







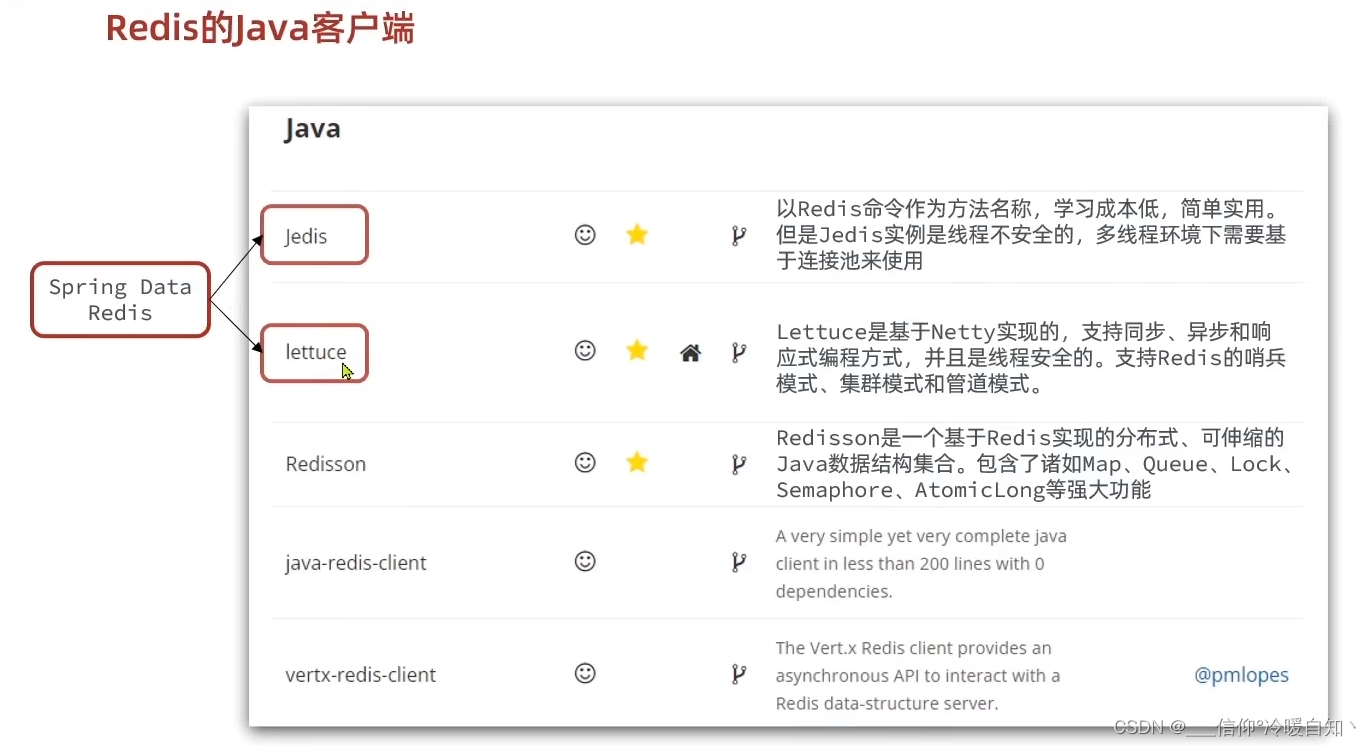
一、Redis的java客户端
Jedis:jdeis里的方法都是以redis的命令来作为方法名称的,比如redis有个命令set,jidis里就有一个方法叫set...,但是Jedis实例是线程不安全的,也就是说创建一个Jedis实例,多线程并发运行的时候有并发安全问题,所以多线程使用时,必须为每个Jedis 创建一个独立的连接
lettuce:与spring的结合的比较好
Redisson:
Spring Data Redis 整合了 Jedis 和 lettuce
二、Jedis的学习
Jedis的官网地址: https://github.com/redis/jedis,我们先来个快速入门:
1、pom文件引入依赖
<dependencies>
<!-- jedis 依赖-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.2.0</version>
</dependency>
<!-- 测试类 -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.6.3</version>
<scope>test</scope>
</dependency>
</dependencies>2、建立连接
3、测试string
4、关闭连接,释放资源
public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUp (){
// 建立连接
jedis = new Jedis("localhost", 6379);
// 设置密码
// jedis.auth(""); windows 这个没有密码,所以没有
// 选择库
jedis.select(0);
}
@Test
void test1() {
String result = jedis.set("name", "小明");
System.out.println("result:"+ result);
String name = jedis.get("name");
System.out.println("name="+name);
}
@AfterEach
void tearDown() {
// 添加健壮性判断,如果在setUp 抛异常了,直接关的话会有空指针的风险
if (jedis!=null) {
jedis.close();
}
}
}
三、Jedis连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们使用Jedis连接池代替Jedis的直连方式
1、创建一个静态连接池
public class JedisConnectionFactory {
// JedisPool 是官方提供的一个连接池的用法
private static final JedisPool jedisPool;
static {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
// 最大连接数,这个连接池最多可以创建8个连接
jedisPoolConfig.setMaxTotal(8);
// 最大空闲连接,没有人来访问这个池子的时候,这个池子最多也是预备8个连接
jedisPoolConfig.setMaxIdle(8);
// 最多空闲连接一直放在这里没人连接,也不好,放一段时间就会清理,
// 设置最小空闲连接 ,如果一段时间没有人连接,这些连接就会被释放,直到0为止
jedisPoolConfig.setMinIdle(0);
// 等待时长,当连接池没有连接可用的时候,等待时长,默认值是-1,没有连接是无限制等待,直到有空的连接
// 设置1000,最多等待1000毫秒,然后就会报错了
jedisPoolConfig.setMaxWaitMillis(1000);
jedisPool = new JedisPool(jedisPoolConfig, "localhost", 6379);
}
// 返回一个Jedis 对象
public static Jedis getJedis(){
return jedisPool.getResource();
}
}2、修改测试类
public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUp (){
// 建立连接
// jedis = new Jedis("localhost", 6379);
// 通过连接池创建Jedis
jedis = JedisConnectionFactory.getJedis();
// 设置密码
// jedis.auth(""); windows 这个没有密码,所以没有
// 选择库
jedis.select(0);
}
@Test
void test1() {
String result = jedis.set("name", "小明");
System.out.println("result:"+ result);
String name = jedis.get("name");
System.out.println("name="+name);
}
@AfterEach
void tearDown() {
if (jedis != null) {
// 如果有连接池,那么久不是真的关闭了,
// 底层是把连接归还给连接池 returnResource,而不是销毁
// 如果没有连接池,那么就是销毁了
jedis.close();
}
}
}四、SpringDataRedis
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做Spring DataRedis
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis(核心是RedisTemplate)
- 支持Redis集群和Redis哨兵
- 支持基于JDK、Json、Spring对象的序列化及反序列化(就是字符串Json)
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作,并且将不同数据类型的操作API封装到了不同的类型中
即:RedisTemplate对提供了一些列的API=对命令进行了分组,有专门操作字符串的、list等的命令,返回值都是Operations对象,这个对象里边封装的就是对该类型的各种操作,
SpringDataRedis利用对象封装的形式,将不同数据类型的方法封装成不同的对象(operations),我们操作方法就不会显得那么臃肿了,各司其职,这就是RedisTemplate的设计思想,而redisTemplate里面是封装的通用的,或一些特殊的命令

五、SpringDataRedis快速入门
基于SpringBoot,提供了对SpringDataRedis的支持,使用非常简单
创建项目选择脚手架->勾选lombok->noSql的redis,这样引入的话,pom文件就会自动引入相关依赖了

可以手动将resources的文件application.xxxx文件的后缀名改为.yaml 或者yml都可以

SpringRedisData操作步骤
1、引入依赖
<!-- redis 依赖,如果勾选这个是自动引入的-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- common-pool2 不管是Jedis 还是 lettuce
都需要引入commons-pool 他们的底层都是基于commons-pool来实现连接池效果的-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.11.1</version>
</dependency>2、application.yaml编写配置,输入spring.redis.host后自动换行这就是yaml或yml,port就是同级的
# redis 相关配置
spring:
redis:
host: localhost
port: 6379
database: 0 # 选择库,默认是0号库
# redis连接池配置 两套 有Jedis 也有 lettuce配置,、
# 如果想引入Jedis的连接池,那么还需要在pom文件引入Jedis相关依赖,因为 spring默认是使用lettuce的
# 虽然jedis有默认值是8 ,但是我们一定要手动配置连接池,否则连接池是不生效的
jedis:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 100ms3、注入
// 注入 自动装配
@Resource
RedisTemplate redisTemplate;4、测试
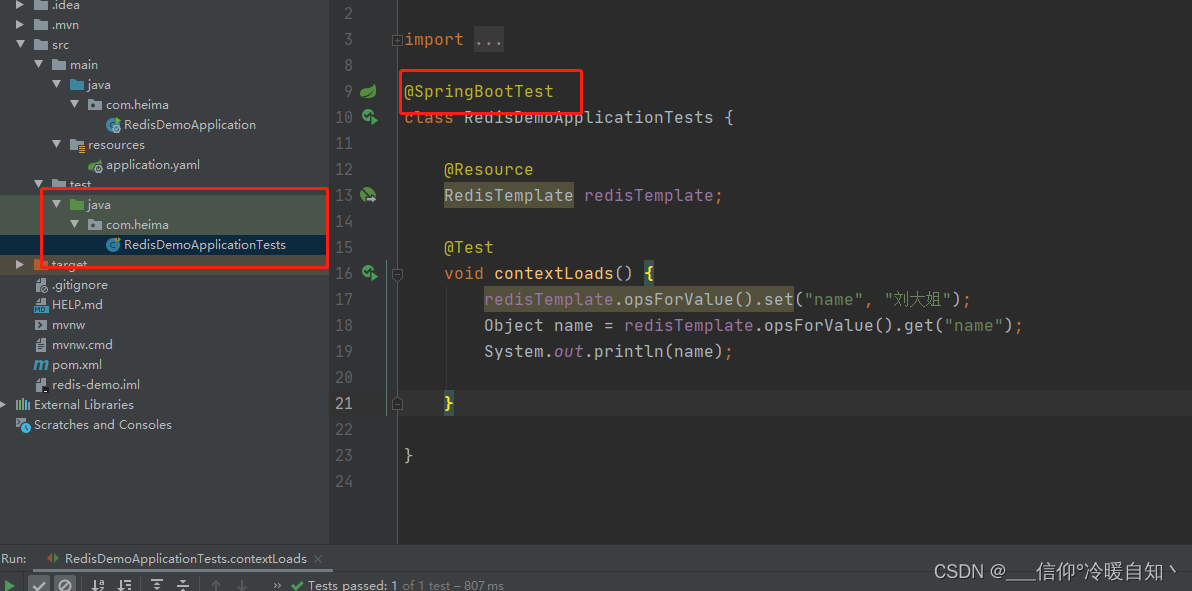
总结:SpringDataRedis的使用步骤:
1、引入spring-boot-start-data-redis依赖
2、在application.yml配置Redis信息
3、注入RedisTemplate
4、编写测试 或 实现代码
六、代码底层
在java代码里 redisTemplate.opsForValue().set("name", "刘大姐");,这里set的是Object对象,
而不是字符串,而在Redis命令界面set是字符串,所以会有两个
第一个是java 写进来的对象
第二个是终端写入的rose字符串
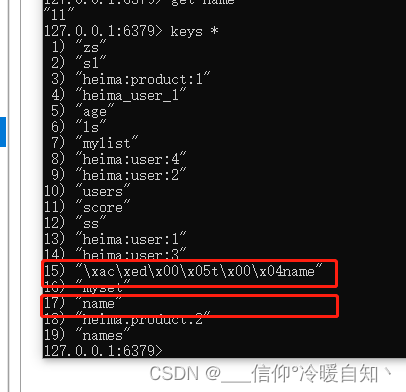
这个就是SpringDataRedis的一个特殊功能,它可以接收任何类型的对象,帮我们转成Redis可以处理的字节。所以我们存进去的name 和 刘大姐,都被当成了java对象了,而redisTemplate的底层默认对这些对象的处理方式,就是利用JDK的序列化工具ObjectOutputStram
RedisTemplate底层,这四个东西 比如keySerializer就是对key进行序列化,valueSerializer就是对value进行序列化,hash。。。是对hash类型的 field 和值得序列化、
我们利用RedisTemplate存入的一切数据,取决于我们的数据结构,最后都会利用这四个东西,来去做序列化和反序列化。如果是字符串,现在这俩个是null,下面的方法会进行初始化

在下面的代码 会创建一个默认的序列化器,而这个默认序列化器就是JDK的序列化器,在我们没有给上面的值进行定义的情况下,就会走下边的默认JDK序列化器
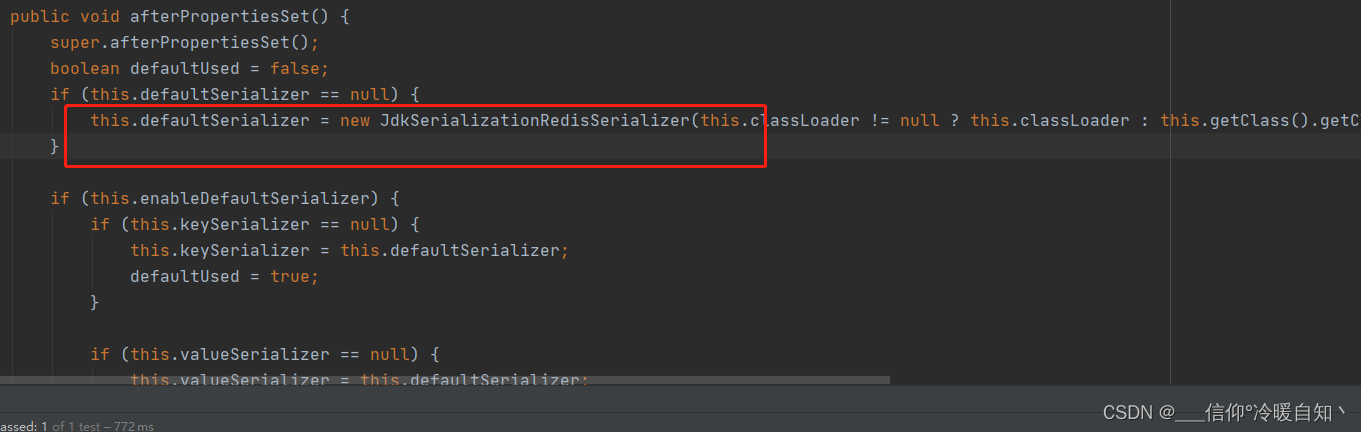
看下边的set方法

我们传进来的value 会被rawValue装饰,传进来对象会变成字节
怎么装饰的?看下边代码,因为现在value不是字节数组,那么就走this.valueSerializer().serialize(value);,尝试去走valueSerializer,也就是上边值得序列化器
byte[] rawValue(Object value) {
return this.valueSerializer() == null && value instanceof byte[]
? (byte[])((byte[])value)
: this.valueSerializer().serialize(value);
}继续跟入serialize方法,就进入了JdkSerializationRedisSerializer类,就是上边默认的序列化工具
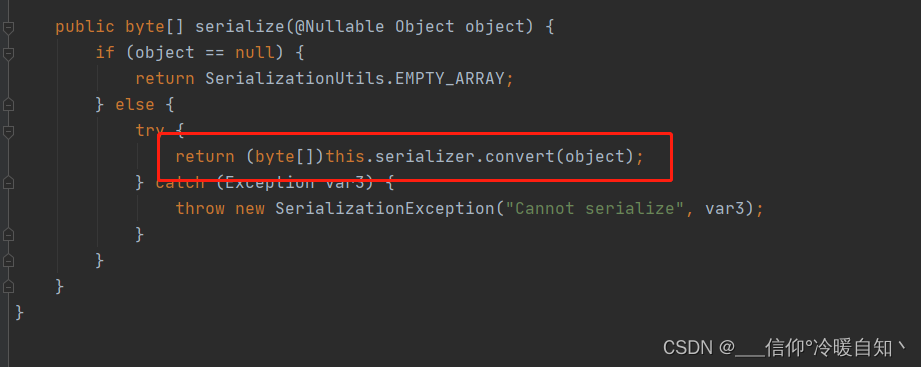
而JDK序列化工具底层用的是ObjectOuterStream,继续走convert方法

再往下走 SerializingConverter类
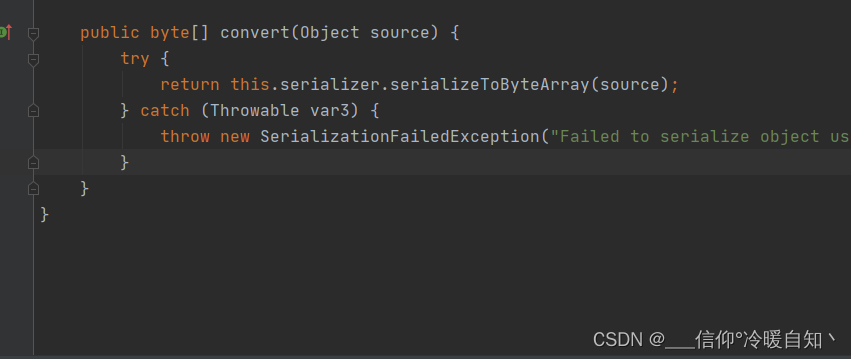
再往下走,ByteArrayOutPutStream,这是一个缓冲字节流

再往下走,就看到了,是利用ObjectOutpuStrem 的writeObject方法去写入的,这个流的作用就是将java对象转换成字节。转成字节,在写入Redis以后,我们看到的就是 "\xac\xed\x00\x05t\x00\x04name" 这个样子了

以上:就是JDK的序列化方式了
SpringDataRedis的序列化方式
RedisTemplate可以接收任意Object对象作为值写入Redis,只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果就是下面这样的
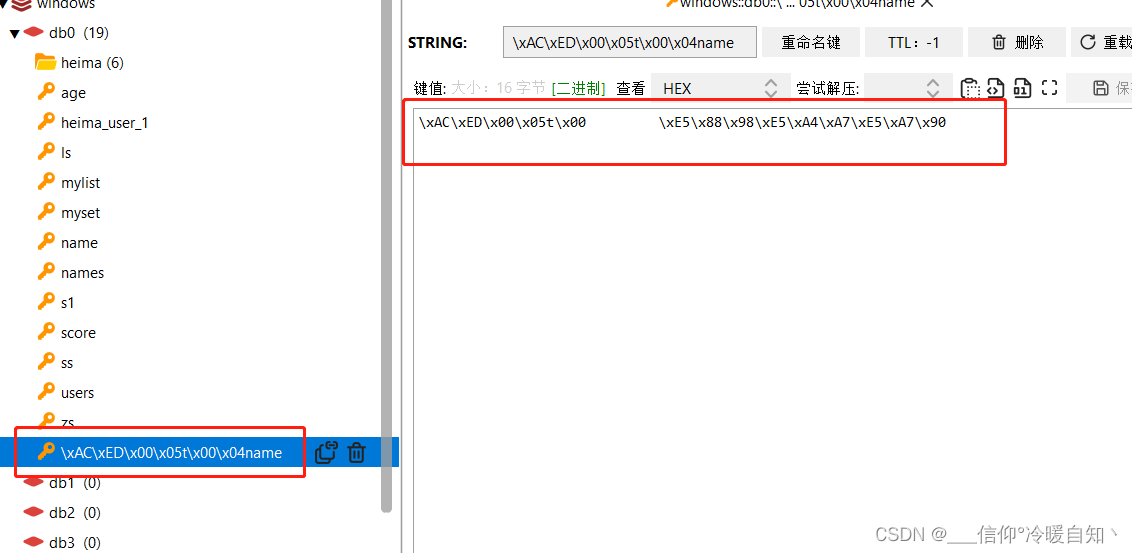
缺点:
- 可读性差:而且还会出现一些问题,我以为我set写入的name是刘大姐,我以为我把name改了,结果没改还是rose,我是set了一个新的东西进去,就是因为key也被序列化了,所以可读性差,还会出现问题
- 内存占用较大:明明我写的是刘大姐,结果却是一大长串,占用空间太大了
希望的是:所进即所得,我写的是什么,就是什么
这样的话就必须去改变RedisTemplate的序列化方式
改变RedisTemplate的RedisSerializer对象,不要用默认的
RedistTemplate下的

七、查看RedisSerializer 都有哪些实现类。快捷键ctrl+h,然后点中RedisSerialize
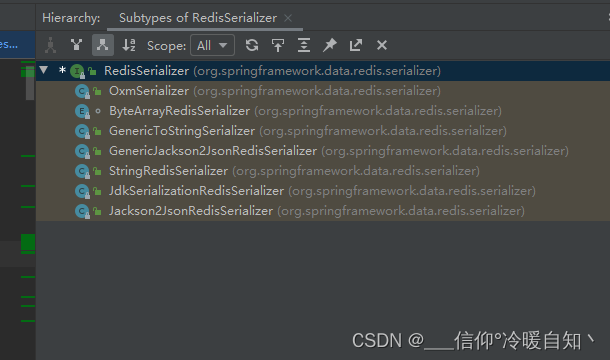
八、都有哪几种实现的方式?有三个
1、JDK 这种方式是最不好用的
2、StringRedisSerialize 这种是专门来处理字符串的,因为字符串转字节写入redis ,只需要简单的getBytes就可以了,没必要利用JDK去序列化,所以StringRedisSerialize,它做的事情就是getBytes,只不过底层的编码可以控制,比如UTF8等。什么时候用这个? 比如我们的key 和 hashKey 都是字符串的时候用它
3、如果value是对象的话,建议用GenericJackson2JsonRedisSerializer(转JSON字符串的序列化工具)
如下代码,key用String ,value用jackson2json来处理的,新建类com.heima.config.RedisConfig
@Configuration // 告诉springBoot该类是个配置文件类
public class RedisConfig {
@Bean // 注入spring,key为字符串,值为对象,RedisTemplate创建需要连接工厂,工厂不需要我们创建,会有springBoot自动帮我们创建,我们注入就可以了
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
// 创建RedisTemplate对象
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
// 连接工厂
redisTemplate.setConnectionFactory(redisConnectionFactory);
// 创建JSON序列化工具, 用jackson2json
GenericJackson2JsonRedisSerializer redisSerializer = new GenericJackson2JsonRedisSerializer();
// 设置key的序列化 字符串,这个string返回值就是StringRedisSerializer 是个常量编码:return StringRedisSerializer.UTF_8;
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
// 设置value的序列化 对象
redisTemplate.setValueSerializer(redisSerializer);
redisTemplate.setHashValueSerializer(redisSerializer);
// 返回
return redisTemplate;
}
}直接修改测试工具了i代码:指定泛型,运行会报错,缺少依赖,缺少一个类,缺少jackson依赖,平常我们开发是不需要自己引入的,用的是springMVC,会自带这个依赖的jackson-databind
Caused by: java.lang.NoClassDefFoundError: com/fasterxml/jackson/core/JsonProcessingException
@Resource
private RedisTemplate<String, Object> redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("name", "刘大姐");
Object name = redisTemplate.opsForValue().get("name");
System.out.println(name);
}<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>引入依赖后就成功写入了
九、当我们写入一个对象Value的时候
新建一个类pojo.User
@Data
@NoArgsConstructor // 无参构造
@AllArgsConstructor // 有参构造
public class User {
private String name;
private Integer age;
}新建测试方法
@Test
void setUserTest() {
// 写入数据
redisTemplate.opsForValue().set("User:100", new User("刘大姐", 28));
// 获取数据,返回来的是一个Object,但是我们明确的知道我们存取的就一个User对象,那么就可以强转了
User user = (User) redisTemplate.opsForValue().get("User:100");
System.out.println("user = " + user);
}redis图形界面:我们发现存入了一个JSON对象,而且是JSON风格的,说明它是自动化的帮我们把对象转成了JSON写入了Redis里,并且当我们获取结果的时候,他还能自动帮我们反序列化成java对象
即:存的时候存User它帮我们转JSON,取的时候,取JSON它帮我们转User对象
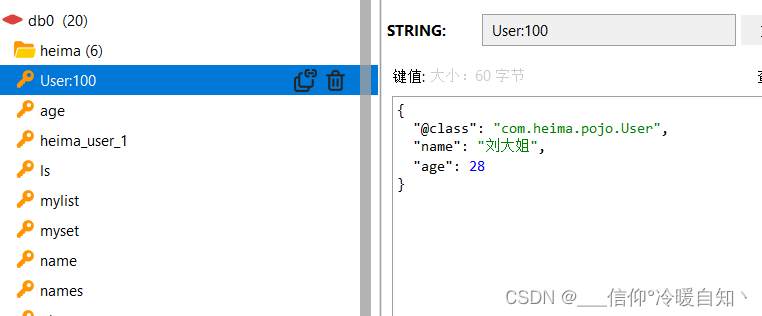
事实上帮我们写入JSON的同时,还帮我们写入了一个@class 这样的一个属性。对应的就是这个User类的字节码名称,正是因为有这样一条属性,它在反序列化的时候才能读取到字节码就是类的名称。帮我们把JSON反序列化成对应的User对象写入进来,这就是自动化的效果。
以后我们再去存储不管是字符串 或者 对象也好,都可以自动化了,要求就是key是字符串,值随便
十、StringRedisTemplate
尽管JSON的序列化方式可以满足我们的需求,但是依然存在一些问题,如图
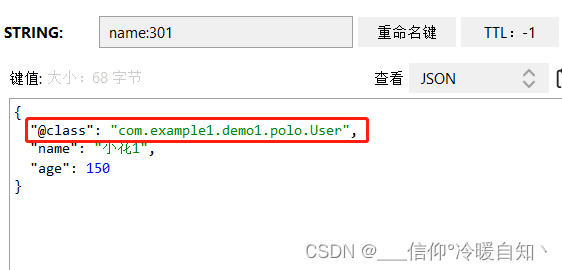
为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销,这个字节码占用的空间,比我们的name age数据还要长
实现自动的序列化和反序列,必须要有这个东西。
如果要节省空间,这个东西就不能要,如果不能要就不会自动序列化
为了节省内存空间,我们并不会使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value。当需要存储java对象时,手动完成对象的序列化和反序列化
即:确定存对象时->手动序列化->存入redis->从redis获取->手动反序列化,这样就解决了内存占用的问题

十一、利用StringRedisTemplate序列化工具来实现,它存入的key 和 value 都是字符串的。
1、注入
@Resource
private StringRedisTemplate stringRedisTemplate;2、引入jar包fastjson,阿里的JSONObject 工具类
3、写入:反序列化成User对象,需要指定特定字节码类,如类.class,即:将json传入,告诉它类型是User,手动告诉字节码
@Test
void test1() {
// 创建对象
User user1 = new User("小花1", 150);
// 手动序列化-字符串
String json = JSONObject.toJSONString(user1);
// 写入数据
stringRedisTemplate.opsForValue().set("name:301", json);
// 获取数据
String jsonUser = stringRedisTemplate.opsForValue().get("name:301");
// 反序列化成User对象,需要指定特定字节码类,如类.class,
// 即:将json传入,告诉它类型是User,手动告诉字节码
User user = JSONObject.parseObject(jsonUser, User.class);
System.out.println("user = " + user);
}十二、RedisTemplate的两种序列化实践方案
方案一:
1、自定义RedisTemplate
2、修改RedisTemplate的序列化器为GenericJackson2JsonRedisSerializer
方案二:
1、使用StringRedisTemplate
2、写入Redis时,手动把对象序列化为JSON
3、读取Redi时,手动把读取到的JSON反序列为对象
两个方案各有利弊!
十三、小知识Hash类型
添加数据用put 。在stringRedisTemplate认为,在java里就相当于是hashMap,那直接用put更合理
@Test
void test2(){
// hash 类型,或其余set list 等类型,都是类似于java里的方法
// 和jedis有点不同,但是都大同小异,
// stringRedisTemplate看来,这样更符合java数据结构
stringRedisTemplate.opsForHash().put("name:205", "name", "独孤小败");
stringRedisTemplate.opsForHash().put("name:205", "age", "101光年");
Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("name:205");
System.out.println("entries = " + entries);
}














 16万+
16万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









