








线性表(Linear List)。顾名思义,线性表就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向。其实除了数组,链表、队列、栈等也是线性表结构。

非线性表,比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。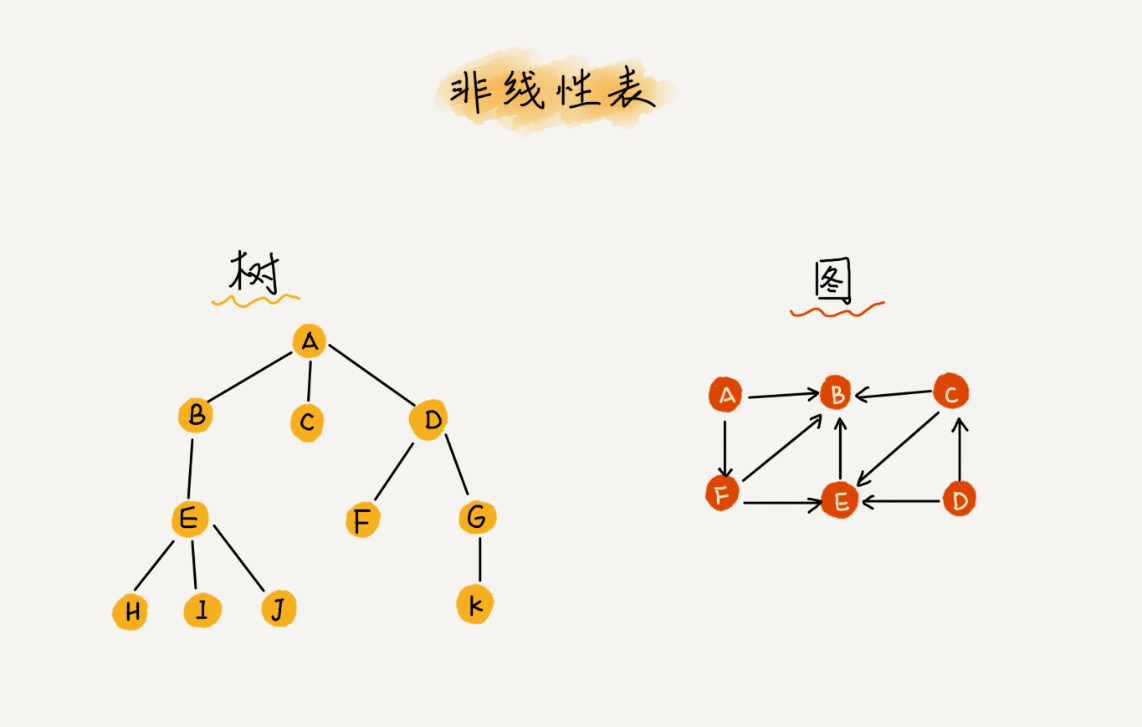
为什么大多数编程语言中,数组要从 0 开始编号,而不是从 1 开始呢?从数组存储的内存模型上来看,“下标”最确切的定义应该是“偏移(offset)”。前面也讲到,如果用 a 来表示数组的首地址,a[0]就是偏移为 0 的位置,也就是首地址,a[k]就表示偏移 k 个 type_size 的位置,所以计算 a[k]的内存地址只需要用这个公式:a[k]_address = base_address + k * type_size但是,如果数组从 1 开始计数,那我们计算数组元素 a[k]的内存地址就会变为:a[k]_address = base_address + (k-1)*type_size对比两个公式,我们不难发现,从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对于 CPU 来说,就是多了一次减法指令。数组作为非常基础的数据结构,通过下标随机访问数组元素又是其非常基础的编程操作,效率的优化就要尽可能做到极致。所以为了减少一次减法操作,数组选择了从 0 开始编号,而不是从 1 开始。
花时间研究了一下多维数组的寻址公式,写完感觉豁然开朗:
虽然我们可以把二维数组中成员看作行和列两个方向构成的格子中的数据,三维数组成员看作长宽高构成的立体格子中的数据,但这只是有助于理解的形象表示,实质上数组在内存中是连续线性的。
那么对于二维数组 x[][](长度为a1*a2)来说,求x[i][j]的时候(不会考虑i j越界的情况),要到i的时候,一定走完了i*a2的长度,在x[i][0]往后找j个长度就是x[i][j],所以会从初始地址增加 (i*a2+j)个单位长度。
对于三维数组, x[][][](长度为a1*a2*a3)来说,求x[i][j][k]的时候,要到i的时候,一定走完了i*a2*a3的长度,在x[i][0][0]往后找j*a3个长度就是x[i][j][0],再往后找k个长度就是x[i][j][k],所以会从初始地址增加 (i*a2*a3+j*a3+k)个单位长度。以此类推如下:
数组 为x ,an为某一维度长度
一维数组:(a1)x[i]_address = base_address + i * type_size
二维数组:(a1*a2)x[i][j]_address = base_address + ( i * a2 + j ) * type_size
三位数组:(a1*a2*a3)x[i][j][k]_address = base_address + ( i * a2*a3 + j * a3 + k ) * type_size
四位数组:(a1*a2*a3*a4)x[i][j][k][l]_address = base_address + ( i * a2*a3*a4 + j *a3*a4 + k *a4 + l ) * type_size
。。。。。。
n维数组:(a1*a2*a3*...an)x[i1][i2][i3]...[in] = base_address + ( i1 * a2*a3*...*an + i2 * a3*a4*...*an + i3 * a4*a5*...*an +......i(n-1) * an + in) * type_size
JVM标记清除算法:
大多数主流虚拟机采用可达性分析算法来判断对象是否存活,在标记阶段,会遍历所有 GC ROOTS,将所有 GC ROOTS 可达的对象标记为存活。只有当标记工作完成后,清理工作才会开始。
不足:1.效率问题。标记和清理效率都不高,但是当知道只有少量垃圾产生时会很高效。2.空间问题。会产生不连续的内存空间碎片。
链表底层的存储结构
从图中我们看到,数组需要一块连续的内存空间来存储,对内存的要求比较高。如果我们申请一个 100MB 大小的数组,当内存中没有连续的、足够大的存储空间时,即便内存的剩余总可用空间大于 100MB,仍然会申请失败。而链表恰恰相反,它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用,所以如果我们申请的是 100MB 大小的链表,根本不会有问题。链表结构五花八门,今天我重点给你介绍三种最常见的链表结构,它们分别是:单链表、双向链表和循环链表。我们首先来看最简单、最常用的单链表。

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











