







在当今教育技术快速发展的时代,自动作文评分(AES)作为人工智能在教育评估中的一大亮点,正迎来全新的突破。想象一下,一个模型不仅能评分已知题目的作文,还能凭借其语法和结构理解能力,精准评估全新题目的写作水平——这正是我们今天探讨的主题。本文将带您走进“语法感知跨题目作文评分”(Grammar-aware Cross-Prompt Automated Essay Scoring,简称GAPS)的世界,解密这一领域的创新技术和内部机制,像讲一段动人心弦的探险故事般,揭示如何利用语法纠错、知识共享和多层次编码,实现作文评分的跨题目泛化。
🌍 开篇序言:教育评估的技术革命
自从自动作文评分系统问世以来,人们便希望借助这一技术解决人工评分所伴随的主观性和高成本问题。然而,早期的AES系统主要针对特定题目进行训练,对于全新题目的适应能力大打折扣。近年来,随着深度学习技术的飞速发展,越来越多的研究开始关注如何构建“跨题目”评分系统,也就是说,希望能评估从未见过题目的作文,这便是跨题目AES的背景。传统方法虽然在利用分数和题目无关的特征构建作文表示方面已有一定进展,但如何捕捉作文中更普适的语法和结构特征,始终是一个颇具挑战的问题。
正因如此,研究者们提出了一种崭新的思路:在评分前先进行语法错误纠正,将作文原文与纠正后的文本作为双输入,利用二者之间的互补信息获得更具普适性的作文表示。正如一名经验丰富的教师在批改作文时,既关注学生原始表达的思路,也会参考改正后的内容判断语法水平,这种直接利用语法纠正信息的方法便成为技术革新的重要驱动。本文将深入解析这一方法的工作原理与实验验证,展示其在各评分指标上的显著提升效果。
📚 相关研究的迭代与跨界探索
过去的研究中,自动作文评分主要借助多任务学习、对比学习及提示感知网络等方法,力图构建通用的作文表示。例如,部分研究利用句法标注、类型预测以及情感分析等辅助任务来提高模型评分准确性。而另一部分工作则通过设计对比损失或提示网络,来取得题目不可知的评分效果。
相比之下,“语法感知”方法的独特之处在于,它直接利用预训练的语法纠错模型(例如基于T5的GEC模型)对原始作文文本进行纠正,并在纠正结果中嵌入特定的纠正标签,如将漏写的单词以“ M: the ”形式标注。这样的设计不仅能够加强模型对文本关键语法错误的敏感度,还为后续评分提供了更具语法一致性的输入。与现有的辅助训练方法相比,语法感知方法大大降低了训练负担,同时释放出更丰富的语法信息,有助于生成具有更强泛化能力的作文表示。
✨ 技术内部揭秘:GAPS 的核心构架
GAPS 方法总体分为两大步骤:首先是【作文纠正】;随后是【语法感知的作文评分】。这两部分通过精心设计的模型结构和层次化的编码机制无缝衔接,实现了对原文与纠正文本的综合理解。
🖋️ 作文纠正:从错误到改进
在第一步中,我们采用预训练的 T5-based 语法纠错模型(参见 Rothe et al. 2021),系统自动识别原始作文中的多种语法错误,并输出纠正后的文本。这里,我们根据 ERRANT 错误标注工具(Bryant et al. 2017)将错误分为三类:
- “Missing (M)”:缺失必要的词汇;
- “Replacement ®”:错误替换的词汇;
- “Unnecessary (U)”:多余的、不合适的词汇。
对于每一种错误,系统不仅输出改正后的词汇,还在文本中嵌入特定标签,用以明确指出修正内容。例如,原文中漏写的定冠词“the”便会被标记为“ M: the ”。这种显式标注方法使得模型在后续编码过程中能够更专注于语法细节的学习。
🔍 语法感知的作文评分模型
在评分阶段,GAPS 同时对原作文及语法纠正后的文本进行编码。具体来说,每一种文本都由独立但结构相同的编码器处理,这种“双通道”结构确保了两份信息在初始阶段就能被单独学习,便于后续的信息融合。编码器采用层次化设计,即将作文拆分成较小的句子,再利用一维卷积层、注意力池化以及多头自注意力机制对每个句子生成局部表示。
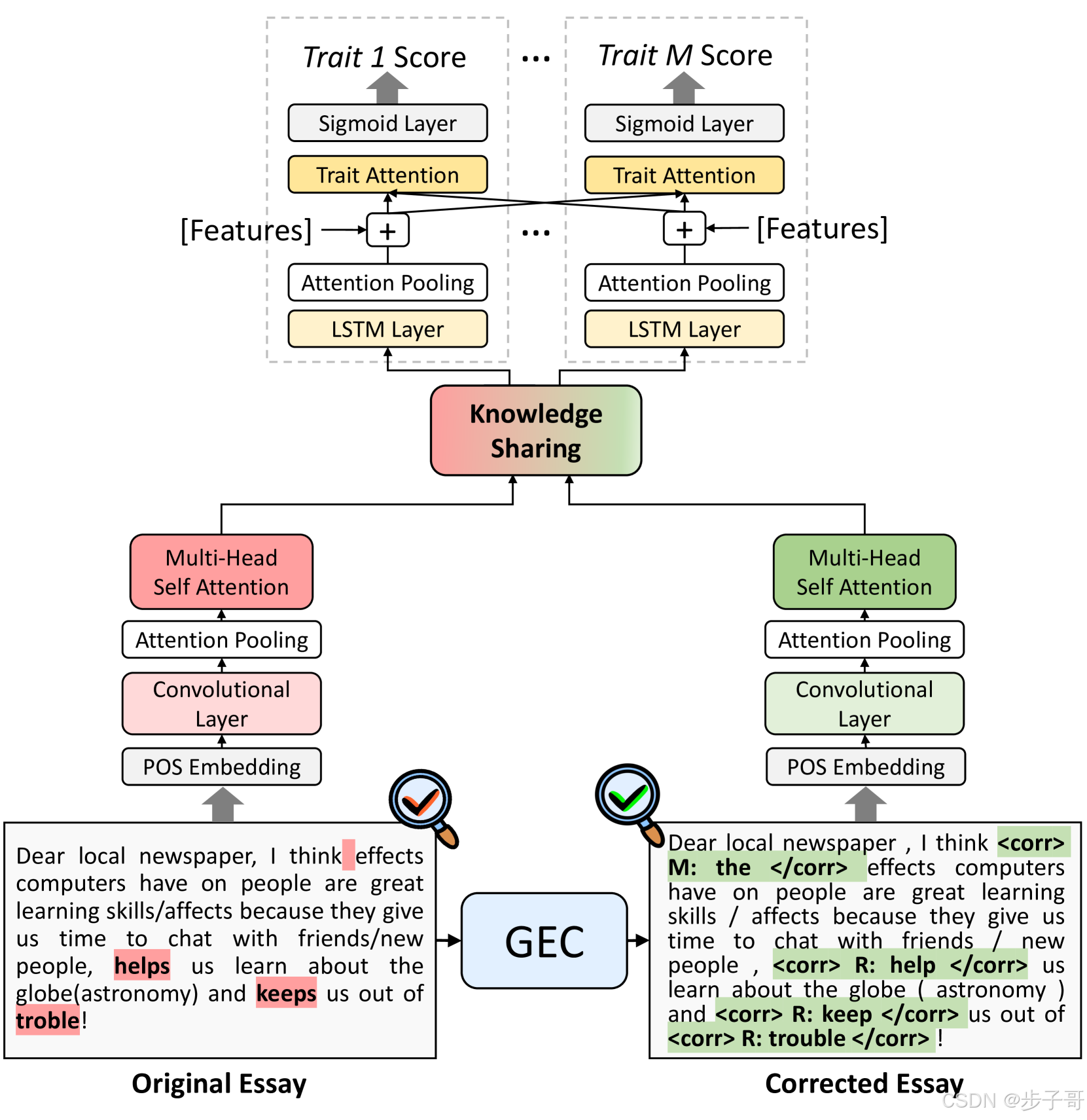
例如,在句子编码过程中,我们首先通过词性嵌入(POS embedding)得到词汇在句子中的语法表现,然后利用一维卷积提取局部特征,接着通过注意力池化将这些局部特征整合为句子的全局表示。公式上,句子级表示的计算可以简化为:
s = Pooling a t t ( [ c 1 : c w ] ) \mathbf{s} = \text{Pooling}_{att}([c_1: c_w]) s=Poolingatt([c1:cw])
其中, c 1 , … , c w c_1, \ldots, c_w c1,…,cw 分别表示句子中各词的局部特征, Pooling a t t \text{Pooling}_{att} Poolingatt 表示注意力池化函数,通过这种方式获得的句子表示,既包含了语义信息,又结合了语法结构特征。
紧接着,为了更高效地捕捉作文中跨句子的依赖关系,模型采用了多头自注意力机制,其核心计算公式为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











