






1. 文档操作
1.1 索引文档
Es是基于restful风格的服务,所以我们只需要通过向es服务发送相应的restful请求即可使用es为我们提供的相应服务。为了索引一个文档到某个索引中,我们可以向es发送如下的请求:
使用PUT请求方式
PUT foo/_doc/1
{
"name": "andy"
}
其中:
1. foo是一个索引的名字,这个foo索引是不存在的,es会为我们自动创建该索引,也就是说,在索引一个文档的时候,如果命令中指定的索引不存在,es会为我们自动创建该索引。
2. _doc表示“文档”类型,类型这个概念在es7中已经被遗弃(大概是被玩坏了),在es7中,默认就只有_doc和其他几种类型了。
3. 最后的1则是要索引的文档的id
4. 每当我们索引一个文档到一个索引中时,就会为这个文档的每一个字段制作倒排索引
第一次执行以上命令,结果为:
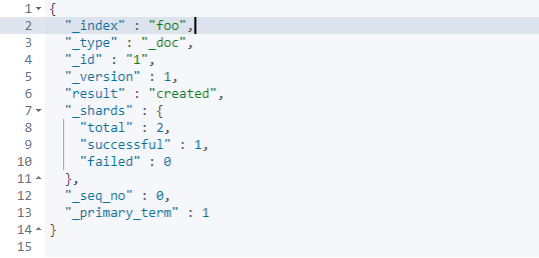
第二次执行以上命令,结果为:
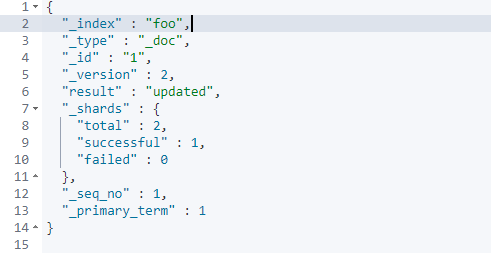
可以看出,PUT请求方式 + “_doc”,既可以用于增加, 也可以用于修改。
另外,为了证明es确实帮我们创建了foo索引,可以通过以下命令获得foo索引的信息
GET foo
顺便地,这是删除索引的命令
DELETE foo
索引文档的所有方法,都在下边了,由老师现场测试:
请求方式 | URL | 说明 |
PUT | foo/_create/1 | 新增,重复执行会报错 |
PUT | foo/_doc/1 | 新增,第一次执行是增加,重复执行就是修改 |
PUT | foo/_create | 报错,PUT不能省略id |
PUT | foo/_doc | 报错,PUT不能省略id |
POST | foo/_create/1 | 新增,重复执行会报错,因为文档id已存在 |
POST | foo/_doc/1 | 新增,重复执行就是修改 |
POST | foo/_create | 报错,该方式不能省略id |
POST | foo/_doc | 新增,自动生成id |
经过测试,不难发现,_create只能用于新增数据,_doc既可以用于新增,也可以用于修改。只有Post + _doc 才能省略id
1.2 查询文档
不同于索引文档那样:既可以使用PUT,又可以使用POST请求方式,查询文档,只能使用GET请求方式:
GET foo/_doc/1
查询结果:
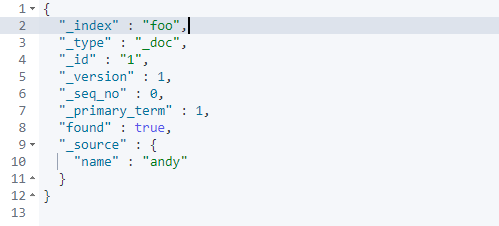
注意:我们看到结果中有“_version”和“_seq_no”这两个字段,“_version”用于记录一个文档被修改的次数。“_seq_no”用于乐观锁,每次对索引中的任何一个文档进行修改,“_seq_no”都会递增!
下面我们测试一下“_seq_no”乐观锁的功能,首先,索引一个文档:
PUT foo/_doc/1
{
"name": "andy"
}
然后,查看该文档的信息:
GET foo/_doc/1
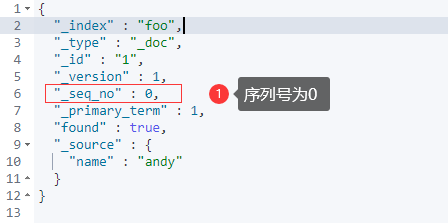
然后,修改文档信息:
PUT foo/_doc/1
{
"name": "andy!!!"
}
然后,再次查看文档的信息:
GET foo/_doc/1
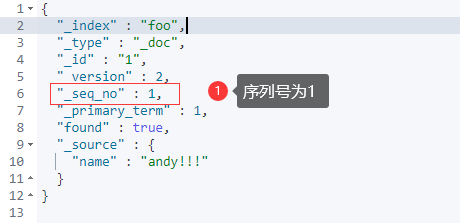
接下来,为了保证并发安全,在修改数据时,先查询出当前的_seq_no,在修改时,需要把查询出来的_seq_no带上:
PUT foo/_doc/1?if_seq_no=1&if_primary_term=1
{
刘德华"
}
只有参数中携带的if_seq_no的值,与索引中的_seq_no的值相同,才会修改成功!如果不相同,则说明有其他客户端已经修改了这个索引,本次修改就会失败!
1.3 更新文档
在前面讲解索引文档的时候,我们已经说过,PUT和POST都可以同时索引文档和更新文档。这里介绍的api,是专门用于修改数据的,这种方式需要在URL中写出“_update”,如下:
先索引一个文档
PUT foo/_doc/1
{
"name": "andy"
}
再更新文档
POST foo/_update/1/
{
"doc": {
刘德华"
}
}
修改时,在URL中写出“_update”与_doc的区别
1. 修改时URL中使用了“_update”,此时必须在请求体中写出“doc”这个属性
2. 修改时URL中使用了“_update”,如果文档没有发生变化,则es不会做出任何操作,也就是version和_seq_no都不会发生变化
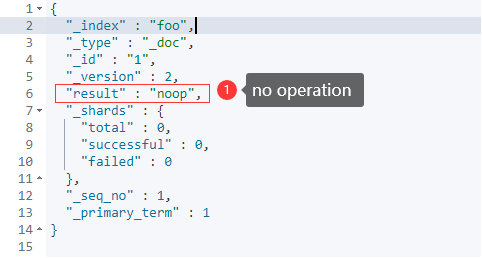
3. 修改时URL中使用了“_update”,文档中某些字段如果在本次修改中没有写出来,则会保持不变,而如果在修改时URL中没有使用“_update”,则这些没有写出来的字段就会被删除掉,测试代码如下:
DELETE foo
PUT foo/_doc/1
{
"name": "andy",
"gender": "male"
}
POST foo/_update/1/
{
"doc": {
刘德华"
}
}
PUT foo/_doc/1
{
刘德华"
}
GET foo/_doc/1
4. _doc可以和PUT和POST搭配使用,既能增加也能修改;_update只能和POST搭配使用。
1.4 删除文档
删除文档,必须发送DELETE请求
DELETE foo/_doc/1
1.5 批量操作
批量操作,必须发送POST请求
简单示例
POST foo/_bulk
{"create": {"_id":"1"}}
{"name": "Andy Lau"}
{"create": {"_id":"2"}}
{"name": "Eason Chen"}
以上,第2行和第3行是一个整体,第4行和第5行是一个整体
复杂示例
POST /foo/_bulk
{"delete":{"_index": "foo", "_id": "1"}}
{"create":{"_index": "foo", "_id": "3"}}
{"name": "G.E.M"}
{"update": {"_index": "foo", "_id": "2"}}
{"doc": {"name": "陈奕迅"}}
以上,第2行这单独的一行就是一个整体,第3行和第4行是一个整体,第5行和第6行是一个整体
“批量操作”会按照先后顺序执行所有action。如果某一个单独的action由于某种原因执行失败了,“批量操作”仍然会继续执行后面的action。
接下来,我们可以访问以下资源,批量导入数据:
https://raw.githubusercontent.com/elastic/elasticsearch/master/docs/src/test/resources/accounts.json
以上网址默认是无法访问的,我们需要先进入以下网站:
https://site.ip138.com/raw.Githubusercontent.com/
查询出raw.githubusercontent.com的ip地址为:
185.199.111.133
然后修改hosts文件,在最末尾添加以下内容
185.199.111.133 raw.githubusercontent.com
再次访问
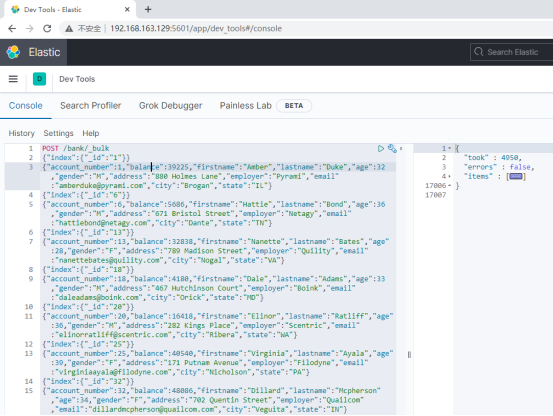
将以上数据,批量导入到es中:
2. 索引操作
之前我们都是通过在索引文档的同时,让es帮我们自动创建索引的。其实我们也可以自己创建索引。
2.1 创建索引
PUT /foo
2.2 删除索引
DELETE /foo
2.3 添加文档,顺便创建索引
PUT /foo/_create/1
{
"name": "andy",
"age": 22
}
以上"{ }"中的内容,就是http请求中的请求体。
2.4 创建索引,同时指定类型
PUT /foo
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"birthday": {
"type": "date"
}
}
}
}
注意:
1. 若我们在创建一个索引的同时,指定了类型,则后续在向该索引中添加文档数据时,文档数据就必须符合这些类型
2. 若我们在创建一个索引的同时,直接创建文档,而没有手动指定类型,则es会自动生成默认的类型
2.5 查看索引信息
GET foo
2.6 通过Kibana查看数据
在Kibana首页,点击manage,然后点击Index Patterns,就会看到以下界面
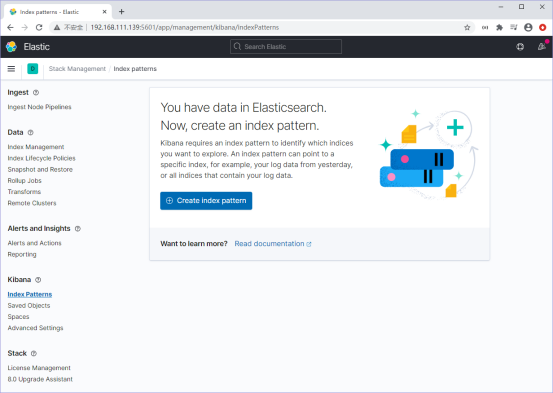
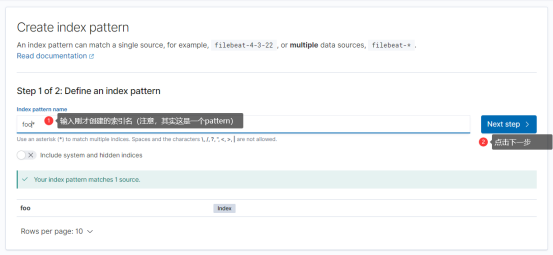
点击“Create index pattern”,看到下图所示的界面
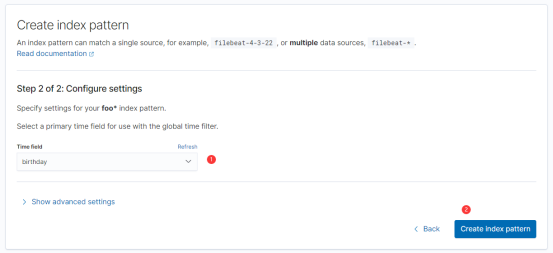
能看到以下界面,说明foo索引的index pattern已经创建好了,
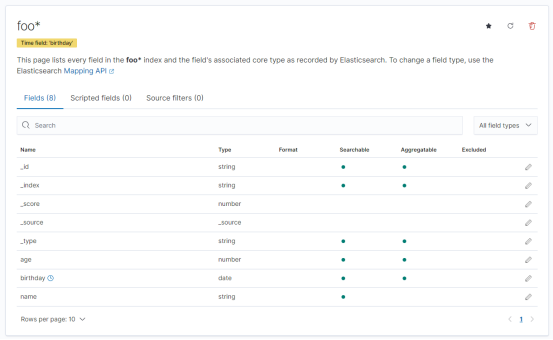
搜索“Discover”
注意,在查看数据时,记得把时间条件调整正确,否则无法看到数据
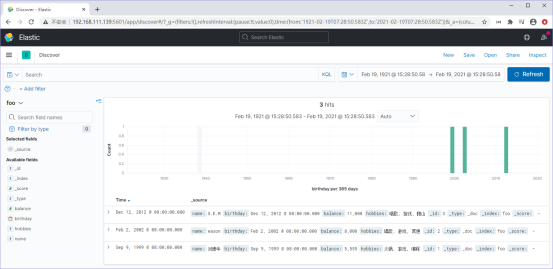
2.7 ElasticSearch倒排索引数据结构
在第一章简单地提及了倒排索引的结构,这里将详细讲解在es中倒排索引的结构。那么在es中,倒排索引是个什么样子呢?

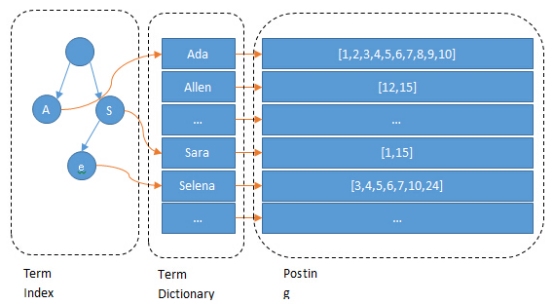
es倒排索引中的概念:
Term:一段文本经过分词器处理后会得到若干个单词,这一个一个的单词就叫做Term
Term Dictionary:单词字典,其中存放的是Term,是Term的集合(消重)
Term Index:单词索引,为了更快地找到某个单词,所建立的索引(正向索引)
Posting List:倒排列表,倒排列表记录了包含了某个Term的所有文档的id列表
为了搞清楚这些概念,让我们来举个例子:假设有个user索引库,它存储的文档有五个字段,分别是id、name、gender、age、address:
id | name | gender | age | address |
1 | 刘德华 | 男 | 59 | 西安市北大街 |
2 | 孙燕姿 | 女 | 35 | 西安市南大街 |
3 | 邓紫棋 | 女 | 28 | 北京市东大街 |
我们知道,每个文档都有一个ID,如果插入的时候没有指定的话,es会自动生成一个(POST + _doc),因此ID字段就不多说了。es会为文档的每个字段各建立一个索引,建立的索引如下:
name字段:
Term | Posting List |
刘德华 | 1 |
孙燕姿 | 2 |
邓紫棋 | 3 |
age字段:
Term | Posting List |
28 | 3 |
35 | 2 |
59 | 1 |
gender字段:
Term | Posting List |
男 | 1 |
女 | 2,3 |
address字段:
Term | Posting List |
西安 | 1,2 |
西安市 | 1,2 |
大街 | 1,2,3 |
北京 | 3 |
北京市 | 3 |
北大街 | 1 |
南大街 | 2 |
东大街 | 3 |
以上的4个表中的Term列,就是Term Dictionary。
当用户输入关键字进行搜索时,es会先对搜索词进行分词,然后拿着这些分词,与索引中的分词进行比较,进而去查找相关的文档。问题是,当某个字段中的Term特别多的时候,搜索Term的速度就会变慢。那么如何才能提高搜索Term的速度呢?当然是为这些Term再单独创建索引了,这样的索引就是Term Index。Term Index就是一个B-Tree,采用二分法查找。也就是说,每个Term Dictionary是排好序的,这样才能使用二分法查找!
2.8 Keyword
Keyword类型的倒排索引,是在不对字段进行分词的前提下建立的,看起是这个样子:
address.keyword索引
Term | Posting List |
西安市北大街 | 1 |
西安市南大街 | 2 |
北京市东大街 | 3 |
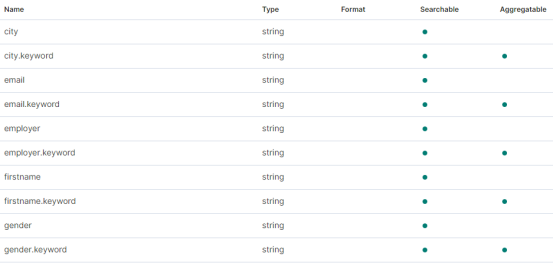
我们可以查看bank的Index Pattern,会发现每一个string类型的字段,都有两个索引,一个是分词后建立的索引,另一个是不分词就建立的索引
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









