,移动端我们建议用后面这
两种,而PULL用起来更加简单,这里就不多说了,代码是最好的老师~本节就到这里,下节我们
来学习Android为我们提供的扣脚Json解析方式!谢谢~















 152
152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









