







在人工智能的世界里,大语言模型(LLMs)就像是天赋异禀的诗人,能写、能答、能推理,但却常常“我行我素”。我们想让它写诗,它却讲起了哲学;我们想让它解题,它却开始“发散思维”。如何让这位“天才”听话、懂事、效率高?这正是本文的主角——CoLA(Controlling Large Language Models with Latent Actions)——要解决的问题。
本文将带你走进 CoLA 的世界,看看它如何用“潜意识的动作”来控制语言模型的行为,让它既聪明又听话。
🧠 潜意识的操控术:什么是“隐动作”?
想象你在开车,手握方向盘,脚踩油门,但你并不需要每秒都告诉自己“现在要转动 3 度”“现在要加速 0.1 米/秒²”。这些动作是你大脑中“潜意识”的产物。CoLA 的核心思想正是如此:与其让语言模型每次都在庞大的词汇表中“逐字选词”,不如让它先在一个更小、更抽象的“隐动作空间”中做决策,再由这些动作引导生成具体的词。
这就像是给语言模型装上了一个“潜意识控制器”,让它先决定“我要表达什么意图”,再由语言世界模型(Language World Model)来翻译成具体的语言输出。
🏗️ CoLA 的三驾马车:世界模型、策略模型、逆动力学模型
CoLA 的架构可以说是“分工明确、各司其职”,主要由三大模块组成:
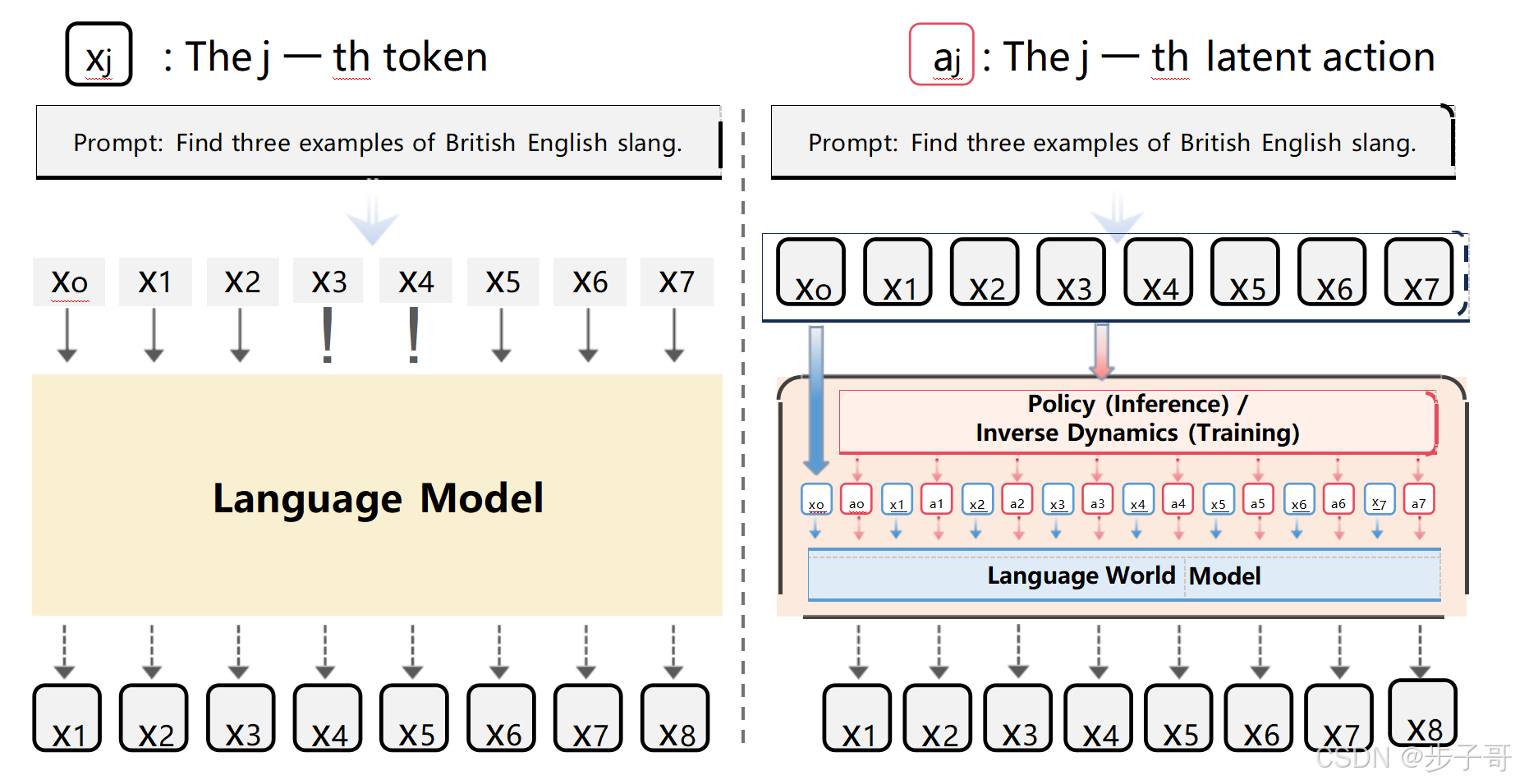
🌍 语言世界模型(fworld)
这是一个经过改造的预训练语言模型,它不仅接受上下文,还接受“隐动作”作为输入。它的任务是:根据当前上下文和隐动作,预测下一个 token。换句话说,它是语言生成的“执行器”。
🎯 策略模型(π)
策略模型是“决策者”,它根据当前上下文,选择一个隐动作。这个动作不是具体的词,而是一个抽象的“意图编码”,比如“继续解释”“开始列举”“转折一下”等。
🔍 逆动力学模型(finverse)
这是训练阶段的“侦探”,它观察上下文和下一个 token,反推出“当时的隐动作”是什么。这个模块帮助我们从大量文本中“反向学习”出隐动作空间。
🧩 技术细节:CoLA 使用了一个大小为 N=64 的 codebook,每个 code 表示一个离散的隐动作。这个设计灵感来自 VQ-VAE,但为了避免“词汇坍缩”,CoLA 采用了更稳定的“直接动作分配”方法。
🧪 训练三部曲:从潜意识到行为习惯
CoLA 的训练过程分为三个阶段,就像是训练一个新员工从“观察学习”到“独立工作”:
1️⃣ 构建隐动作空间
使用大规模语料(如 Slimpajama、ProofPile2 等),训练逆动力学模型和语言世界模型。目标是让模型学会“在什么情况下,应该选择什么隐动作”。
训练目标如下:
L pre1 = L predict + β L reg L_{\text{pre1}} = L_{\text{predict}} + \beta L_{\text{reg}} Lpre1=Lpredict+βLreg
其中 L predict L_{\text{predict}} Lpredict 是预测下一个 token 的损失, L reg L_{\text{reg}} Lreg 是防止 codebook 坍缩的正则项。
2️⃣ 策略模型模仿学习(Behavior Cloning)
让策略模型模仿逆动力学模型的输出,学会“在这个上下文下,应该选择哪个隐动作”。
L pre2 = − E x 1 : T ∼ D pre ∑ t = 1 T − 1 log π ( a t ∣ x 1 : t ) L_{\text{pre2}} = -\mathbb{E}_{x_{1:T} \sim D_{\text{pre}}} \sum_{t=1}^{T-1} \log \pi(a_t | x_{1:t}) L
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











