







🚀 打破次元壁:当Transformer遇见句子胶囊
在人工智能领域,大型语言模型(LLM)如同饕餮般吞噬着计算资源——从2018年BERT的亿级参数,到2022年Switch Transformer的万亿规模,模型膨胀速度堪比宇宙大爆炸。但这种增长背后是惊人的硬件成本与能源消耗:训练一个GPT-3模型所需的电力,足以让特斯拉电动车绕地球行驶600圈!
传统优化手段如模型剪枝、量化压缩,就像给巨人穿紧身衣,虽能暂时瘦身却牺牲了灵活性。直到苏黎世联邦理工学院与NVIDIA的研究团队提出GPTHF(Generative Pretrained Thoughtformer),这场游戏规则被彻底改写。他们将目光投向语言的基本单元——句子,用"句子胶囊"替代传统子词(sub-word)标记,实现了10倍计算效率提升与3倍推理加速的突破。
传统模型像处理散装快递,每个字符都要单独打包;GPTHF则像智能分拣系统,将整句话压缩成标准集装箱
🛠️ 精妙设计:双引擎驱动的压缩流水线
GPTHF的核心创新在于分层处理架构:
- 字符级编码器(wlt_encoder)如同精密扫描仪,用块注意力机制(Block Attention Mask)将句子内的字符关联封装成胶囊
- 句子级处理器(slt_body)则像空中交通管制系统,协调各个句子胶囊的语义航线
# 动态块注意力伪代码
def block_attention(sentences):
for i, sent in enumerate(sentences):
# 仅允许同句内字符交互
mask = create_block_mask(sent, i)
apply_attention(sent, mask)
这种设计带来三重优势:
- 语义完整性:避免跨句信息污染
- 计算经济性:处理长文本时,已完成句子可缓存复用
- 架构兼容性:保留GPT核心结构,仅修改5%的注意力机制
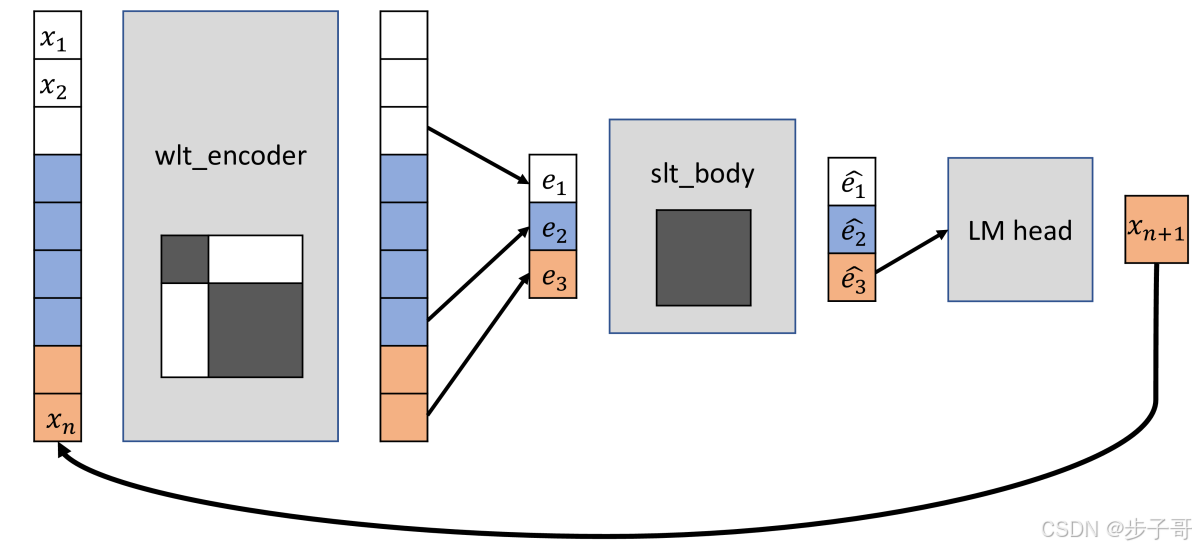
如同工厂流水线:原料(字符)→ 胶囊封装 → 物流调度 → 成品输出
⚡ 速度与激情:效率提升的魔法公式
GPTHF的"快银模式"(Fast Generation Algorithm)堪称神来之笔。当生成新句子时,系统会自动跳过已处理的句子胶囊,就像地铁快车甩站通过已停靠站点。实验数据显示:
| 场景 | FLOPs效率提升 | 推理加速 |
|---|---|---|
| 500词上文+20新词 | 9.18倍 | 2.99倍 |
| 批量处理(32组) | 2.93倍 | 2.27倍 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











