






又发现了华为的一个神器啊 咱来说说哦
华为诺亚提出的刷榜3维人体重建领域的工作CLIFF,在 AGORA 排行榜(SMPL 算法赛道)上排名第一,吓人哈..
论文链接:https://arxiv.org/abs/2208.00571
代码地址:https://github.com/huawei-noah/noah-research/tree/master/CLIFF
前两天,3维人体领域刷榜的的CLIFF(Carrying Location Information in Full Frames)在arxiv上放出了文章。作为ECCV今年的Oral文章,华为诺亚方舟实验室的这项工作用简答优雅的思路取得了相当好的效果,在各个3D人体数据集上都名列榜首,甚至胜过第二名不少。
github上放出来的演示动画(哈哈 csdn能再这上加水印吗 那就厉害了)

人体模型即使被重映射回原图片,整体的动作和行为也显得十分流畅自然。这是如何实现的呢?下面就来领略一下这篇文章的魅力究竟在哪里吧。
研究动机
一个好的研究动机对文章的创新性有着举足轻重的影响。如果它能够发现前人所未发现的问题,并从该问题切入,提出行之有效的解决办法,那么这样的文章大多是有其价值所在的。CLIFF就从计算摄影学的角度,向人体三维重建领域提出了一个不容忽视的问题:三维人体的朝向到底怎么确定?如图,在下面的这个场景中,如果采用惯用的Top-Down算法,截取出人体周围(Bounding Box)回归后,该怎么判断人体的朝向的偏移角?
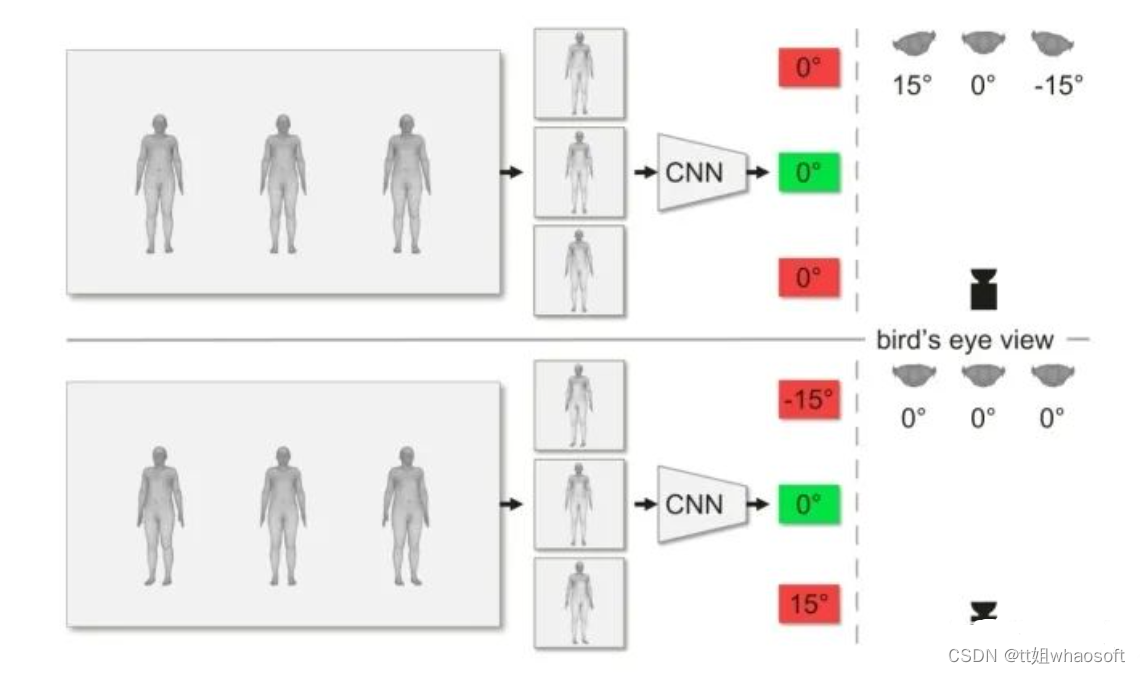
普通的top-down算法:回归出的人体的3维朝向会随着其在图片中的位置而发生偏移
具体来说,上面那张图中假设的是左右的人体在三维世界中相对中心的人体有15°左右的偏移(注意看右上角的俯视图),但由于两个人站在相机的两翼上,因此照片的拍摄角度都是沿着相机为中心的半径方向。也就是说,图片上拎出单个人体来看,他们单独拍出来好像都是各自正对相机的。所以3个bounding box内的结果经过CNN回归后,偏移角回归出来都会是0°,这就和真实世界的15°偏移角产生了偏差。对应的,下面这张图三个人的朝向都是一致的(注意看右下角的俯视图),但因为左右两个人的朝向并不是沿着半径方向,所以拍出来的图片中单独看上去会朝外歪出去15°。所以Top-Down办法单独截取出人体的bounding box后,后续的流程并不知道这个bounding box是在原图的哪个位置截取出来的,只能根据截取出的图片本身不完整的信息,判断出左右两个人各自有15°的偏向角。这也和真实世界会产生偏差。一言以概之,就是说:
在三维世界映射到二维的时候,相机拍摄出来的物体朝向会向外侧扭曲,扭曲的程度则由物体在画面上的相对位置决定。
而Top-Down办法将每个人体单独用Bounding Box框出来后,回归时不知道其在原图片的哪个位置上,因此对物体的扭曲程度也就无从判断(Agnostic)了。这种对全局信息的无知显然是不利于回归的。
问题解决
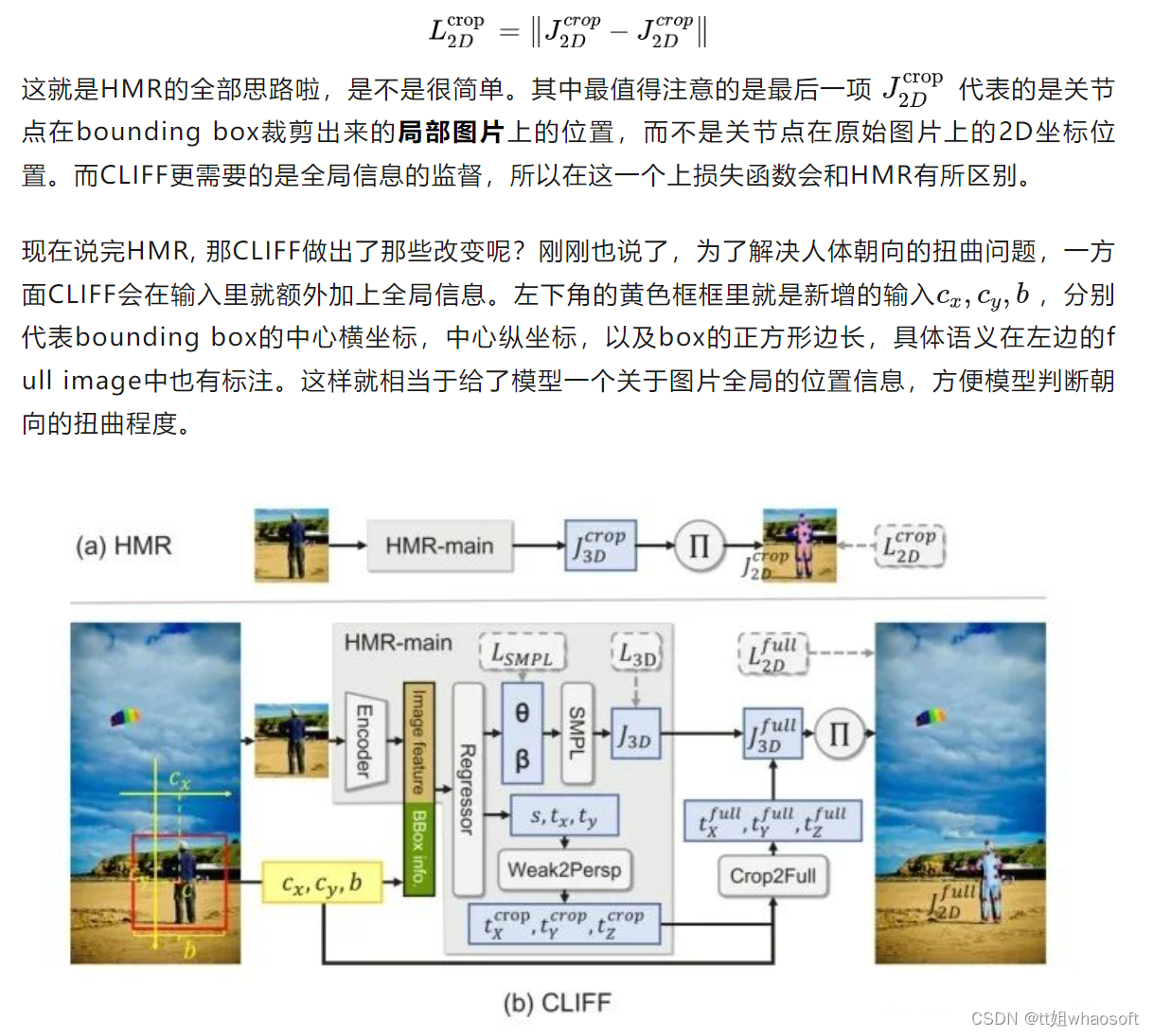
明确了要解决的问题后,作者给出的解决思路也是相当简洁而优雅的。不是缺少全局信息吗?好,那我一方面在输入里就额外加上全局信息,另一方面损失函数再强迫模型学到全局信息,不就解决这个问题了吗?
模型整体的思路框架依然遵循2017年的经典框架HMR,为了更清楚地了解到CLIFF做出的改进,这里也简单提一下HMR的大概思路。
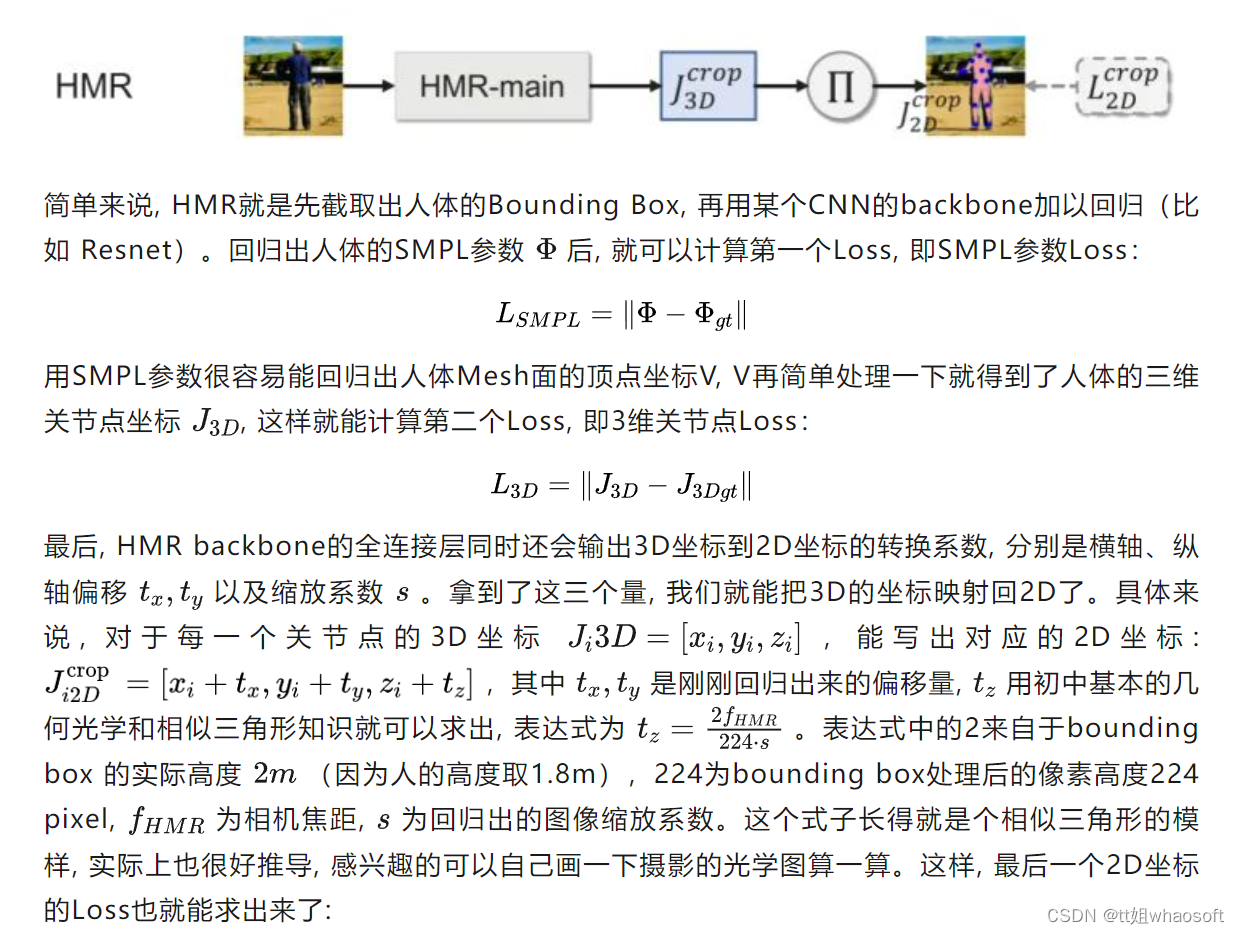

最终效果
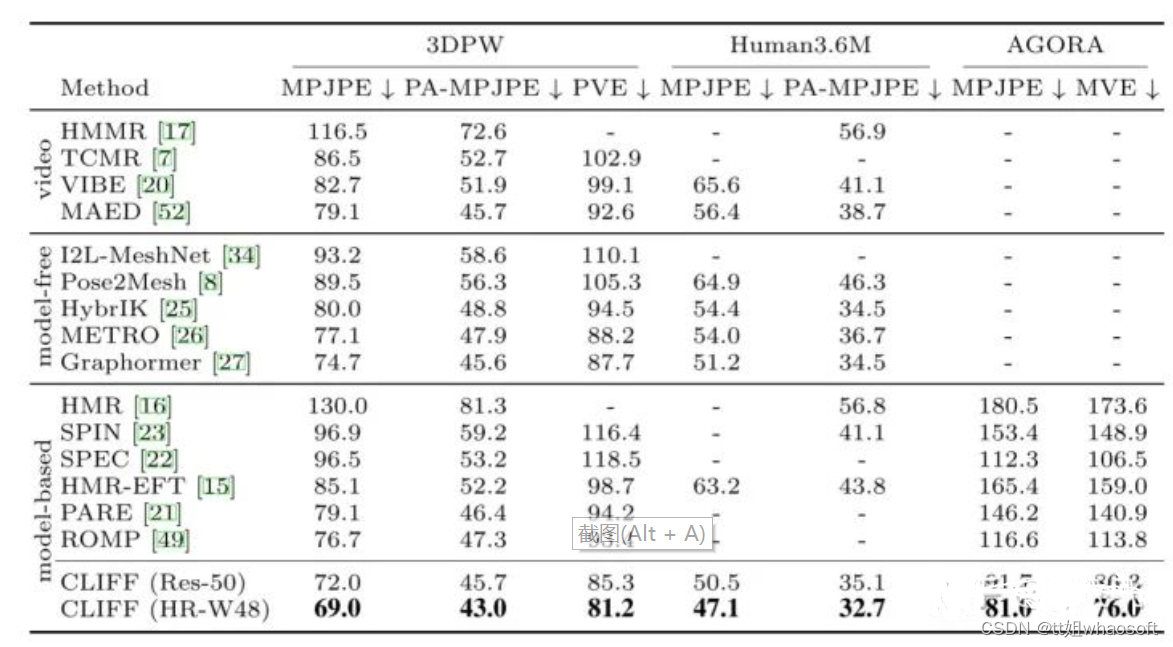
最后的最后,简单讲讲CLIFF的结果吧。其在几个主要的3D人体数据集上都取得相当不错的效果。而Ablation Study on Human3.6m则显示出上面两个创新点各自的benefit主要在哪里:

CLIFF能取得如此好的成绩,也离不开其对数据集的扩充,也就是文中提到的制作伪监督数据集。这方面的工作可以参考Facebook的开山之作EFT(https://link.zhihu.com/?target=https%3A//github.com/facebookresearch/eft),CLIFF几乎没有对其做出太多理论上的改进,所以本篇文章也就不将其纳入文章创新点的介绍啦。如果有同学希望介绍的话可以留言一下,抽空我也把EFT的介绍写掉。















 7521
7521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









