







简介:数据结构在信息学竞赛中占据核心地位,特别是树这一非线性数据结构,在NOIP等比赛中对成绩影响重大。本课件专注于树的数据结构,涵盖树的基本概念、二叉树、平衡二叉树、堆以及树的遍历、链接表示法、存储和运算等关键知识点。通过学习这些内容,参赛者能够加深对树结构的理解,并在实际问题解决中更有效地运用树的算法和概念。 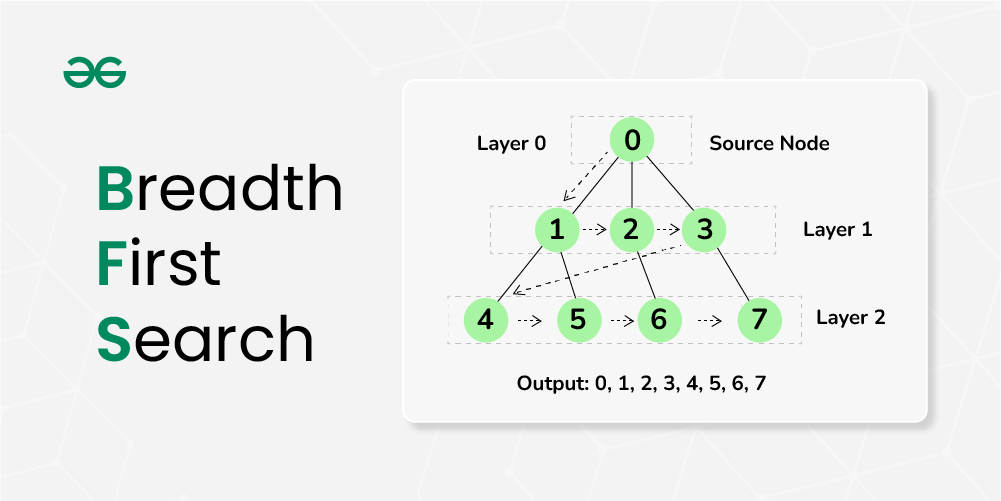
1. 数据结构在NOIP中的重要性
数据结构是计算机存储、组织数据的方式,使得数据可以更高效地被访问和修改。在NOIP(全国青少年信息学奥林匹克竞赛)中,数据结构的应用同样至关重要,它是解题的基础和关键。
数据结构与算法效率
在NOIP中,面对复杂的编程问题,选择合适的数据结构可以显著提高算法效率。例如,使用数组和链表可以优化数据存取速度,而哈希表则可以实现近乎常数时间复杂度的查找效率。
数据结构在实际问题中的应用
数据结构不仅对于基础算法实现至关重要,它也直接关系到能否高效地解决实际问题。如树状结构可用来表示组织关系,图结构可用来处理网络问题等。NOIP中的很多问题,实际上是对各种数据结构理解和应用的综合考查。
因此,掌握数据结构的核心概念、原理及其在算法中的应用,是NOIP备考过程中的基础环节,也是区分优秀选手与普通选手的关键所在。
2. 树的基本概念和术语
2.1 树的定义和特性
2.1.1 树的定义
树(Tree)是一种被广泛应用于计算机科学中的非线性数据结构,它由一组节点(Node)和连接节点之间的边(Edge)组成,模拟了一种层次关系。在树形结构中,一个节点可能有多个子节点,但只能有一个父节点,而根节点(Root)是树中的唯一没有父节点的节点。树的深度(Depth)是从根节点到任意节点的最长路径的边数。树的层级(Level)是指节点所在的深度加一。
2.1.2 树的基本术语和性质
在树的基本概念中,还有一些关键术语需要理解:
- 子树(Subtree) :任何一个节点及其后代节点构成的树。
- 叶节点(Leaf Node) :没有子节点的节点,也称为终端节点。
- 度(Degree) :节点拥有的子节点的数量。
- 路径(Path) :一系列节点按照连接顺序排列形成的一个序列,路径上的节点数称为路径长度。
- 分支节点(Internal Node) :至少有一个子节点的非根节点。
- 树的高度(Height) :树中所有节点的最大深度。
树的性质包括:
- 性质1 :树中的节点数等于边数加一。
- 性质2 :如果一个树有n个节点,那么它有n-1条边。
- 性质3 :在任何非空树中,至少有两个叶子节点。
2.2 树的不同形态
2.2.1 有根树与无根树
在树的分类中,最基本的区别是节点是否有指明的父节点,由此分为有根树和无根树。
-
有根树(Rooted Tree) :每个节点都有一个明确的父节点,从而定义了唯一的根节点。在有根树中,从根到任何节点都存在唯一的路径。有根树常用于表示家族谱系、公司组织结构等。
-
无根树(Unrooted Tree) :没有特别指定根节点的树,任意节点都可能作为其他节点的父节点。无根树常用于网络结构、社交网络等场景。
2.2.2 森林和树的关系
森林(Forest)是树的一种推广,是由多棵不相交的树组成的集合。在森林中,每个树都有自己的根,但整个森林没有统一的根节点。
- 树转换为森林 :给定一棵树,移除任意一条边,就可以得到一个森林,该森林包含两棵子树。
- 森林转换为树 :给定一个森林,添加一条边连接任意两个不相交的树的根,可以得到一棵树。
森林和树之间的转换关系在图论算法中非常有用,例如,在处理网络连接或路径查找问题时,通过将问题在森林和树之间转换,可以简化复杂度。
3. 二叉树及遍历方法
3.1 二叉树的概念和性质
3.1.1 二叉树的定义和特点
二叉树是每个节点最多有两个子树的树结构,通常子树被称作“左子树”和“右子树”。二叉树在数据结构中占据着举足轻重的地位,特别是在算法竞赛和实际应用中,因为它们的结构易于理解和操作,二叉树被广泛应用于搜索、排序和优先队列等场景。二叉树的这些性质在NOIP竞赛中也是考察的重点。
二叉树的节点包含一个数据元素和两个指向其子节点的引用(或指针)。若将二叉树的层级数定义为树的深度,那么一个深度为k的完全二叉树包含最大数量的节点,即为2^k - 1个节点。这种高度平衡的性质让二叉树在进行各种遍历操作时,既有效率也容易实现。
3.1.2 完全二叉树和满二叉树
完全二叉树是一种特殊的二叉树,其中每一个节点都拥有0或2个子节点,且最后一层从左到右填充节点,除了最后一层外,其它各层的节点数都达到最大值,并且最后一层的节点都尽可能地向左填充。在数据结构和算法中,堆是一种特殊的完全二叉树,常用于实现优先队列。
满二叉树是另一种特殊的二叉树,每一个节点都有两个子节点,也就是说每一层都是满的。满二叉树的节点总数是 2^k - 1,其中k是树的深度。满二叉树是完全二叉树的一个特例。
3.1.3 二叉树的层次结构
二叉树的节点通常可以通过层次编号来进行标识。层次编号从1开始,根节点为第一层(深度为1),其子节点为第二层(深度为2),以此类推。层次编号有助于理解和实现树的遍历算法,以及确定节点的深度和高度。
3.2 二叉树的遍历算法
3.2.1 前序遍历
前序遍历是一种深度优先遍历算法,对二叉树的每个节点按照“根-左-右”的顺序进行访问。对于树中的任意节点,首先访问该节点,然后递归地进行前序遍历其左子树,接着递归地进行前序遍历其右子树。前序遍历的特点是首先处理根节点,这使得它非常适合于处理需要先访问节点的情况。
def preorder_traversal(root):
if root is None:
return
# 访问根节点
print(root.value)
# 前序遍历左子树
preorder_traversal(root.left)
# 前序遍历右子树
preorder_traversal(root.right)
3.2.2 中序遍历
中序遍历也是一种深度优先遍历算法,按照“左-根-右”的顺序访问二叉树的每个节点。在中序遍历中,节点的左子树会首先被访问,然后是节点本身,最后是其右子树。中序遍历在二叉搜索树中特别重要,因为它能以排序的顺序访问所有节点。
def inorder_traversal(root):
if root is None:
return
# 中序遍历左子树
inorder_traversal(root.left)
# 访问根节点
print(root.value)
# 中序遍历右子树
inorder_traversal(root.right)
3.2.3 后序遍历
后序遍历是深度优先遍历的另一种方式,按照“左-右-根”的顺序访问二叉树的每个节点。在后序遍历中,节点的左右子树会被先访问,然后才是节点本身。后序遍历对于一些特定的问题,如删除整棵树,非常有用,因为它确保了在处理任何节点之前,所有子节点都被处理了。
def postorder_traversal(root):
if root is None:
return
# 后序遍历左子树
postorder_traversal(root.left)
# 后序遍历右子树
postorder_traversal(root.right)
# 访问根节点
print(root.value)
3.2.4 遍历方法的选择与应用
每种遍历方法都有其独特的应用场景。在实际编程中,选择正确的遍历算法对于解决特定问题至关重要。例如,对数据进行排序或获取有序序列时,中序遍历通常是首选,因为它能够按顺序访问树中的所有节点。而在需要在删除树中的节点之前访问所有子节点时,后序遍历则更加适合。
理解了二叉树的基本概念和性质后,通过前序、中序、后序三种遍历方式,我们可以解决一系列与二叉树相关的算法问题,这些都将为理解后续的特殊二叉树如二叉搜索树和自平衡二叉树打下坚实的基础。
4. 特殊二叉树:二叉搜索树
4.1 二叉搜索树的概念
4.1.1 二叉搜索树的定义
二叉搜索树(Binary Search Tree,BST)是二叉树的一种特殊形式,它满足以下性质:
- 每个节点的值都大于其左子树中任意节点的值;
- 每个节点的值都小于其右子树中任意节点的值;
- 左、右子树也分别为二叉搜索树。
这种树结构的设计使得数据在树中的查找、插入和删除操作更加高效,平均时间复杂度为O(log n)。
4.1.2 二叉搜索树的性质
二叉搜索树的性质决定了它的基本操作,如插入、删除和搜索可以在对数时间内完成。关键性质包括:
- 对于任何给定的节点,其左子树的所有节点值均小于该节点值,右子树的所有节点值均大于该节点值;
- 二叉搜索树的中序遍历结果为有序序列。
4.2 二叉搜索树的操作
4.2.1 插入与删除节点
在二叉搜索树中插入和删除节点需要维护其性质,操作较为复杂。
插入操作
插入节点时,从根节点开始,若插入值小于当前节点值,则递归地移动到左子节点;若插入值大于当前节点值,则移动到右子节点。重复此过程直到遇到空位,然后插入新节点。
class TreeNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
def insert(root, value):
if root is None:
return TreeNode(value)
else:
if value < root.value:
root.left = insert(root.left, value)
elif value > root.value:
root.right = insert(root.right, value)
return root
删除操作
删除节点稍微复杂,因为要处理三种情况:
- 被删除节点是叶子节点:可以直接删除;
- 被删除节点只有一个子节点:可以用子节点替换被删除节点;
- 被删除节点有两个子节点:找到其右子树中的最小节点或左子树中的最大节点,用以替换被删除节点,然后删除那个最小或最大节点。
def find_min(node):
while node.left is not None:
node = node.left
return node
def delete_node(root, value):
if root is None:
return root
if value < root.value:
root.left = delete_node(root.left, value)
elif value > root.value:
root.right = delete_node(root.right, value)
else:
if root.left is None:
temp = root.right
root = None
return temp
elif root.right is None:
temp = root.left
root = None
return temp
temp = find_min(root.right)
root.value = temp.value
root.right = delete_node(root.right, temp.value)
return root
4.2.2 查找节点和区间查询
查找节点
在二叉搜索树中查找一个值是高效的。从根节点开始,如果目标值大于当前节点值,移动到右子节点;如果小于当前节点值,移动到左子节点。重复此过程直到找到该值或达到叶子节点。
def search(root, value):
if root is None or root.value == value:
return root
if value < root.value:
return search(root.left, value)
return search(root.right, value)
区间查询
二叉搜索树的区间查询可以利用其性质递归地进行。查询一个值范围内的所有节点,可以通过遍历符合条件的节点来实现。
def range_query(root, low, high):
result = []
if root is None:
return result
if low <= root.value <= high:
result.append(root.value)
result.extend(range_query(root.left, low, high))
result.extend(range_query(root.right, low, high))
elif root.value > low:
result.extend(range_query(root.left, low, high))
elif root.value < high:
result.extend(range_query(root.right, low, high))
return result
二叉搜索树的这些操作让其在许多算法和数据处理场景中非常有用,特别是在需要高效数据检索的应用中。
5. 自平衡二叉树:AVL树和红黑树
在数据结构的世界中,自平衡二叉树是一种十分重要的数据结构。它们保证了树的操作,比如插入和删除,能够以最优的时间复杂度运行。自平衡二叉树通过调整树的形态来保持平衡,从而使得查找操作的效率得以提高。在本章节中,我们将深入了解两种最著名的自平衡二叉搜索树:AVL树和红黑树。这两种树通过不同的方式达到平衡,并且各自在不同的场景中表现出色。
5.1 AVL树的原理和实现
AVL树是最早被发明的自平衡二叉搜索树,其命名来源于它的发明者Adelson-Velsky和Landis的缩写。AVL树具有以下特性:
- AVL树是一种二叉搜索树。
- 任何节点的两个子树的高度最大差别为1,这也被称为平衡因子。
- 它保证了树的平衡性,从而在最坏情况下依然能够以O(log n)的时间复杂度执行查找、插入和删除操作。
5.1.1 AVL树的定义和平衡条件
AVL树的定义和普通二叉搜索树类似,它是一种特殊的二叉搜索树。AVL树的核心在于它的平衡条件。为了描述这个条件,我们引入了平衡因子的概念。平衡因子指的是任何一个节点的左子树高度减去右子树高度的结果。在AVL树中,任何节点的平衡因子只可能是-1、0、1这三个值。
5.1.2 AVL树的旋转操作
为了维持AVL树的平衡性,每当进行插入或删除操作导致平衡因子超过1或者小于-1时,需要执行旋转操作。有四种基本旋转操作:
- 单旋转(LL和RR):当在右子树插入新节点导致左侧不平衡时,执行单旋转。
- 双旋转(LR和RL):当在右子树的左子树插入新节点导致左侧不平衡时,执行双旋转。
下面是一个单旋转(RR旋转)的示例代码,通过旋转操作恢复树的平衡性:
class TreeNode:
def __init__(self, key, left=None, right=None):
self.key = key
self.left = left
self.right = right
self.height = 1
def right_rotate(y):
# y是右子树上的节点
x = y.left
T2 = x.right
# 执行右旋转
x.right = y
y.left = T2
# 更新高度
y.height = max(get_height(y.left), get_height(y.right)) + 1
x.height = max(get_height(x.left), get_height(x.right)) + 1
return x
def get_height(node):
if not node:
return 0
return node.height
在这段代码中, right_rotate 函数表示RR旋转。需要注意的是,旋转操作后需要更新各个节点的高度,因为AVL树的平衡性依赖于节点的高度。
5.2 红黑树的原理和实现
红黑树同样是一种自平衡二叉搜索树,它通过保持树的平衡性来保证操作的效率。红黑树的平衡性不像AVL树那样严格,但其平衡操作更简单高效。红黑树的特性如下:
- 节点要么是红色要么是黑色。
- 根节点总是黑色。
- 所有叶子节点(NIL节点,空节点)都是黑色。
- 如果一个节点是红色,那么它的两个子节点都是黑色(即不存在连续的红色节点)。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
5.2.1 红黑树的定义和性质
红黑树的定义确保了它在进行插入和删除操作时,树的平衡性能够快速恢复。这些性质保证了最长路径不会超过最短路径的两倍,从而保证了红黑树的最坏情况下操作的时间复杂度是O(log n)。
5.2.2 红黑树的调整操作
红黑树的调整操作涉及颜色变换和树旋转。当插入或删除节点导致违背红黑树性质时,通过以下两种基本操作来调整:
- 左旋:左旋某个节点,使得该节点成为其右子节点的父亲,其右子节点成为该节点的父亲。
- 右旋:右旋某个节点,使得该节点成为其左子节点的父亲,其左子节点成为该节点的父亲。
- 颜色变换:改变节点的颜色,或者改变其父节点和兄弟节点的颜色。
下面是一个红黑树左旋操作的示例代码:
def left_rotate(x):
# x是需要进行左旋的节点
y = x.right
x.right = y.left
if y.left:
y.left.parent = x
y.parent = x.parent
if not x.parent:
root = y
elif x == x.parent.left:
x.parent.left = y
else:
x.parent.right = y
y.left = x
x.parent = y
在这段代码中, left_rotate 函数表示对节点x进行左旋。旋转操作后,需要更新节点的父节点关系以保持二叉搜索树的性质。
表格、mermaid流程图和代码块的综合展示
为了更加直观地展示红黑树调整操作的过程,我们可以使用表格和流程图来描述左旋操作中节点关系的变化:
| 操作前 | 操作后 | |--------|--------| | x.parent = p
x.right = y
y.left = t
y.parent = x
t.parent = y | x.parent = y
y.left = x
y.right = t
p.left = y
y.right = x.parent |
graph TD
p[ ] -->|left| x[x]
x -->|right| y[y]
y -->|left| t[t]
y -->|parent| x
x -->|parent| p
p -->|right| t
%% 操作后
x -->|parent| y
y -->|left| x
x -->|right| t
y -->|parent| p
p -->|left| y
y -->|right| x
通过上述表格和mermaid流程图,我们能够清晰地看到节点在左旋操作中的具体变化。这些辅助性的视觉元素在讲解复杂的概念时尤其有用。
在处理红黑树的调整操作时,代码块后必须给出逻辑分析,同时解释代码如何调整节点颜色和子节点指针。例如,在左旋操作之后,我们需要更新x节点和y节点的父节点关系,并重新分配它们的子节点。只有这样,我们才能确保树的平衡性得到维护。
总结来说,AVL树和红黑树都是优秀的自平衡二叉搜索树,它们通过各自不同的方式来保证树的平衡性。AVL树的严格平衡保证了操作的高度效率,而红黑树则在维护平衡的同时提供了更快的插入和删除操作。理解这些树的平衡原理和实现细节,对于掌握高级数据结构和算法至关重要。
6. 树的高级应用和遍历技巧
6.1 树的高级应用
6.1.1 最小生成树
最小生成树(MST)是一个在加权连通图中,选取的边构成的一个无环子集,它包括图中的所有顶点,并且边的权值之和最小。它广泛应用于网络设计、电路设计等领域。
例如,假设有如下的边集和权重:
(AB, 2), (AC, 3), (AD, 1), (BD, 4), (CD, 5), (BE, 3), (CE, 3)
对于这样的一个图,我们可以用Kruskal算法或Prim算法来找到最小生成树。下面给出使用Kruskal算法的一个简单代码示例:
# Kruskal's Algorithm to find Minimum Spanning Tree
class Graph:
def __init__(self, vertices):
self.V = vertices
self.graph = []
def addEdge(self, u, v, w):
self.graph.append([u, v, w])
def find(self, parent, i):
if parent[i] == -1:
return i
return self.find(parent, parent[i])
def applyKruskal(self):
e = len(self.graph)
self.graph = sorted(self.graph, key=lambda item: item[2])
parent = [-1]*(self.V)
result = []
edges = 0
for e in self.graph:
u, v, w = e
u_root = self.find(parent, u)
v_root = self.find(parent, v)
if u_root != v_root:
edges += 1
result.append(e)
parent[u_root] = v_root
if edges == self.V - 1:
break
for e in result:
print(f"{e[0]} - {e[1]} == {e[2]}")
# Graph initialization with vertices and edges
g = Graph(4)
g.addEdge(0, 1, 10)
g.addEdge(0, 2, 6)
g.addEdge(0, 3, 5)
g.addEdge(1, 3, 15)
g.addEdge(2, 3, 4)
# Applying Kruskal's algorithm to find Minimum Spanning Tree
g.applyKruskal()
执行上述代码会输出最小生成树的边和权重。
6.1.2 拓扑排序
在有向无环图(DAG)中,拓扑排序是将顶点排成一个线性序列,使得对任何一条有向边(u, v),顶点u都在顶点v之前。拓扑排序在项目管理和任务调度中非常有用。
假设有向图顶点表示活动,边表示活动间的依赖关系。例如:
A -> B, A -> C, B -> D, C -> D, C -> E
拓扑排序算法可使用Kahn算法或者深度优先搜索(DFS)来实现。以下是一个使用DFS进行拓扑排序的代码示例:
# A DFS based function used by topologicalSort
def DFSUtil(v, visited, stack):
visited[v] = True
# Recur for all the vertices adjacent to this vertex
for i in graph[v]:
if not visited[i]:
DFSUtil(i, visited, stack)
# All vertices reachable from v are processed by now, push v to stack
stack.insert(0, v)
# Function that returns topological sorting of the vertices of the graph
def topologicalSort():
visited = [False] * V
stack = []
# Call the recursive helper function to store Topological Sort starting from all
# vertices one by one
for i in range(V):
if not visited[i]:
DFSUtil(i, visited, stack)
# Print contents of the stack
print(stack)
# Example usage
graph = [[0, 0, 0, 1], [1, 0, 1, 1], [0, 0, 0, 1], [0, 0, 0, 0]]
V = 4
topologicalSort()
执行上述代码会得到一个顶点的拓扑排序。
6.2 树的遍历技巧
6.2.1 层次遍历
层次遍历(也称为广度优先搜索,BFS)是按层次从上到下、从左到右遍历树的节点。这种遍历方式常用于查找最短路径、层级结构的分析等。
下面是一个层次遍历二叉树的Python示例代码:
from collections import deque
class Node:
def __init__(self, value):
self.data = value
self.left = None
self.right = None
def层次遍历(root):
if not root:
return
queue = deque()
queue.append(root)
while queue:
curr = queue.popleft()
print(curr.data, end=' ')
if curr.left:
queue.append(curr.left)
if curr.right:
queue.append(curr.right)
# 构建一个简单的二叉树进行测试
root = Node(1)
root.left = Node(2)
root.right = Node(3)
root.left.left = Node(4)
root.left.right = Node(5)
层次遍历(root)
输出结果将是:
1 2 3 4 5
6.2.2 深度优先搜索(DFS)
深度优先搜索(DFS)是一种用于遍历或搜索树或图的算法。在树中,通常是从根节点开始,尽可能深的搜索树的分支,当节点v的所在边都已被探寻过,搜索将回溯到发现节点v的那条边的起始节点。
下面是一个使用递归进行深度优先搜索的示例代码:
class Node:
def __init__(self, value):
self.data = value
self.left = None
self.right = None
def DFS(node):
if node is None:
return
print(node.data, end=' ')
DFS(node.left)
DFS(node.right)
root = Node(1)
root.left = Node(2)
root.right = Node(3)
root.left.left = Node(4)
root.left.right = Node(5)
DFS(root)
输出结果将是:
1 2 4 5 3
深度优先搜索常用于解决图的遍历、路径查找、拓扑排序等问题。此外,在二叉树中,深度优先搜索也经常被用于获取先序、中序和后序遍历结果。
以上就是树的高级应用和遍历技巧。通过这些例子,我们展示了树结构在解决复杂问题中的强大应用,以及如何通过层次遍历和深度优先搜索方法来高效地遍历树。
简介:数据结构在信息学竞赛中占据核心地位,特别是树这一非线性数据结构,在NOIP等比赛中对成绩影响重大。本课件专注于树的数据结构,涵盖树的基本概念、二叉树、平衡二叉树、堆以及树的遍历、链接表示法、存储和运算等关键知识点。通过学习这些内容,参赛者能够加深对树结构的理解,并在实际问题解决中更有效地运用树的算法和概念。















 6109
6109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









