







键值数据库key-value

一、认识NoSql
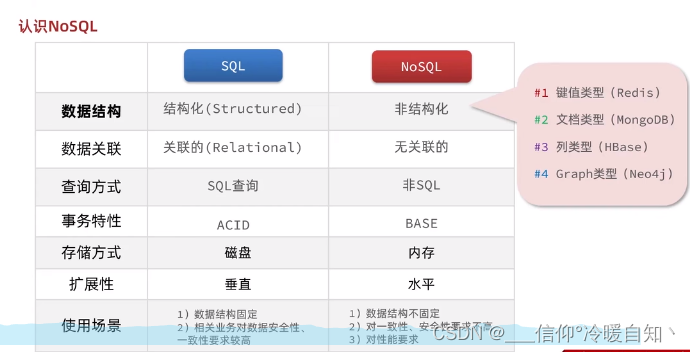
SQL:关系型数据库
结构化数据---->有表,有数据,字段约束严谨
关系型数据库,库表是有关联的
SQL查询:语法固定select.....
满足ACID事务特性

NoSQL:非关系型数据库
非结构化------>key + value (可以自定义,key比如是id,vlaue是一个json),字段约束松散,什么都可存,可以是字符串,可以是整形等
非关联的:程序员自己去维护关系
非SQL
无法完全满足ACID特性,只能有最基本的
二、认识Redis
特征:
1、键值型,value支持多种不同数据结构
2、单线程。每个命令具备原子性(线程安全的)
3、低延迟,速度快,是基于内存的
4、支持数据持久化,防止特殊原因,比如断电,定期将数据持久化到磁盘,保证数据的安全
5、支持主从集群(从节点可以去备份主节点的数据,一但有节点done机,其它节点可以找得到,安全性考虑,主从)、分片集群(数据拆分,1TB的数据查分成N份等)
6、支持多语言客户端(java、c、python等)
三、安装Redis
这里方便测试用的是windows的Redis,客户端用的是RDM,Redis的图形界面
RDMgit地址:Releases · lework/RedisDesktopManager-Windows · GitHub
四、选择Redis仓库
Redis默认有16个仓库,编号从0至15. 通过配置文件可以设置仓库数量,但是不超过16,并且不能自定义仓库名称。
如果是基于redis-cli连接Redis服务,可以通过select命令来选择数据库:
# 选择 0号库
select 0
五、Redis数据结构
Redis是一个key-value的数据库,key一般指String,value的类型多样性
前五种属于基本类型,字符串、Hash、List链表、Set无序、sortedSet

六、Redis相关命令
Redis官网:https://redis.io/commands
里边有Redis的指令,可供查看,或者命令行操作:help @xxx
通用命令:Generic

- keys :相当查询key,基于通位符(*模糊查询效率低,?第一个字符)。keys * 所以:不建议在生产环境上使用,Redis是单线程的,数据量大的时候,查询没出结果的话会有阻塞。例如:keys *、keys n*(以n开头的key)
- del key:删除key ,传一个删一个,传多个删多个,返回值为删除的数量
- MSET k1 v1 k2 v2 k3 v3...:批量插入 mset k1 v1 k2 v2 k3 v3.....
- exists key: 判断key是否存在,后面跟一个或多个,存在返回1;不存在返回值0; eg:exists name
- expire key 秒:给一个key设置有效期,有效期到期时该key会被自动删除。redis是基于内存存储的,如果不设置有效期,以后内存可能就会越来越多,如设置验证码,持续1分钟,到期自动删除,单位是秒 eg:expire age 20
- TTL key:查看某一个key的有效期剩余时间 -1永久有效,-2被移除 eg :ttl age
- get key :获取age
- set key value :写入一个
七:String类型的常见命令
String类型,也就是字符串类型,是Redis中最简单的存储类型,其value是字符串,不过根据字符串格式的不同,又可以分为3类
- String:普通字符串类型
- int :整数类型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
不管是哪种格式,底层都是字节数组形势存储,只不过是编码方式不同,字符串类型的最大空间不能超过512M。数值类型的字符串 底层是2进制的低八位,,节省空间,而字符串是把字符转换成对应的字节码去存储,

String常见命令有:
- set:添加或者修改已经存在的一个String类型的键值对
- get:根据key获取String类型的value
- mset:批量添加多个String类型的键值对
- mget:根据多个key获取多个String类型的value
- incr:让一个整形的key自增1
- incrby:让一个整形的key自增并指定步长,例如:incrby num 2 ,让num值自增2;-1就是自减
- incrbyfloat:让一个浮点类型的数字自增并制定步长
- setnx:添加一个String类型的键值对,当存储的key不存在的时候,插入才成功,key存在插入失败,没有修改值,或者 set name lisi nx 与setnx命令一样
- setex:添加一个String类型的键值对,并且指定有效期,添加的同时设置有效期,是expire的增强,set name lisi ex 10
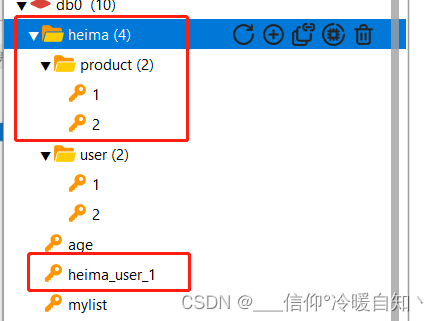
八、Redis没有类似的table表的概念,那我们如何区分不同的key呢?
例如:有用户、商品的信息需要存储到redis里,而他们两个的id 恰巧都是1 ,那么如何区分呢?
答:可以在拼接一些字符串,拼接用冒号:隔开!好处:实现层级分离,让数据看起来比较优雅
即:代理人:用户名:id
key定义好了,value呢? String类型的对象是字符串,java完全可以去序列化
如果value是一个对象,那我们可以用json 去序列化成一个字符串对象

用冒号隔开的好处是可以分成层级结构
例如:
set heima:product:1 '{"id":1, "name":"Jack", "age": 21}'
set heima:product:2 '{"id":1, "name":"Jack", "age": 21}'
set heima:user:2 '{"id":1, "name":"Jack", "age": 21}'
set heima:user:2 '{"id":1, "name":"Jack", "age": 21}'
setheima_user_1 '{"id":1, "name":"Jack", "age": 21}' ,非冒号的key就没有形成层级结构
总结:
String类型的三种格式,字符串、int、float
Redis的key的格式,:采用层级存储的格式
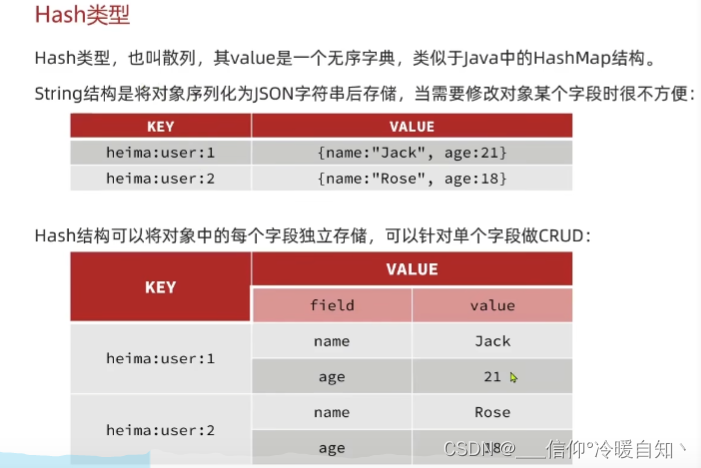
九:Redis的hash类型
String结构是将数据序列化微JSON字符串后存储,当需要修改某个字段时很不方便
Hash结构可以将对象中的每个字段独立存储,可以针对单个字段进行CRUD操作,对别的字段没有影响
其中field也叫hashKey,value也叫hashValue
Hash类型的常见命令
- hset key field value:添加或者修改hash类型key的field的value:可以在同一个key插入多个不同的field
- hset heima:user:3 name lucy
- hset heima:user:3 age 21
- hset heima:user:3 age 19,对一个值进行修改
- hget key field:获取一个hash类型key的field的value:
- hget heima:user:3 name => Jack
- hmset:批量添加多个hash类型key的field的值 :
- hmset heima:user:4 name wanger age 21
- hmget:批量获取多个hash类型key的field的值(value) :
- hmget heima:user:4 name age
- hgetall:获取一个hash类型的key中的所有的field和value
- hgetall heima:user:4
- hkeys:获取一个hash类型的key中的所有field
- hkeys heima:user:4
- hvals:获取一个hash类型的key中的所有的value
- hvals heima:user:4
- hincrby:让一个hash类型key(field)的字段值(value)自增并指定步长,比如年龄
- hincrby heima:user:4 age 4
- hsetnx:添加一个哈希类型的key的field值,前提是这个field不存在,否则不执行
- hsetnx heima:user:4 score 98.5
十、List类型
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构,既可以支持正向检索也可以支持反向检索
特征也与LinkedList类似,常用情景:对顺序有序的场景,如:朋友圈点赞、评论
- 有序:插入顺序
- 元素可以重复
- 插入和删除快
- 查询速度一般
使用场景:常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等
常用命令:

- lpush key element...:向列表左侧插入一个或多个元素, list先进后出,lpush users 1 2 3显示的话就是3 2 1,因为是从左侧推的

- lpop key:移除并返回列表左侧的第一个元素,没有则返回nil
- rpush key element...:向右侧列表插入一个或多个元素,从右侧推,rpush users 4 5 6,结果就是
-
- rpop key:移除并返回列表右侧的第一个元素
- lrange key start end:返回一段下标范围内的所有元素
- blpop 和 brpop 与 lpop 和 rpop类似,只不过在没有元素时等待指定时间,而不是直接返回nil,blok阻塞,就是会阻塞一段时间,超时时间是秒: blpop users 20。即:两个redis一个取没有阻塞20秒,另一个服务插入的时候,这个服务就能娶到了

思考:
- 如何利用List结构模拟一个栈?
- 栈:先进后出,===喝酒吐了 栈。
- 入口和出口在同一边。。。
- 即:入:用lpush 出 :用lpop
- 如何利用List结构模拟一个队列?
- 队列:先进先出 ====喝酒喝多了,尿尿排出来,
- 入口和出口不在一起
- 入:lpush,出rpop
- 如何利用List结构模拟一个阻塞队列?
- 入口出口不在一起
- 出队时采用blpop或brpop
十一、set类型的常见命令和基本用法
Redis的set结构与java中的HashSet类似,可以看做是一个value为null的HashMap,因为也是一个hash表,因此具备与HashSet类似的特征
- 无序
- 元素不可重复
- 查找快
- 支持交集、并集、差集等功能
单集合操作
- sadd key member...:向set中添加一个或多个元素
- srem key member...:移除set中的指定元素
- scard key:返回set中元素的个数
- sismember key member:判断一个元素是否存在于set中
- smembers key:获取set中的所有元素
多集合操作
- sinter key1 key2...:求key1与key2的交集
- sdiff key1 key2...:求key1与key2的差集--->sdiff s1 s2 结果就是A,反之sdiff s2 s1,结果就是D
- sunion key1 key2...:求key1与key2的并集

练习:

十二、sortedSet类型
Redis的sortedSet是一个可排序的set集合,与java中的TreeSet有些类似,但底层数据结构却差别很大,SortedSet中的每一个元素都带有score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加hash表
SortedSet具备下列特性
- 可排序
- 元素不可重复
- 查询速度快
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能
SortedSet常见命令,排名得默认+1 否则是从0开始的
- zadd key score member:添加一个或多个元素到sortedSet ,如果已经存在则更新器score值
- zrem key member:删除sortedSet 中的一个制定元素
- zscore key member:获取sortedSet中指定元素的score值
- zrank key member:获取sortedset中的指定元素的排名
- zcard key:获取sortedset中的元素个数
- zcount key min max:统计score值在给定范围内的所有元素的个数,查的是数量,个数
- zincrby key increment member:让SortedSet中的指定元素自增,步长为指定的increment值
- zrange key min max:按照score排序后,获取指定 排名 范围内的元素
- zrangebyscore key min max:按照score排序后,获取指定score 范围 内的元素,查的是元素
- zdiff、zinter、zunion:求差集、交集、并集
以上都是默认都是升序排序,如果要降序,则在命令的Z后面天界REV即可,如:zrev

- zadd stus 85 jack 89 lucy
- zrem stus tom
- zscore stus amy
- zrevrank stus rose
- zcount suts 0 80
- zincrby stus 2 amy
- zrevrange stus 0 3
- zrangebyscore stus 0 80
注意 range类型 是查元素的,count类型是查数量















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









