







简介:本文深入探讨了在Linux环境下Java编程的基础知识,包括变量、关键字以及MyEclipse集成开发环境的快捷键。同时,也详细讲解了Java方法的使用,如方法的分类、重载和重写等概念。熟练掌握这些技能对于Java开发者至关重要。 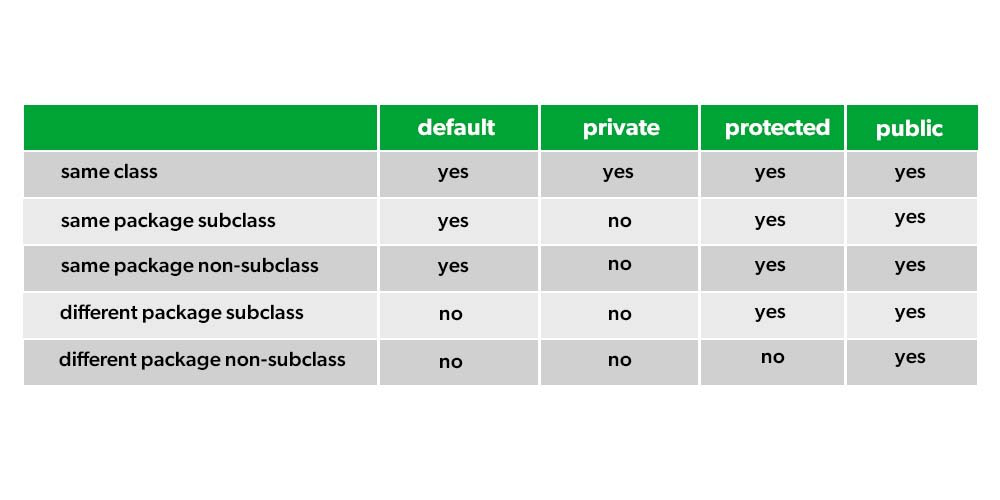
1. Linux环境下Java变量和关键字
1.1 Java变量的基本概念与作用
Java中的变量是存储信息的容器。它们拥有类型,决定了变量能够存储的数据类型,以及它们占用的内存大小。
1.1.1 变量的定义及其作用域
在Java中定义变量需要指定类型、名称和值(可选)。例如 int number = 10; 定义了一个名为 number 的整型变量,并将其初始化为10。
变量的作用域是指变量能够被访问的代码范围。局部变量在其定义的块(如方法或循环)内可见,类变量(静态变量)则在整个类中可见。
1.1.2 变量的数据类型和内存分配
Java有两大类数据类型:基本数据类型(int, long, double等)和引用数据类型(类、接口、数组)。基本类型直接存储数值,而引用类型存储的是指向对象的引用。
内存分配依赖于变量的位置。例如,实例变量属于对象的一部分,类变量属于类,局部变量则在栈上分配。
1.2 Java关键字的理解与应用
Java关键字是预定义的保留字,具有特殊意义和用途,不能用作变量名、类名或方法名。
1.2.1 关键字的分类与特性
常见的关键字包括 class , public , static , final , return 等。它们可以分为访问修饰符、控制流关键字、类相关关键字等。
1.2.2 关键字在代码中的作用和限制
关键字在代码中用来控制程序的流程,如循环、条件分支、方法调用等。某些关键字有严格的使用限制,例如 final 关键字可以用来声明一个变量为常量,或一个方法不能被子类重写。
1.3 Linux环境下的Java变量作用域分析
Linux环境下的Java开发与Windows或macOS上无异,Java程序运行在JVM中,不受宿主操作系统的直接限制。
1.3.1 局部变量与类变量的区别
在Linux环境下,局部变量和类变量的作用域和生命周期规则与在其他操作系统中相同。局部变量在方法调用时创建,在方法结束时销毁。类变量随类的加载而初始化,生命周期与类相同。
1.3.2 静态变量和实例变量在Linux下的表现
静态变量属于类,因此在Linux下也只会在类加载时初始化一次,并且为所有实例共享。实例变量属于对象实例,每个对象都有自己的副本,与操作系统的环境无关。
以上就是Linux环境下Java变量和关键字的基本介绍和特性分析。掌握这些概念对于编写可移植且健壮的Java程序至关重要。
2. MyEclipse快捷键操作指南
2.1 MyEclipse中的基本编辑快捷键
在软件开发中,提高编码效率是每个开发者追求的目标。使用快捷键可以大大加快开发速度,减少重复性劳动。MyEclipse作为一个功能强大的集成开发环境(IDE),提供了一系列快捷键帮助开发者提高工作效率。下面将详细介绍MyEclipse中的基本编辑快捷键以及它们的应用。
2.1.1 常用代码编辑快捷操作
MyEclipse支持多种快捷键来完成代码的快速编辑,以下是一些在日常开发中使用频率较高的快捷键:
- Ctrl + Space :自动补全代码提示。在代码编辑中,当输入某个类名或者方法名的一部分后按下此快捷键,IDE会自动给出代码补全的建议。
- Ctrl + Z :撤销上一步操作。这是一个非常实用的快捷键,可以快速撤销错误操作,回到上一个正确的状态。
- Ctrl + Y :重做上一步被撤销的操作。
- Ctrl + / :单行注释。选中一行或多行代码后,使用该快捷键可以快速添加或移除单行注释。
- Ctrl + Shift + / :多行注释。与单行注释类似,但是用于多行代码。
- Alt + Shift + S :快速生成getter/setter、toString等方法。
代码块示例:
// 示例代码
public class MySample {
private int exampleVariable;
public int getExampleVariable() {
return exampleVariable;
}
public void setExampleVariable(int exampleVariable) {
this.exampleVariable = exampleVariable;
}
@Override
public String toString() {
return "MySample{" +
"exampleVariable=" + exampleVariable +
'}';
}
}
2.1.2 代码格式化与重构的快捷键
MyEclipse还提供了用于格式化代码和重构代码的快捷键,这些操作是保持代码整洁和优化代码结构的重要步骤。
- Ctrl + Shift + F :代码格式化。当代码结构混乱或者格式不统一时,使用此快捷键可以快速将代码格式化为一致的风格。
- Alt + Shift + R :重命名。选中需要重命名的代码(如变量名、方法名等),然后使用此快捷键可以快速批量替换所有引用。
- Alt + Shift + M :提取方法。选中某段代码,然后按此快捷键可以快速将其提取为一个新的方法,这样不仅代码更清晰,也便于复用。
代码块示例:
// 示例代码,提取方法后的样子
public class MySample {
private void exampleMethod() {
// 一些复杂代码逻辑
}
public void anotherMethod() {
exampleMethod();
}
}
2.2 MyEclipse项目管理快捷键
在项目开发过程中,项目管理是一个重要环节,使用快捷键可以加快项目管理操作。
2.2.1 创建与导入项目快捷操作
MyEclipse提供快捷键用于快速创建和导入项目。
- Ctrl + N :快速新建项目或类等资源。
- Ctrl + Shift + O :导入未导入的类。如果代码中有使用到尚未导入的类,快速按下此快捷键可以自动导入所需的类包。
2.2.2 资源管理与代码版本控制的快捷键
为了更好地管理项目中的资源和代码版本,MyEclipse也提供了以下快捷键:
- Ctrl + Shift + R :快速打开资源文件,不用在项目浏览器中慢慢查找。
- Ctrl + Alt + G :快速定位到错误或者警告位置,便于快速修正代码中的问题。
- Ctrl + Alt + Shift + H :查看方法调用层次,了解方法的调用关系。
2.3 MyEclipse调试与运行快捷键
调试和运行程序是开发过程中不可或缺的步骤。MyEclipse中以下快捷键可以加快调试与运行效率:
- Ctrl + F11 :运行程序,快速启动当前项目。
- Ctrl + D :结束当前运行的程序。
- Ctrl + F8 :切换断点,调试程序时在代码行上添加或移除断点。
2.4 MyEclipse中自定义快捷键设置
MyEclipse还支持自定义快捷键,允许用户根据自己的习惯设置个性化的快捷键。
2.4.1 如何自定义快捷键
- 打开
Window>Preferences>General>Keys。 - 在搜索框中输入要修改的操作名称。
- 点击对应的操作,然后点击
Binding框,输入你想要的快捷键组合。 - 点击
Apply然后点击OK,快捷键便设置成功。
2.4.2 自定义快捷键的最佳实践和技巧
在自定义快捷键时,建议使用不易与其他软件快捷键冲突的组合,如使用 Ctrl+Alt+ 加上某个字母,这样可以确保快捷键的唯一性和便捷性。同时,保持一定的规律性,例如所有与重构相关的操作都使用 Alt+Shift 组合,将有助于记忆和操作。最后,可以通过MyEclipse社区或者参考其他开发者的设置,来寻找灵感和最佳实践。
通过本章节的详细介绍,我们了解了MyEclipse中编辑、项目管理、调试与运行以及自定义快捷键的操作方法和技巧。掌握这些快捷键的使用,可以帮助开发人员在使用MyEclipse时更加高效地完成日常工作。
3. Java方法的概念与分类
3.1 Java方法的定义和结构
Java方法是执行特定任务的一段代码,可以被定义为具有输入参数、执行过程和返回结果的一个单元。方法的定义需要指定访问权限、返回类型、方法名以及参数列表。了解Java方法的基本概念和结构是编程的基础。
3.1.1 方法的作用和定义方式
方法的主要作用是封装一段代码块,并为这段代码提供一个明确的接口,以便在程序中重用。通过方法可以将复杂的任务分解成多个简单任务,从而提高程序的可读性和可维护性。同时,方法还支持模块化编程,有助于管理大型项目中的代码。
在Java中,方法可以按以下格式定义:
访问修饰符 返回类型 方法名(参数类型 参数名, ...) {
// 方法体
}
例如,一个简单的加法方法可以这样定义:
public int add(int number1, int number2) {
return number1 + number2;
}
上述代码中,“public”是访问修饰符,指明了方法的访问级别;“int”是返回类型,表示方法返回一个整型值;“add”是方法名;方法名后面的括号中定义了两个参数“number1”和“number2”,它们都是int类型的;方法体是用花括号括起来的代码块。
3.1.2 方法的参数和返回值
方法的参数是方法内部使用的局部变量,它们在方法被调用时传入。参数可以是任意类型,包括基本数据类型和引用数据类型。方法可以有零个或多个参数。
返回值是方法执行结束后返回给调用者的值。返回值的类型必须与方法定义中的返回类型相匹配,如果方法不需要返回任何值,则使用void作为返回类型。
在下面的例子中,我们定义了一个带有返回值的方法,它接受两个参数,并返回它们的和:
public int add(int num1, int num2) {
return num1 + num2;
}
在使用方法时,通常需要考虑以下几点:
- 参数传递 :参数是如何传递给方法的,是否是通过值传递(基本数据类型)还是引用传递(引用数据类型)。
- 返回类型 :方法返回的类型,以及是否总是需要有返回值。
- 方法重载 :是否可以定义多个同名方法,但它们的参数列表不同。
- 方法重写 :子类是否可以提供与父类方法相同名称和参数列表的方法。
3.2 Java方法的不同分类
3.2.1 根据访问权限分类的方法
在Java中,方法的访问权限决定了它能够在哪些地方被访问。常见的访问权限修饰符有:
- public :公共的,可以在任何位置被访问。
- protected :受保护的,可以在同一个包内或者不同包的子类中被访问。
- default(无修饰符) :默认访问权限,仅限同一个包内的类可以访问。
- private :私有的,只能在定义它的类内部被访问。
按照访问权限,方法可以分为以下几种:
- 公共方法(public)
- 私有方法(private)
- 受保护的方法(protected)
- 默认访问权限的方法(无修饰符)
3.2.2 根据是否有返回值分类的方法
根据方法是否包含返回值,可以将方法分为带返回值的方法和不带返回值的方法:
- 带返回值的方法 :方法在执行完毕后,可以返回一个值给调用者。返回值类型需要在方法定义时明确指出。
- 不带返回值的方法 :这类方法不返回任何值,通常使用void作为返回类型。
3.3 Java方法的参数传递机制
3.3.1 基本数据类型和引用数据类型的参数传递
Java参数传递机制是Java程序设计中的一个重要方面,它直接影响方法内部对参数的处理方式。
- 基本数据类型 :方法接收的是实际的参数值的副本,所以在方法内对参数进行修改不会影响实际传入的参数。
- 引用数据类型 :方法接收的是对象引用的副本,因此,如果在方法内对引用类型参数指向的对象进行了修改,那么这些修改会影响到实际的对象。
3.3.2 Java中参数传递的机制分析
在Java中,方法参数的传递机制可以进一步细分为值传递(对于基本数据类型)和引用传递(对于引用数据类型)。对于对象,传递的是引用的值,即对象的内存地址的副本。这允许在方法内部修改对象的内容,但不允许将方法内部的参数指向一个新的对象地址,除非显式地进行赋值操作。
理解这一机制对于编写正确和高效的代码至关重要,特别是在处理大型数据结构和复杂对象时。以下是一个示例代码,用于解释引用传递和值传递的区别:
public class ParameterPassingExample {
public static void main(String[] args) {
int number = 10;
int[] array = new int[] {1, 2, 3};
System.out.println("Before method call, number = " + number);
modifyVariable(number); // 调用基本数据类型参数的方法
System.out.println("After method call, number = " + number);
System.out.println("Before method call, array[0] = " + array[0]);
modifyArray(array); // 调用引用数据类型参数的方法
System.out.println("After method call, array[0] = " + array[0]);
}
public static void modifyVariable(int value) {
value = 20; // 尝试修改基本数据类型的副本
}
public static void modifyArray(int[] arr) {
arr[0] = 100; // 修改数组中第一个元素的值
}
}
输出结果将会是:
Before method call, number = 10
After method call, number = 10
Before method call, array[0] = 1
After method call, array[0] = 100
从上面的例子可以看出,基本数据类型参数的修改在方法内部并没有影响到原始值,而引用数据类型参数的修改则直接影响了实际的数组对象。这正体现了Java中的参数传递机制。
4. Java方法的重载与重写
4.1 Java方法重载的原理与实践
4.1.1 方法重载的定义和规则
在Java中,方法重载(Overloading)是指在同一个类中可以存在一个以上的同名方法,只要它们的参数列表不同即可。这种机制允许同一个类中存在多个同名方法,但参数类型、个数或者顺序必须至少有一个不同。编译器通过参数列表来区分重载的方法。
例如,以下代码展示了方法重载的一个简单例子:
public class MathUtils {
// 加法方法,两个整数参数
public int add(int a, int b) {
return a + b;
}
// 加法方法,三个整数参数
public int add(int a, int b, int c) {
return a + b + c;
}
// 加法方法,两个浮点数参数
public double add(double a, double b) {
return a + b;
}
}
上述代码中, add 方法被重载了三次,每次都有不同的参数列表。
4.1.2 方法重载在实际编程中的应用
方法重载在实际编程中非常有用,特别是在需要执行相似操作,但参数或参数类型不同的情况下。它增强了方法的通用性和灵活性。例如,使用Java的 String 类, substring 方法就有多个版本:
public class String {
// 返回从beginIndex开始到字符序列的末尾的子字符串。
public String substring(int beginIndex) { ... }
// 返回一个新字符串,它是此字符串的一个子字符串,从beginIndex开始,一直到索引endIndex - 1处的字符。
public String substring(int beginIndex, int endIndex) { ... }
}
在设计自己的类时,为了提供类似的功能但处理不同类型的参数,可以使用方法重载来创建多种版本的方法。这使得方法调用更为直观,并且用户不必记住不同的方法名。
4.2 Java方法重写的机制与原则
4.2.1 方法重写的定义和条件
方法重写(Overriding)发生在子类和父类之间。如果子类有一个与父类签名完全相同的方法,子类可以提供该方法的一个新的实现,这个过程称为方法重写。重写方法必须有相同的参数列表、返回类型(或子类型),并且抛出的异常必须在父类方法的允许范围内。
以下是方法重写的一个例子:
class Animal {
public void makeSound() {
System.out.println("Some sound");
}
}
class Dog extends Animal {
@Override
public void makeSound() {
System.out.println("Bark");
}
}
Dog 类重写了 Animal 类的 makeSound 方法。
4.2.2 方法重写的规则和应注意的问题
在重写方法时,要遵循以下规则: 1. 方法签名必须相同。 2. 返回类型必须兼容(即可以是相同类型或子类型)。 3. 抛出的异常必须是父类方法声明抛出异常的子集或相同。 4. 访问权限不能比父类更严格(例如,父类为 public ,子类不能为 protected )。
在实现时,应注意以下几点: - 避免子类重写方法时改变方法的访问控制符为更严格的级别。 - 确保重写的方法不会引入新的异常类型。 - 考虑使用 @Override 注解,这样如果签名不匹配,编译器会给出错误提示。
4.3 方法重载与重写在面向对象设计中的作用
4.3.1 提高代码复用性和可维护性
方法重载和重写是面向对象编程中实现多态性的两种主要方式。它们有助于提高代码的复用性和可维护性。
- 方法重载 允许创建多版本的方法,为不同的输入提供同样的功能。它避免了方法命名的混乱,且使API调用更加直观。
- 方法重写 允许子类在继承父类功能的基础上提供特有的实现。这避免了代码的重复,并且允许开发者为子类定义特定的行为,增强了代码的灵活性和可扩展性。
4.3.2 设计模式中方法重载与重写的实践案例
在设计模式中,方法重载与重写有很多应用场景。例如,在策略模式(Strategy Pattern)中,不同策略实现相同接口的方法,但具体实现不同,这可以视为方法重载的一种抽象形式。在模板方法模式(Template Method Pattern)中,父类提供了一个模板方法,其中的一些步骤由子类通过重写方法来具体实现。
interface Strategy {
void algorithmInterface();
}
class ConcreteStrategyA implements Strategy {
@Override
public void algorithmInterface() {
System.out.println("Concrete Strategy A implementation.");
}
}
class ConcreteStrategyB implements Strategy {
@Override
public void algorithmInterface() {
System.out.println("Concrete Strategy B implementation.");
}
}
在以上示例中, Strategy 接口定义了一个方法 algorithmInterface ,两个具体策略 ConcreteStrategyA 和 ConcreteStrategyB 分别重写了这个方法,提供了不同的实现。
在实际应用中,通过合理利用方法重载与重写,开发者可以设计出更加灵活、可扩展、可维护的系统。
5. 深入理解Java异常处理机制
5.1 Java异常类的层次结构与分类 5.1.1 Java异常的根类Exception和Error 5.1.2 受检异常与非受检异常的区别 5.1.3 常见的Java内置异常类型
## 5.1.1 Java异常的根类Exception和Error
Java异常处理是编写健壮应用程序的核心部分,异常分为两大类:Exception和Error。Exception是程序能够捕获并处理的异常,通常由程序运行时的错误或不正常情况引起。Exception又分为受检异常(checked exceptions)和非受检异常(unchecked exceptions)。受检异常需要在代码中显式地处理,例如IOException,非受检异常包括运行时异常(RuntimeException)及其子类,如NullPointerException和ArrayIndexOutOfBoundsException。
**受检异常**要求异常必须在代码中得到处理,否则编译器会报错,这样可以确保程序在面对预期之外的情况时能以合理的方式处理,提高程序的健壮性。例如,当你从文件中读取数据时,可能会遇到文件不存在的情况,此时抛出一个FileNotFoundException异常,你的程序需要捕获并处理这种情况。
**非受检异常**通常表示程序编写有误,如逻辑错误或资源管理不当,Java编译器不要求捕获这类异常。尽管如此,在设计程序时,尽量通过适当的异常处理来减少这类异常的发生,提高代码的可靠性。
## 5.1.2 受检异常与非受检异常的区别
受检异常和非受检异常在处理方式上有所不同,主要体现在以下方面:
- **编译时检查**:受检异常在编译时就需要处理,编译器会强制要求在可能抛出该异常的方法签名中声明它。而非受检异常则无需显式声明。
- **异常处理方式**:受检异常通常表示发生了一个可以预料的问题,程序需要通过try-catch语句块来捕获并处理。非受检异常则通常表示一个编程错误,虽然不强制要求处理,但合理的设计应该尽可能预测并避免这类问题。
- **继承体系**:所有的受检异常都继承自Exception类,而所有非受检异常都继承自RuntimeException类。
区分这两类异常有助于开发者合理地设计异常处理机制,确保程序的鲁棒性和用户友好性。以下是两者的对比表格:
| 特性 | 受检异常(Checked Exceptions) | 非受检异常(Unchecked Exceptions) |
|------------------|---------------------------------|-----------------------------------|
| 编译时检查 | 是 | 否 |
| 继承体系 | Exception | RuntimeException |
| 常见例子 | IOException, SQLException | NullPointerException, ArrayIndexOutOfBoundsException |
| 处理方式 | try-catch块或声明抛出 | 检查代码逻辑,避免发生 |
受检异常和非受检异常的合理使用,是编写高质量Java程序的关键。
## 5.1.3 常见的Java内置异常类型
Java提供了大量的内置异常类,这些类覆盖了程序可能遇到的大部分异常情况。以下是一些常见的内置异常:
- **IOException**:表示输入输出操作中遇到的异常,如文件不存在、网络连接问题等。
- **SQLException**:表示数据库操作中发生的异常,如SQL语句错误、数据库连接问题等。
- **NullPointerException**:尝试访问未初始化的对象时抛出。
- **ArrayIndexOutOfBoundsException**:数组访问越界时抛出。
- **ClassCastException**:试图将对象强制转换为不兼容类型时抛出。
- **IllegalArgumentException**:传给方法的参数不符合要求时抛出。
理解这些异常的用途和行为,能够帮助开发者在编写代码时做出正确的异常处理决策。下面通过一个代码块展示如何处理一个常见的异常:
```java
try {
// 尝试打开一个文件
FileInputStream fileInputStream = new FileInputStream("example.txt");
} catch (FileNotFoundException e) {
// 捕获并处理文件未找到的异常
System.err.println("The file could not be found: " + e.getMessage());
}
```
在上述示例中,通过try-catch语句块捕获了可能抛出的FileNotFoundException,从而避免程序因异常终止,并给用户提供了清晰的错误信息。
在学习了Java异常处理机制的基础和深入理解异常类的层次结构后,我们将继续探讨如何在实际应用中合理地进行异常处理以提高程序的健壮性和用户友好性。下一节中,我们将讨论如何正确地抛出和捕获异常,以及如何自定义异常类来表示程序特有的错误情况。
6. Linux系统中Java内存管理详解
5.1 Java内存模型概述
在Java虚拟机(JVM)中,内存管理是确保应用性能和稳定性的关键部分。Java内存模型定义了不同线程如何共享内存,以及如何操作内存来达到线程安全的目的。
5.1.1 堆内存和栈内存
Java内存模型主要分为堆内存(Heap)和栈内存(Stack): - 堆内存主要用于存储对象实例,包括所有类实例和数组。 - 栈内存用于存储局部变量和方法调用,每个线程都有自己的栈空间。
5.1.2 方法区和程序计数器
除了堆和栈,JVM内存模型还包括: - 方法区(Method Area)存放类信息、常量和静态变量。 - 程序计数器(Program Counter Register),指向当前执行的字节码指令地址。
5.2 Java垃圾回收机制
Java的垃圾回收机制对自动管理内存至关重要,它负责回收堆内存中不再使用的对象所占的空间。
5.2.1 垃圾回收基础
垃圾回收(GC)是一个后台运行的过程,用来识别并移除不再被引用的对象。GC的工作机制对程序的性能有重要影响。
5.2.2 常见垃圾回收算法
常见的垃圾回收算法包括: - 标记-清除算法(Mark-Sweep) - 复制算法(Copying) - 标记-整理算法(Mark-Compact) - 分代收集算法(Generational Collection)
5.3 Java内存泄漏分析
内存泄漏是指程序在申请内存后,无法释放已占有的内存空间,导致内存逐渐耗尽。
5.3.1 内存泄漏的原因
内存泄漏的原因多种多样,例如: - 长生命周期的对象持有短生命周期对象的引用 - 错误使用集合类 - 静态集合中的对象未清理
5.3.2 避免内存泄漏的方法
为避免内存泄漏,开发者可以采取以下措施: - 使用弱引用(WeakReference)或软引用(SoftReference) - 定期审查代码,特别是集合类的使用 - 使用分析工具检测内存泄漏
5.4 Java内存优化策略
为了提升Java应用的性能,合理的内存分配和优化是必不可少的。
5.4.1 堆内存优化
调整堆内存大小可以优化性能: - -Xms 启动JVM时设置堆内存的初始大小 - -Xmx 设置堆内存的最大值
5.4.2 栈内存优化
栈内存优化通常涉及设置线程栈的大小: - -Xss 指定每个线程的栈大小
5.4.3 GC优化
针对不同的应用场景,选择合适的垃圾回收器: - Serial GC:适用于小型应用和单核处理器 - Parallel GC:适用于多处理器服务器 - CMS GC:适用于需要低停顿时间的应用 - G1 GC:适用于大内存应用,目的是实现可预测的停顿时间
flowchart LR
JVM[Java虚拟机]
A[堆内存<br>存放对象实例]
B[栈内存<br>存储局部变量和方法调用]
C[方法区<br>存储类信息和静态变量]
D[程序计数器<br>指向字节码指令地址]
JVM --> A
JVM --> B
JVM --> C
JVM --> D
通过深入理解Java内存模型、垃圾回收机制、内存泄漏分析和内存优化策略,开发者可以更有效地管理内存,提升Java应用的性能和稳定性。
简介:本文深入探讨了在Linux环境下Java编程的基础知识,包括变量、关键字以及MyEclipse集成开发环境的快捷键。同时,也详细讲解了Java方法的使用,如方法的分类、重载和重写等概念。熟练掌握这些技能对于Java开发者至关重要。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









