







人类与物体的每一次互动,既是一场无声的舞蹈,也是物理定律与直觉认知的交织。想象一下,一个人挥动吉他、举起杠铃或执麦演讲,这些场景不仅仅停留在二维图像中,而正悄然在三维世界中演绎出新的可能性。最新的研究提出了一种“零样本”方法:无需依赖昂贵且稀缺的 3D 人—物体交互数据,借助预训练的多模态模型,我们可以生成既具备语义多样性,又符合物理规律的真实交互场景。本文将带领大家走进这一跨越时空、技术与艺术交融的世界。
🌍 从二维到三维:开启人—物交互的零样本探索
传统的 3D 人—物体交互生成常因数据获取困难、成本高昂而陷入单一场景的局限。如今,海量的二维图像、视频以及文本数据为我们打开了一扇全新之门。受 DreamFusion 等方法启发,研究者们发现:通过利用 2D 扩散模型生成图像,再结合预训练的人体姿态提取模型与多视角 3D 对齐算法,我们能够“启迪”出三维交互的端倪。
这种零样本方法,正如在广阔大海中利用星光指引方向般,从远处的二维星辰中捕捉到构建三维世界的灵感。文章中详细描述了如何利用 ControlNet 模型将二维人体关键帧作为条件,实现 temporally consistent 的 2D HOI 图像序列,再通过预训练的姿态估计模型如 TRAM 和 SMPLer-X,将这些帧“提升”成为粗略的 3D 人体关键帧,实现动态交互的初步构造。

🎨 二维交互灵感:图像与视频的奇妙魔法
人类不仅通过动作表演交互艺术,二维图像和视频也为这种艺术注入了无限生机。论文提出两大模块:
- 生成二维 HOI 图像
- 生成二维 HOI 视频
首先,利用经过 ControlNet 调控的 2D 扩散模型,我们能根据文本输入(例如,“一位男士正在弹吉他”)生成一系列连续且具有稳定时序一致性的二维图像,这些图像不仅包含人体的动态姿态,还隐含着物体在空间中的合理摆放。
视频生成方面,当前的 Kling 与 SORA 等模型展示出令人惊讶的视频合成能力。研究人员提出,通过使用文本同时辅以起始帧条件,不仅能更好地控制摄像机视角,还能确保生成的视频中物体与人体的互动区域始终处于关注焦点内。均匀采样关键帧,则为后续 3D 重构提供了坚实基础。
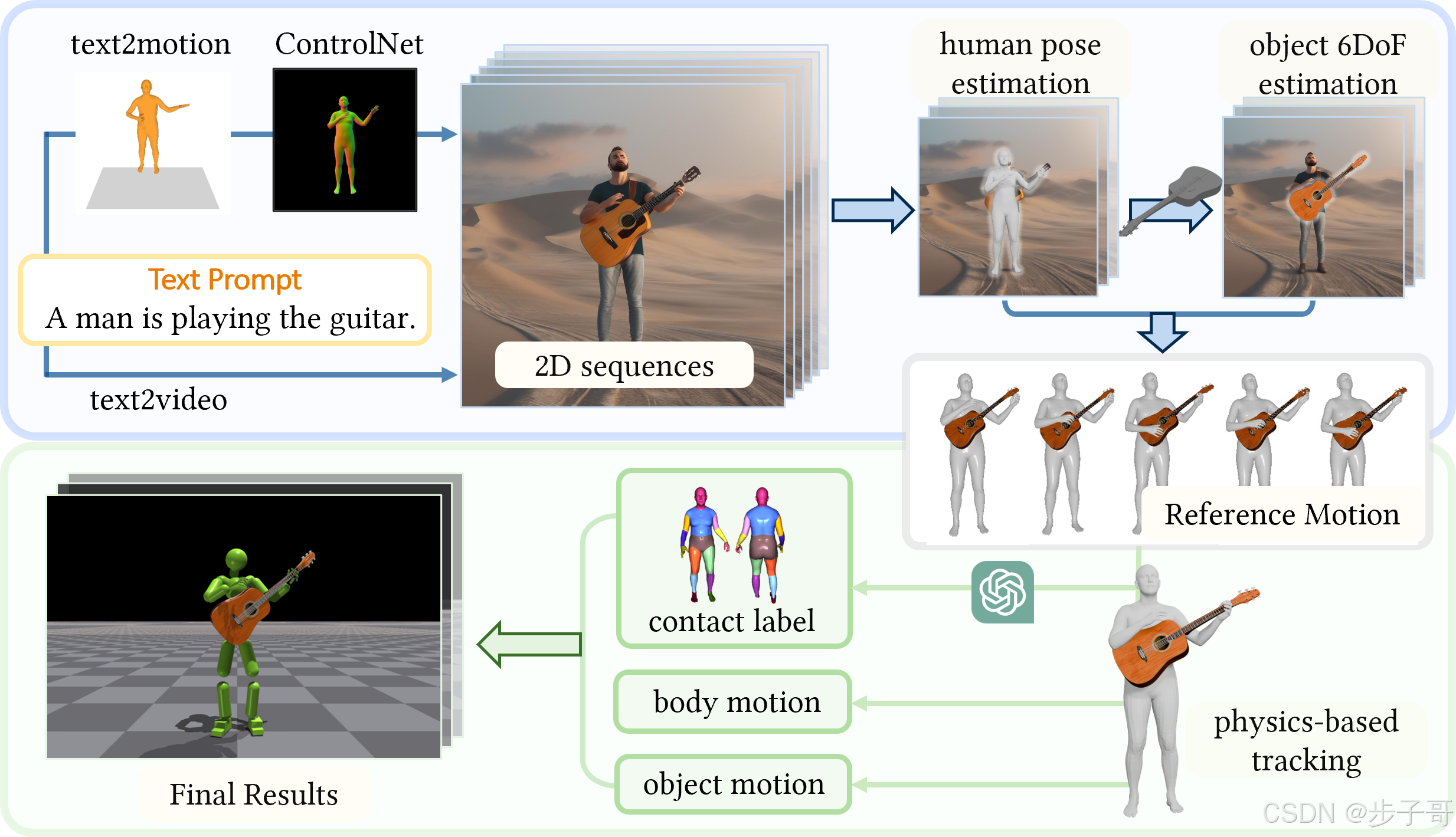
🧍♂️ 人类动作再造:从文本到精准姿态的蜕变
设想一下,一个男士在弹吉他,但最初由文本到动作生成的结果往往缺乏对物体(吉他)存在的充分感知。为了解决这一问题,研究团队在二维 HOI 图像中提取人体姿态,再使用 TRAM 模型提取全局运动、以及 SMPLer-X 对局部运动进行修正。这样一来,由文本生成的初始人体动作不仅在大致运动轨迹上无可挑剔,更在细节上契合与物体的交互需要。
正如两幅立体图像可以构成一个立体影像,这种通过多模型协同得到的“修正”人体姿态,使得人和物的交互更为自然——例如,双手与吉他之间保持良好的接触距离,为后续赋予真实感打下基础。
🔍 物体姿态的魔法:6-DoF 估计与语义对应
人体动作处理好了,关键还在于如何将物体放入这幅画卷中。考虑到 2D HOI 图像与物体模板在几何外观上可能存在差异,论文中提出了通用的类别级物体 6-DoF 估计方法。这一方法采用了两阶段优化流程:
-
语义对应提取:利用预训练的 2D 视觉模型(如 DinoV2),提取物体模板与 HOI 图像间的密集特征描述。通过从 24 个视角渲染物体模板,结合双向匹配算法及 RANSAC 筛选出稳健外点,从而求解 Perspective-n-Point(PnP)问题,获得初步的 6-DoF 姿态。
-
可微渲染优化:利用 PyTorch3D 构建的可微渲染器进一步细化物体的姿态,通过最小化物体轮廓与深度信息的误差(公式如下),确保生成结果在物理尺度上与人体保持合理关系:
L s i l = ∣ S − S ^ ∣ + λ o b j e c t ∣ S o − S o ^ ∣ L_{sil} = \left| \mathcal{S} - \hat{\mathcal{S}} \right| + \lambda_{object}\left|\mathcal{S}_o - \hat{\mathcal{S}_o}\right| Lsil= S−S^ +λobject So−So
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











