






在人工智能的世界里,大型语言模型(LLMs)就像一群才华横溢却偶尔迷糊的学生。它们能在复杂的数学考试中拿高分,却可能在简单的加法题上栽跟头。这不禁让人好奇:这些号称“博士级”的模型,究竟是真正理解了数学的奥秘,还是只是靠着一本巨大的“记忆笔记本”蒙混过关?在一篇引人注目的研究中,来自浙江大学和西湖大学的学者们用小学加法这把“手术刀”,精准地解剖了LLMs的数学能力,试图回答一个核心问题:它们是算法大师,还是记忆的奴隶?
这篇文章将带你走进这场学术探险。我们会从最简单的两位数加法开始,一路探索到高达 2 64 2^{64} 264 的庞大数字,再用奇奇怪怪的符号替换数字,看看这些模型还能否淡定应对。我们会用通俗的语言和有趣的比喻,揭开研究中的每一个发现,同时让你感受到科学探索的乐趣。准备好了吗?让我们一起出发!
🌟 从高分到翻车:LLMs的数学悖论
想象一下,你有一个超级聪明的朋友,能轻松解出微积分难题,却在计算“2+2”时挠头。这正是LLMs的现状。研究者们发现,尽管这些模型在像GSM8k和MATH-500这样的复杂数学基准测试中表现惊艳,但在最基础的两位数加法上,它们却露出马脚。比如,Claude-3.5-sonnet在普通数字加法中能拿到99.81%的正确率,可一旦把数字换成符号(比如7变成“y”),正确率暴跌到7.51%。这就好比一个钢琴大师,换了架钢琴就连简单的《小星星》都弹不下了。
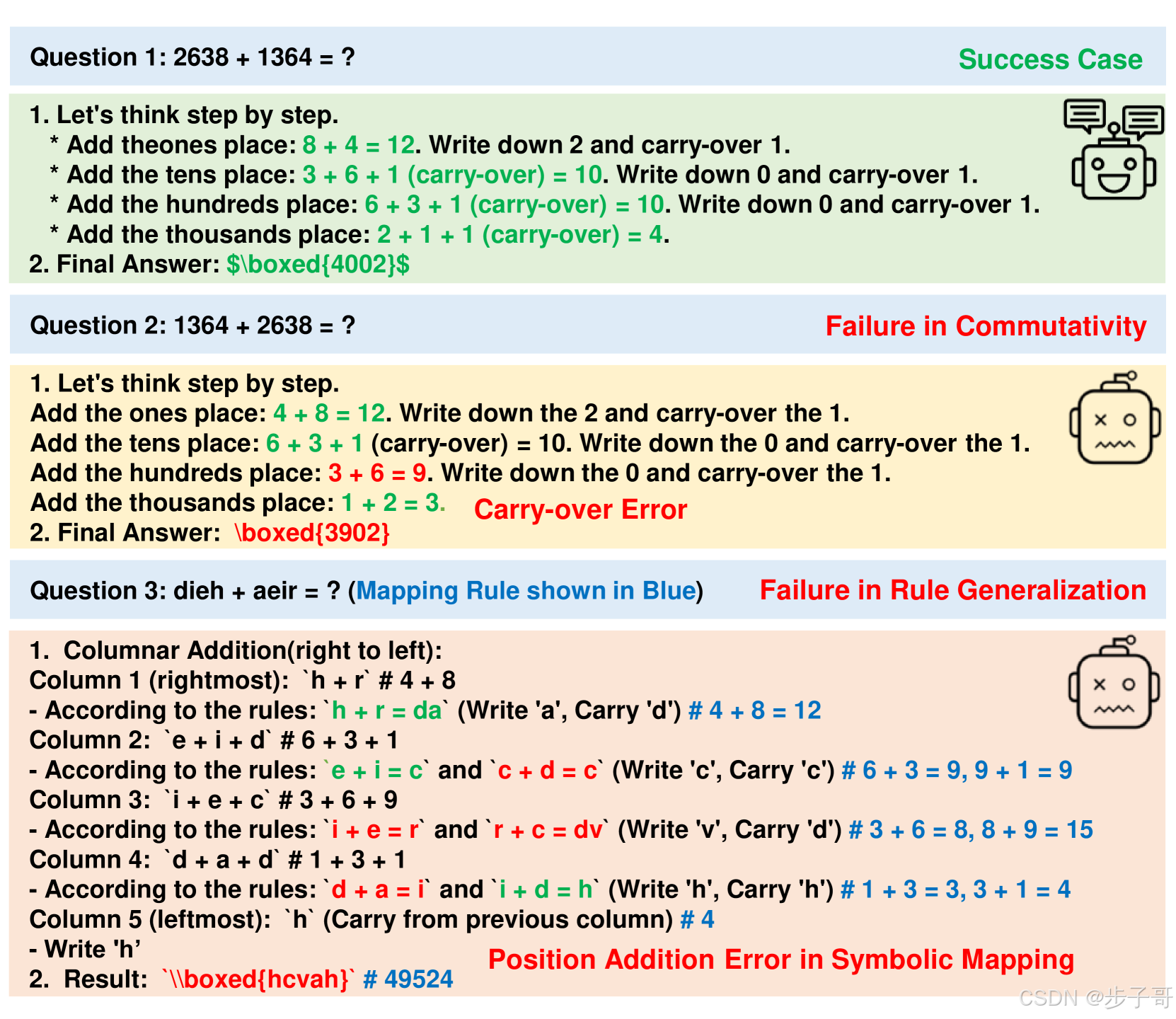
为什么会这样?研究者们提出了一个大胆的假设:LLMs可能不是真的“懂”数学,而是靠记忆训练数据中的模式来应付问题。为了验证这个猜想,他们设计了一个简单却巧妙的实验:用小学加法测试模型的规则学习能力。他们不仅让模型计算 A + B A+B A+B,还故意调换顺序算 B + A B+A B+A,看看是否符合加法的交换律( A + B = B + A A+B=B+A A+B=B+A)。结果令人震惊:许多模型在这最基本的性质上频频出错,比如Llama3.3-70b-It在1700多次测试中出现了 A + B ≠ B + A A+B \neq B+A A+B=B+A 的情况。这就好比一个厨师炒菜时,盐和糖放的顺序不同,结果味道完全变了样。
📏 数字的试炼:从两位到亿万
为了摸清LLMs的底线,研究者们设计了一个“数字马拉松”。他们让模型从简单的两位数加法(0到99)开始,逐步增加难度,一直到 2 64 2^{64} 264 这样的大怪兽。这相当于从“跑步热身”升级到“攀登珠穆朗玛峰”。如果模型真的掌握了加法规则,正确率应该随着数字变大而平稳下降,就像一个熟练的登山者即使疲惫也能保持节奏。可现实却像过山车一样刺激。
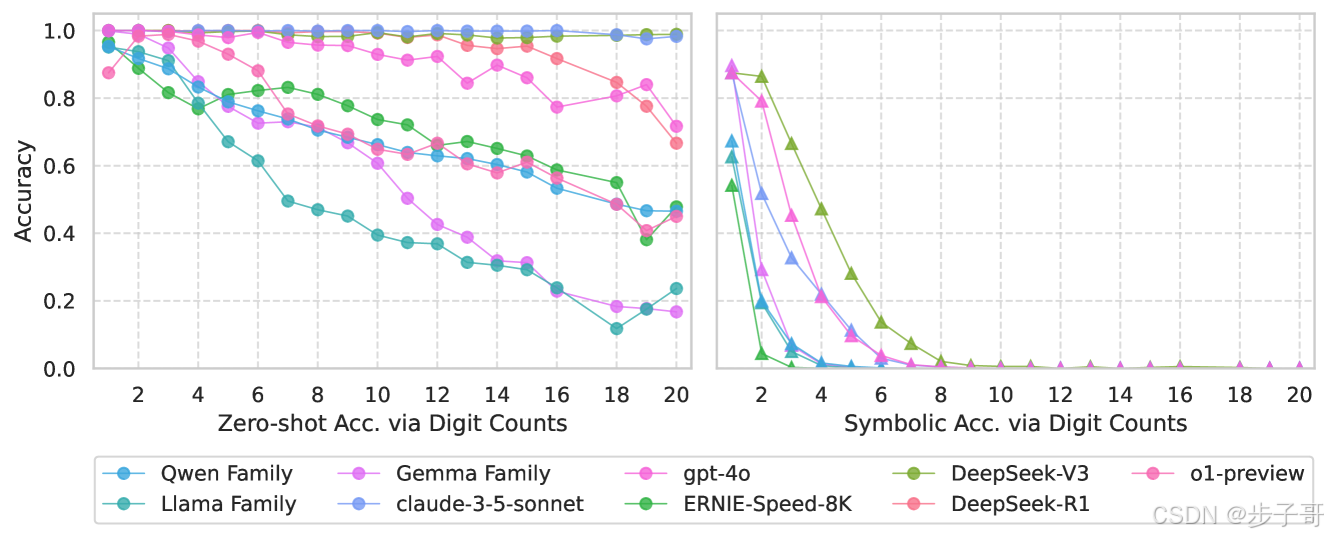
数据显示,许多模型的正确率并不是稳步下降,而是忽上忽下。比如,在普通数字加法中,有些模型在中等位数时表现更好,到了更高位数反而掉链子。这种“非单调性”就像你在玩跳绳,刚跳得好好的,突然被绳子绊了一下。研究者认为,这可能是模型在训练时记住了一些常见数字组合,但面对陌生的“大个子”时,就只能靠猜了。
更绝的是,他们还测试了模型对“进位”的处理能力。加法中最核心的规则之一是:当某一位的和超过9时,要把进位加到下一位。可在实验中,模型对进位的掌握也漏洞百出。表格显示,即使在普通数字加法中,进位正确率也远低于预期,而一旦换成符号,表现更是惨不忍睹。这就像一个会计算账,把小数点弄丢了,结果账本乱成一团。
🔤 符号大冒险:从数字到“字母汤”
如果说数字加法是LLMs的舒适区,那符号加法就是它们的噩梦。研究者们突发奇想,把0到9这十个数字换成了随机的符号,比如 7 → y 7 \rightarrow y 7→y, 9 → c 9 \rightarrow c 9→c,然后让模型继续做加法。这就像把一个只会读英文的人丢到法语课堂,看他还能不能蒙对答案。
结果毫不意外:模型集体“翻车”。在普通数字加法中,顶级模型如DeepSeek-V3能拿到98.92%的正确率,可到了符号加法,正确率跌到16.14%。更夸张的是ERNIE-Speed,从73.84%直接跌到0.28%,几乎全军覆没。这就好比一个导航仪,平时靠地图带路,可一旦地图被涂成乱码,它就彻底迷路了。
为什么会这样?研究者分析,这说明模型对加法的理解是“表面的”,依赖于熟悉的数字模式。一旦换成陌生的符号,它们就无法把学过的规则迁移过去。这就像一个只会背单词的学生,换了语言环境就哑口无言。实验还发现,符号加法的正确率随着位数增加而单调下降,完全不像数字加法那样“跳跃”,进一步证明模型在数字任务中靠的是记忆,而非真正的算法思维。
📚 教它规则,反而更糟?
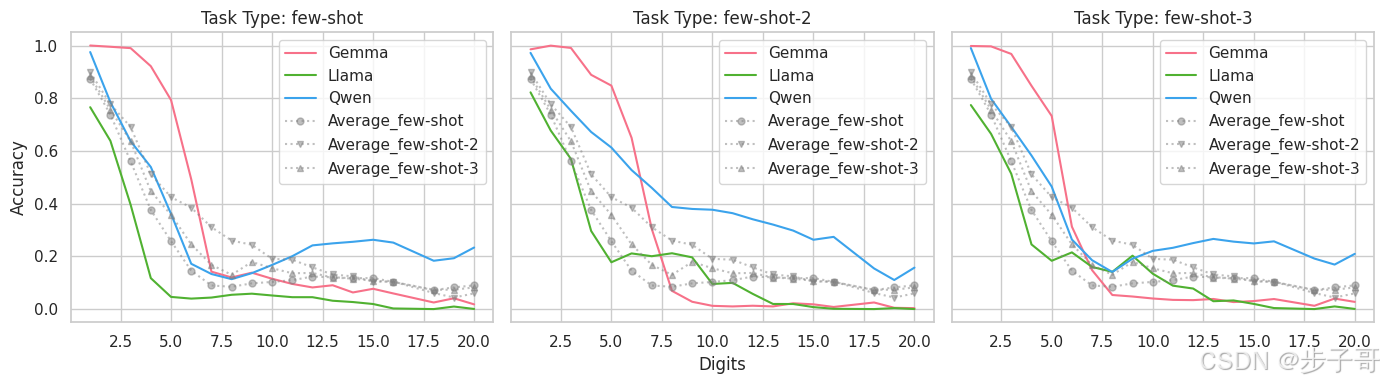
看到模型在符号加法中如此狼狈,你可能会想:那干脆直接告诉它加法规则不就好了吗?研究者们也这么想,于是他们试着给模型“补课”。他们设计了几种提示方式:一是直接提供加法规则和几个例子(few-shot),二是让模型先解释加法原理再计算(explain-and-do)。结果却让人大跌眼镜。
在few-shot条件下,模型的表现不仅没变好,反而平均下降了81.2%。比如Qwen2-7b-it在普通加法中正确率是62.94%,可加上规则提示后,进位正确率暴跌到28.36%。这就像一个学生,本来能凭感觉做题,可老师一讲规则,他反而懵了。研究者推测,这可能是因为模型的内部计算方式和人类定义的规则“八字不合”,强行塞进去反而打乱了它的节奏。
相比之下,explain-and-do的方式稍微好些,正确率基本维持在零样本(zero-shot)的水平。这说明,当模型用自己的语言“讲故事”时,它还能靠原来的套路撑场面。可一旦面对外部规则,它们就像被套上紧箍咒的孙悟空,完全使不上劲。
🧠 调教模型:从填鸭到启发
既然直接教规则不管用,那能不能通过“调教”让模型真正学会加法呢?研究者们尝试了对模型进行微调(fine-tuning),用了三种方法:监督微调(SFT)、强化学习(RL,比如DPO),以及两者的组合(RPO)。他们还根据训练数据分了三类:普通数字、符号数字和通用数学领域。
结果很有意思。拿Qwen2.5-7B-Instruct为例,用普通数字数据做SFT后,它在数字加法中的正确率飙升到97.17%,可到了符号加法,直接归零。这就像一个学生考前狂背课本,考试时题目一变就傻眼了。RL方法稍微好些,能在符号任务中保留一点能力,但总体正确率不如SFT高。通用领域的微调(比如DS-R1-Distill)则表现更均衡,符号加法正确率达到6.88%,显示出一定的泛化能力。
这告诉我们什么?模型的学习方式就像人类一样,填鸭式教育能应付熟题,但要真正理解规则,还得靠更灵活的训练方式。研究者指出,当前的微调方法还是太偏重模式匹配,要想让模型学会抽象的数学原理,可能需要全新的训练思路。
📊 数据说话:图表中的秘密
让我们来看看研究中的一些关键数据,直观感受LLMs的“真面目”。
表1:数字加法 vs. 符号加法正确率
| 模型 | 数字加法(ZS) | 符号加法(S) | 下降幅度( Δ \Delta Δ) |
|---|---|---|---|
| Claude-3.5-sonnet | 99.81% | 7.51% | -92.30% |
| GPT-4o | 93.39% | 9.59% | -83.80% |
| DeepSeek-V3 | 98.92% | 16.14% | -82.78% |
| Llama3.3-70b-It | 79.75% | 4.30% | -75.45% |
这个表格就像一面镜子,照出了模型的“虚荣心”。在熟悉的数字加法中,它们个个光鲜亮丽,可一换符号,就原形毕露。平均下降81.23%的正确率,简直是数学界的“滑铁卢”。
图2:正确率随位数变化
研究者还画了一张图,展示了正确率如何随数字位数变化。在数字加法中,曲线像过山车,时高时低;而在符号加法中,曲线则是直线下滑。这就像两个跑步选手,一个在平地上蹦蹦跳跳,另一个一上坡就喘不过气。
🤔 从模式到原理:LLMs的数学瓶颈
这些实验拼凑出一幅清晰的画面:LLMs更像“记忆大师”,而非“算法专家”。它们在数字加法中的高分,很大程度上靠的是训练数据中的常见模式。可一旦任务变陌生(符号加法)或规则被明确要求(few-shot),它们就露馅了。研究者总结了四条证据:
- 符号任务崩盘:正确率暴跌81.23%,说明模型依赖数字表征,而非抽象规则。
- 非单调性曲线:正确率随位数忽上忽下,违背算法应有的稳定下降趋势。
- 交换律失灵: A + B ≠ B + A A+B \neq B+A A+B=B+A 的情况多达1700次,暴露了对基本性质的无知。
- 规则冲突:外部规则让表现更糟,显示模型的计算方式和人类思维不兼容。
这就像一个魔术师,台上表演得花团锦簇,可后台一看,全是提前准备好的道具。研究者认为,这反映了当前LLMs架构的根本局限:它们擅长模仿,却不擅抽象。
🚀 未来的路:从模仿到理解
这场研究不仅揭露了LLMs的短板,也为未来指明了方向。传统的基准测试(如GSM8k)就像给学生发奖状,光看分数漂亮,却没检查他们是否真懂。现在,我们需要新的“考试方式”:用符号变换测试抽象能力,用交换律检查基本性质,用位数递增看算法稳定性。只有这样,才能分清谁是真才实学,谁是“蒙题大师”。
更重要的是,这项研究提醒我们,LLMs要想真正“懂”数学,可能需要一次架构上的革命。比如,能不能设计一种模型,既能记住模式,又能像人类一样推导规则?或许未来的AI,会像个真正的数学家,既能算得快,又能想得深。
🌍 现实的影响:信任与责任
这项发现不只是学术圈的谈资,它还敲响了警钟。想象一下,如果一个医疗系统用LLMs计算药物剂量,却因为符号变换出错而下错药方,后果不堪设想。研究者强调,在金融、医疗等关键领域部署AI前,必须清楚它们的局限,避免“看起来很美”的假象酿成大祸。这就像给一辆无人车导航前,得先确认它不会把红灯看成绿灯。
🎉 结语:一场数学的侦探之旅
从两位数加法到符号变换,这场研究就像一场数学侦探剧。LLMs扮演了“嫌疑人”,看似才华横溢,却在关键线索前露出破绽。研究者们用简单的问题,挖出了深藏的秘密:这些模型更像记忆的搬运工,而非规则的创造者。这不仅让我们重新审视AI的能力,也为未来的突破埋下了种子。
下次当你看到一个AI轻松解出复杂方程,别急着鼓掌——也许,它只是背了一本特别厚的答案书罢了。
参考文献
- Yang Yan, Yu Lu, Renjun Xu, Zhenzhong Lan. “Do PhD-level LLMs Truly Grasp Elementary Addition? Probing Rule Learning vs. Memorization in Large Language Models.” arXiv preprint arXiv:2504.05262 (2025).
- Cobbe, K., et al. “Training Verifiers to Solve Math Word Problems.” arXiv preprint arXiv:2110.14168 (2021).
- Hendrycks, D., et al. “Measuring Mathematical Problem Solving With the MATH Dataset.” arXiv preprint arXiv:2103.03874 (2021).
- OpenAI. “GPT-4 Technical Report.” arXiv preprint arXiv:2303.08774 (2024).
- DeepSeek-AI. “DeepSeek-V3: Advancing Mathematical Reasoning in Language Models.” Technical Report (2025).




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











