






线上问题排查:在生产环境当中,由于环境的限制,没有办法在本地调试生产环境的代码,所以只能够通过日志去判断具体代码出错的位置在哪里。
与往常一样,直接去观察日志所打印出来的报错,但是遇到了比较奇怪的点就是这里并没有打印出这个异常具体详细的堆栈信息。因为以往就算是遇到空指针异常,具体详细的堆栈信息也会打印出来的。
如下图:
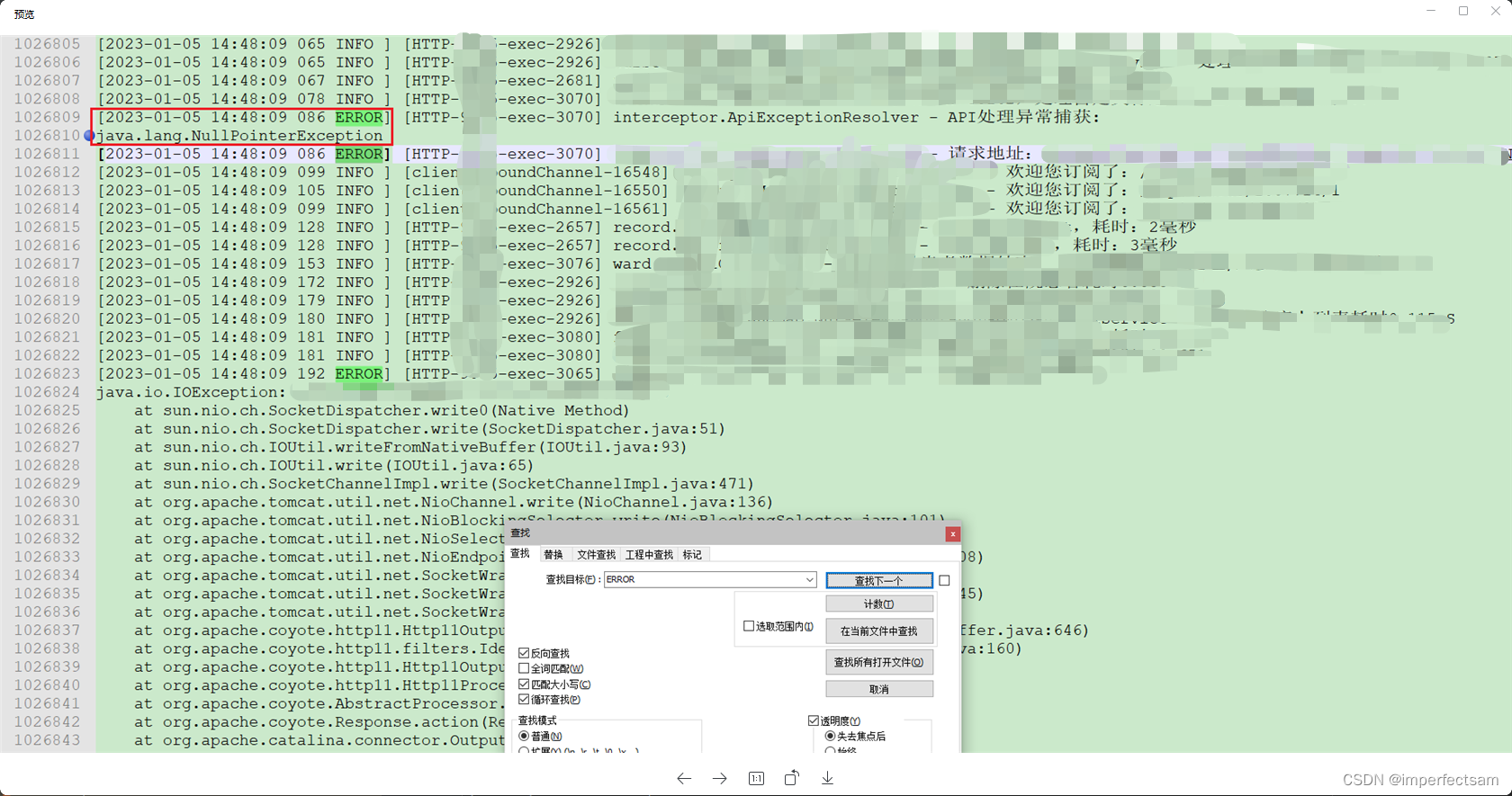
于是我这里看回代码拦截器捕捉异常的地方:
@Override
public ModelAndView resolveException(HttpServletRequest request,
HttpServletResponse response, Object handler, Exception ex) {
Throwable deepestException = deepestException(ex);
log.error("API处理异常捕获:", deepestException);
log.error("请求地址:"+request.getRequestURL());
return processException(request, response, handler, ex, deepestException);
}
/**
* 获取最原始的异常出处,即最初抛出异常的地方
*/
private Throwable deepestException(Throwable e) {
Throwable tmp = e;
int breakPoint = 0;
while (tmp.getCause() != null) {
if (tmp.equals(tmp.getCause())) {
break;
}
tmp = tmp.getCause();
breakPoint++;
if (breakPoint > 1000) {
break;
}
}
return tmp;
}
发现这段代码并没有异常的地方,就算捕捉到异常也会打印出最原始出错的地方。
于是经过查阅JVM官方文档后发现jvm启动参数中没有配置-XX:-OmitStackTraceInFastThrow,参数:OmitStackTraceInFastThrow字面意思是省略异常栈信息从而快速抛出。
相关源码
// If this throw happens frequently, an uncommon trap might cause
// a performance pothole. If there is a local exception handler,
// and if this particular bytecode appears to be deoptimizing often,
// let us handle the throw inline, with a preconstructed instance.
// Note: If the deopt count has blown up, the uncommon trap
// runtime is going to flush this nmethod, not matter what.
// 这里要满足两个条件:1.检测到频繁抛出异常,2. OmitStackTraceInFastThrow为true,或StackTraceInThrowable为false
if (treat_throw_as_hot
&& (!StackTraceInThrowable || OmitStackTraceInFastThrow)) {
// If the throw is local, we use a pre-existing instance and
// punt on the backtrace. This would lead to a missing backtrace
// (a repeat of 4292742) if the backtrace object is ever asked
// for its backtrace.
// Fixing this remaining case of 4292742 requires some flavor of
// escape analysis. Leave that for the future.
ciInstance* ex_obj = NULL;
switch (reason) {
case Deoptimization::Reason_null_check:
ex_obj = env()->NullPointerException_instance();
break;
case Deoptimization::Reason_div0_check:
ex_obj = env()->ArithmeticException_instance();
break;
case Deoptimization::Reason_range_check:
ex_obj = env()->ArrayIndexOutOfBoundsException_instance();
break;
case Deoptimization::Reason_class_check:
if (java_bc() == Bytecodes::_aastore) {
ex_obj = env()->ArrayStoreException_instance();
} else {
ex_obj = env()->ClassCastException_instance();
}
break;
}
... ...
}
OmitStackTraceInFastThrow默认为true,如果想关闭这个优化,需要配置-XX:-OmitStackTraceInFastThrow。
JVM只对几个特定类型异常开启了Fast Throw优化,这些异常包括:
NullPointerException
ArithmeticException
ArrayIndexOutOfBoundsException
ArrayStoreException
ClassCastException
于是这里我手动编写了一个测试类进行测试验证是否会对fastThrow进行优化:
@Test
public void nullPointerTest(){
for (int i = 0; i < 200000; i++) {
try {
((String) null).toString();
} catch (Exception e) {
int stackTraceLength = e.getStackTrace().length;
log.error("第"+i+"条数据"+"堆栈错误",e);
}
}
}
执行以上代码,然后再去观察log日志我们可以发现
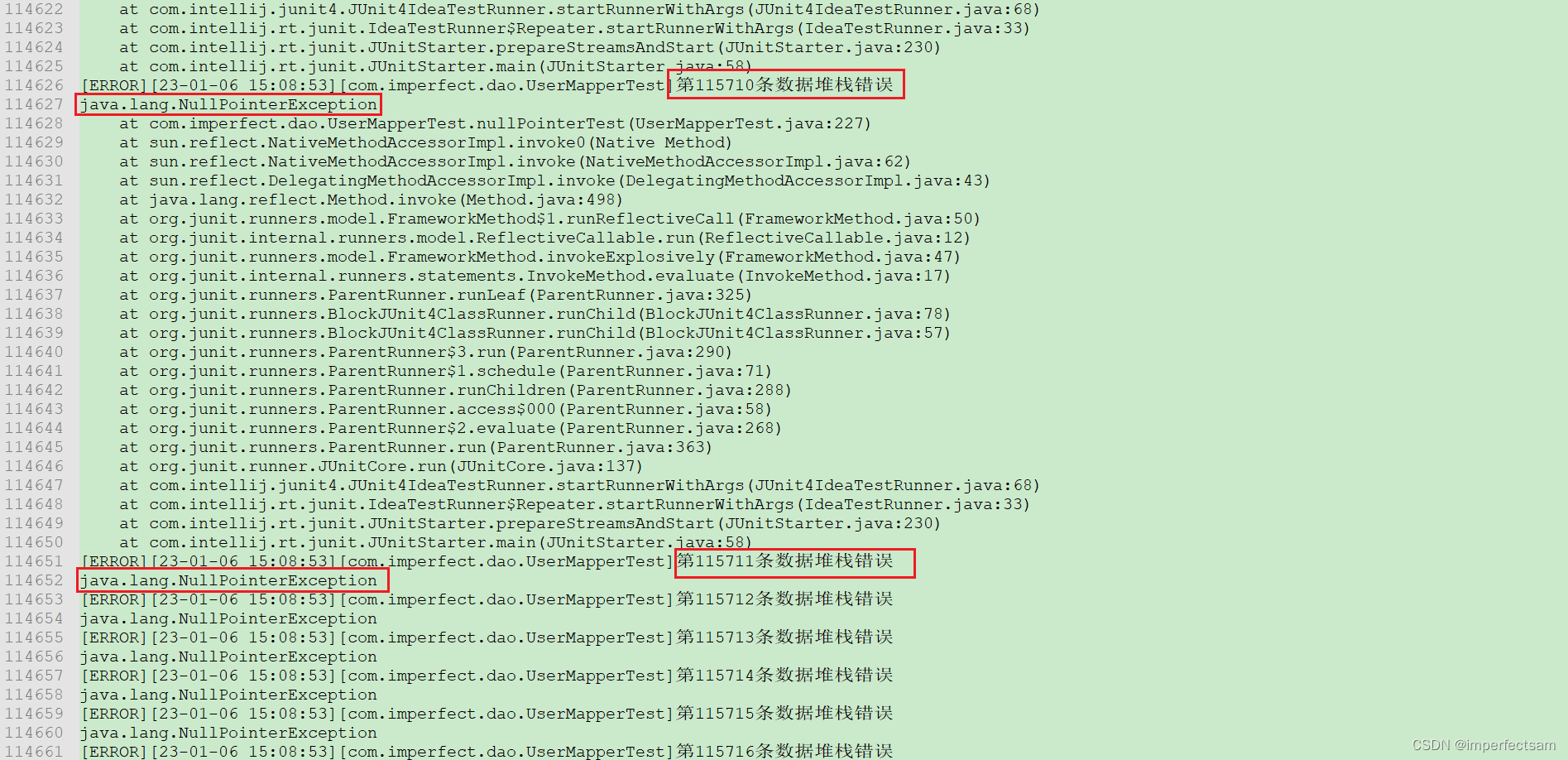
在大约十一万条异常抛出后,后面的异常会自动忽略了堆栈信息的打印。
生产环境问题的解决方案:由于我们生产环境的限制,这里我就不会修改JVM参数的配置,而是通过下一次服务启动的时候,在短时间内(大概十一万次错误之前)人为地去复现这个错误,这样就能够打印详细的堆栈信息,从而进一步地去排查问题。















 1520
1520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









