






之前分享的文章中提到,Graph RAG的核心链路分如下三个阶段:
- 索引(三元组抽取):通过LLM服务实现文档的三元组提取,写入图数据库。
- 检索(子图召回):通过LLM服务实现查询的关键词提取和泛化(大小写、别称、同义词等),并基于关键词实现子图遍历(DFS/BFS),搜索N跳以内的局部子图。
- 生成(子图上下文):将局部子图数据格式化为文本,作为上下文和问题一起提交给大模型处理。
实际上三个阶段也可以被简化合并为两个阶段:内容索引阶段和检索生成阶段。我们就这两个大的阶段分别讨论Graph RAG后续可能的优化方向和思路。
1 内容索引阶段
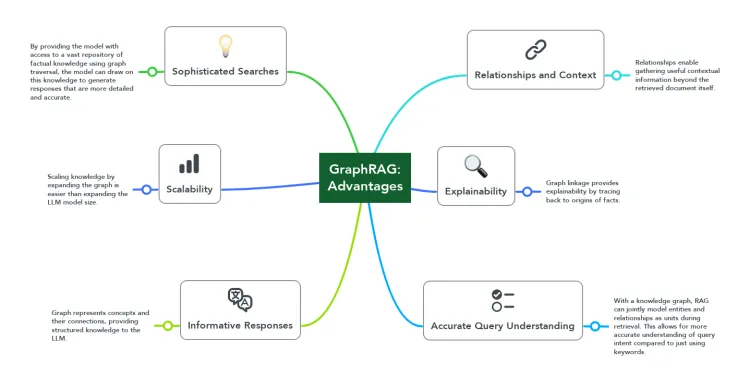
Graph RAG的内容索引阶段主要目标便是构建高质量的知识图谱,值得继续探索的有以下方向:
- 图谱元数据:从文本到知识图谱,是从非结构化信息到结构化信息的转换的过程,虽然图一直被当做半结构化数据,但有结构的带标签属性的图谱除了有利于图存储系统的性能优化,还可以协助大模型更好地理解知识图谱的语义,帮助其生成更准确的查询。
- 知识抽取微调:通用大模型在三元组的识别上实际测试下来仍达不到理想预期,针对知识抽取的微调模型反而表现出更好地效果。
- 图社区总结:通过构建知识图谱时生成图社区摘要,以解决知识图谱在面向总结性查询时“束手无策”的问题。另外,同时结合图社区总结与子图明细可以生成更高质量的上下文。
- 多模态知识图谱:多模态知识图谱可以大幅扩展Graph RAG知识库的内容丰富度,对客观世界的数据更加友好。Graph RAG可以借助于MMKG(Multi-modal Knowledge Graph)和MLLM(Multi-modal Large Language Model)实现更全面的多模态RAG能力。
- 混合存储:同时使用向量/图等多种存储系统,结合传统RAG和Graph各自的优点,组成混合RAG。GraphRAG: Design Patterns, Challenges, Recommendations这篇论文中提出了多种Graph RAG架构,如图学习语义聚类、图谱向量双上下文增强、向量增强图谱搜索、混合检索、图谱增强向量搜索等,可以充分利用不同存储的优势提升检索质量。
2 检索生成阶段
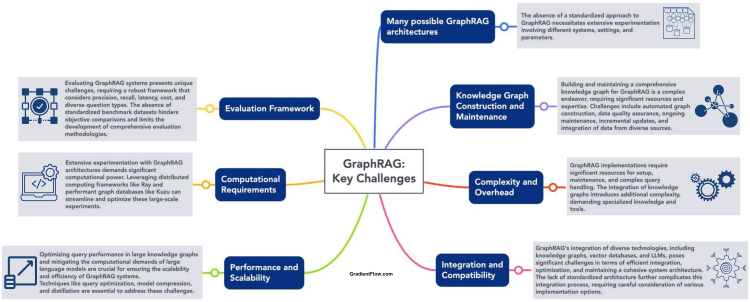
Graph RAG的检索生成阶段主要目标便是从知识图谱上召回高质量上下文,值得继续探索的有以下方向:
- 图语言微调:使用自然语言在知识图谱上做召回,除了基本的关键词搜索方式,还可以尝试使用图查询语言微调模型,直接将自然语言翻译为图查询语句,这里需要结合图谱的元数据以获得更准确的翻译结果。
- 混合RAG:这部分与混合存储是一体的,借助于底层的向量/图/全文索引,结合关键词/自然语言/图语言多种检索形式,针对不同的业务场景,探索高质量Graph RAG上下文的构建。
- 测试验证:Graph RAG的测试和验证可以参考传统RAG的Benchmark方案,如RAGAS、ARES、RECALL、RGB、CRUD-RAG等。
- RAG智能体:RAG其实是Agent的简化形式(知识库可以看到Agent的检索工具),同时RAG对记忆和规划能力的集成诉求(如RAT/RoG等),因此未来RAG向带有记忆和规划能力的智能体架构演进几乎是必然趋势。另外,Agent自身需要的长期记忆存储也会反向依赖RAG的知识库,所以RAG与Agent其实是相辅相成、互相促进的。
3 结语
通过探讨Graph RAG未来的优化与演进方向,总结了内容索引和检索生成阶段的不同改进思路,以及RAG向Agent架构的演化趋势。
论文题目:GraphRAG: Design Patterns, Challenges, Recommendations
论文链接:https://gradientflow.com/graphrag-design-patterns-challenges-recommendations/
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!

精彩回顾
2. 图检索增强生成--GRAG(GRAG: Graph Retrieval-Augmented Generation 论文链接:https://arxiv.org/abs/2405.16506 )


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









