






SPDK基于NVMe over Fabrics协议[1],实现了NVMe协议在TCP、RDMA等传输通道上的拓展,使得块设备可以通过TCP或RDMA暴露出来。基于TCP的NVMe over TCP的数据传输框架如图1所示:
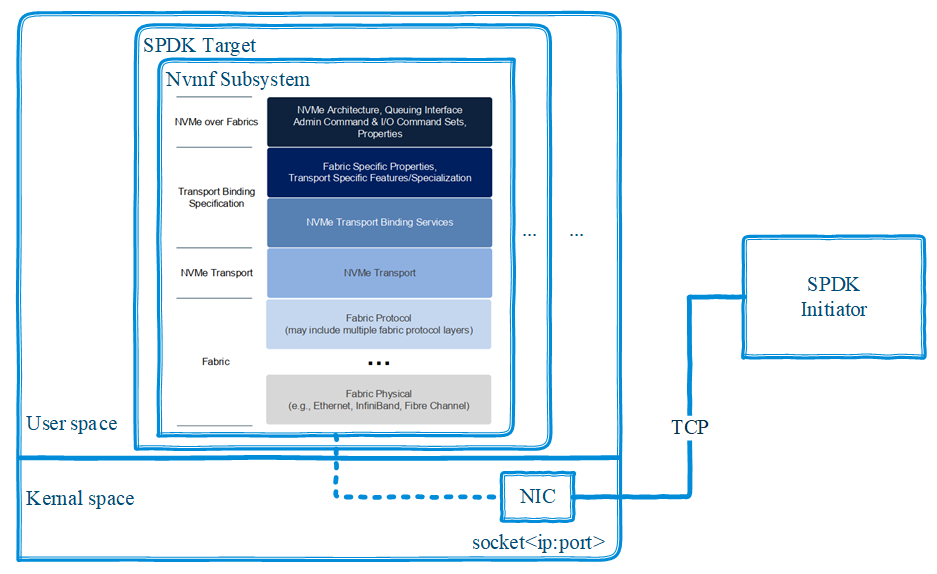
图1. Nvme over TCP数据传输框架
1. NVMe over TCP数据传输原理和机制
我们以NVMe over TCP读取数据为例进行数据传输机制的分析。与一般的服务器处理流程类似,我们分为Initiator端(也称HOST端)和Target端(也称Controller端),如图2,当Initiator和Target端建立好连接后,Target和Initiator传输数据的流程是这样的:
Initiator发送一个CapsuleCmd PDU到Target(in_capsule_data_size决定是否含有数据),CapsuleCmd PDU中含有SQE(Submission Queue Entry)。
Target收到Initiator的请求后对其进行解析,将需要的数据以C2HData PDU的形式进行传输。
传输完成后Target端发送CapsuleResp PDU到Initiator,PDU包中含有CQE(Completion Queue Entry)。
PDU包的详细处理流程在函数nvmf_tcp_sock_process和函数nvmf_tcp_req_process中[2],两个函数中分别有一个状态机[3],前一个状态机是对与PDU包的处理流程,后一个状态机是对具体的TCP Request的处理流程。图3给出了C2H的传输流程。
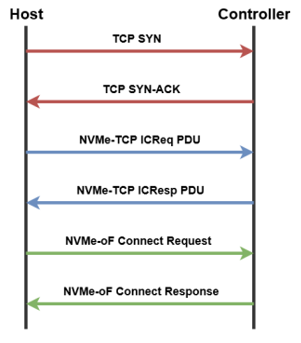
图2. NVMe over TCP建立连接
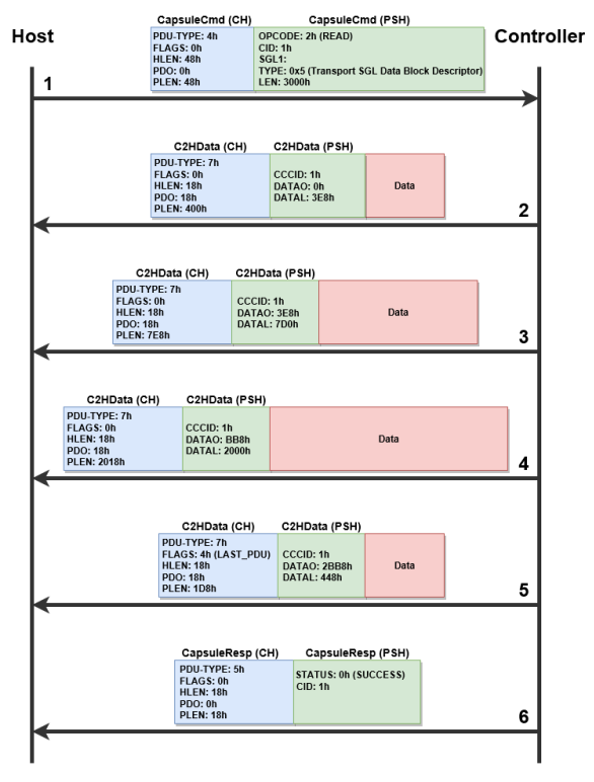
图3. Controller向Host传输数据
简单来说,HOST将数据按照pdu包的形式发送给Controller端,Controller端进行数据的解析,包括包头和包体的解析,详细过程可以参考状态机,将PDU中携带的数据保存到buffer中,然后将解析后得到的命令发送到Qpair。
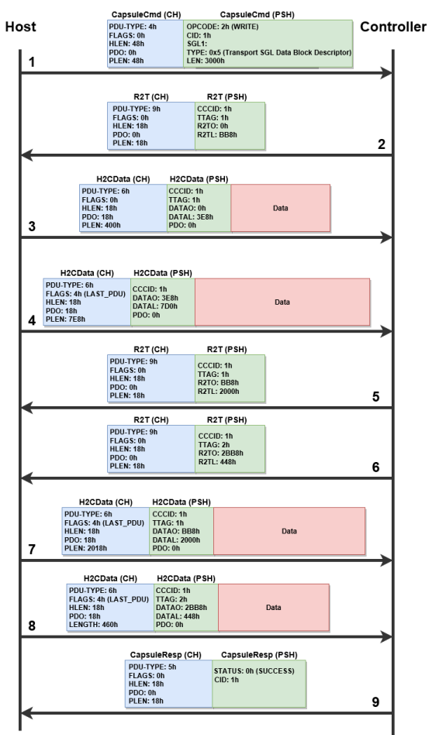
图4. HOST向Controller传输数据
如图4,数据从HOST向Controller传输时,Controller通过Ready to Transfer(R2T) PDUs控制PDU包的传输速度,只有Controller发送了R2T PDU,HOST才能向Controller发送数据。Controller也可以在HOST尚未发送完上一个R2T PDU要求的数据时发送下一个R2T PDU。
HOST TO Controller数据发送流程:
HOST 发送Command Capsule PDU(CapsuleCmd) 到controller,CapsuleCmd中含有SQE,并且包含了请求的数据大小(可以选择是否启用in_causple_data,启用之后数据会包含在CapsuleCmd中)。
当HOST收到R2T PDU, HOST就向Controller发送H2CData PDU,可以分为多次发送,直到将数据发送完。在此过程中,Controller可以继续向HOST发送R2T PDU。
所有的数据发送完成后, Controller向HOST发送Response Capsule PDU(CapsuleResp),其中包含了CQE。
2.测试和调优
本文选取了几个基于Transport对NVMe over TCP性能影响性相对较大的参数进行了测试,希望有助于大家进行调试和性能优化,当然,不同的测试环境情况可能会有所不同,更重要的是掌握Transport的参数对性能的影响以及调试的方法。
2.1 测试和调优工具
目前来说,SPDK社区有几种常用的测试工具,包括fio,perf和bdevperf等。注意SPDK的perf与通常Linux系统中的perf工具有所不同,SPDK中的perf可以直接配置core mask来指定进行I/O操作的CPU核,主要是用于对设备做压力测试以评估性能。
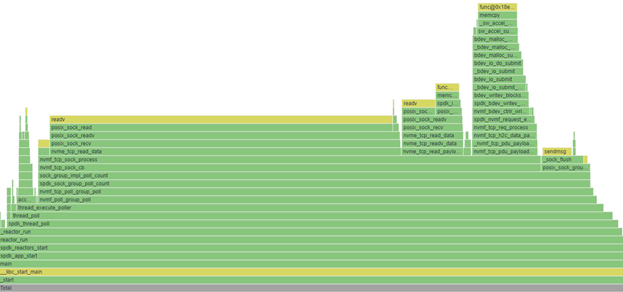
图5. VTune Flame Graph
还有一个强大的性能分析工具VTune,Intel® VTune™ Profiler 是一种用于串行和多线程应用程序的性能分析工具,可以优化 HPC、云、物联网、媒体、存储等的应用程序性能、系统性能和系统配置。VTune支持分析本地或远程的Windows,Linux及Android应用,这些应用可以部署在CPU,GPU,FPGA等硬件平台上。支持C,C++,PYTHON等多种语言软件的性能分析。我们可以方便地利用Vtune对SPDK进行性能分析。图5是Vtune中SPDK选择hotspots作为性能分析方法所得到的函数占用CPU时间的分布图和函数调用栈[4]。
2.1 测试和调优说明
首先说明一下我的测试环境,如图6,在一个四节点集群环境内选取Master节点和Node1节点作为NVMf Target和NVMf Initiator,集群内的节点通过Master节点上网。
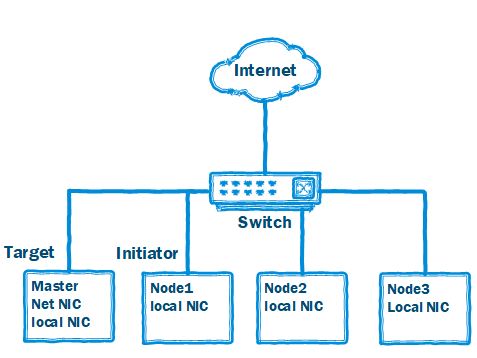
图6. 测试环境
Target:
scripts/rpc.py bdev_null_create null0 2048 512
//创建null bdev
scripts/rpc.py nvmf_create_subsystem nqn.2016-06.io.spdk:cnode1 -a
//创建nvmf subsystem
scripts/rpc.py nvmf_subsystem_add_ns nqn.2016-06.io.spdk:cnode1 null0
//将namespace添加到subsystem中
scripts/rpc.py nvmf_create_transport -t tcp --in-capsule-data-size 0
//根据参数初始化一个transport,常见参数在此添加
scripts/rpc.py nvmf_subsystem_add_listener nqn.2016-06.io.spdk:cnode1 -t tcp -a 192.168.11.1 -s 4420
//对指定的ip和端口进行监听
HOST:
./build/examples/perf -q 32 -s 1024 -w randwrite -t 40 -o 4096 -r 'trtype:TCP adrfam:IPv4 traddr:192.168.11.1 trsvcid:4420'
perf中常用的参数:
[-q, --io-depthio depth]
[-o, --io-sizeio size in bytes]
[-O, --io-unit-size io unit size in bytes (4-byte aligned) for SPDK driver. default: same as io size]
[-w, --io-patternio pattern type, must be one of
(read, write, randread, randwrite, rw, randrw)]
[-M, --rwmixread <0-100> rwmixread (100 for reads, 0 for writes)]
[-t, --timetime in seconds]
[-c, --core-maskcore mask for I/O submission/completion.]
(default: 1)
[-r, --transportTransport ID for local PCIe NVMe or NVMeoF]
Format: 'key:value [key:value] ...'
Keys:
trtype Transport type (e.g. PCIe, RDMA)
adrfam Address family (e.g. IPv4, IPv6)
traddr Transport address (e.g. 0000:04:00.0 for PCIe or 192.168.100.8 for RDMA)
trsvcid Transport service identifier (e.g. 4420)
subnqn Subsystem NQN (default: nqn.2014-08.org.nvmexpress.discovery)
ns NVMe namespace ID (all active namespaces are used by default)
hostnqn Host NQN
Example: -r 'trtype:PCIe traddr:0000:04:00.0' for PCIe or
-r 'trtype:RDMA adrfam:IPv4 traddr:192.168.100.8 trsvcid:4420' for NVMeoF
Note: can be specified multiple times to test multiple disks/targets.
[-z, --disable-zcopydisable zero copy send for the given sock implementation. Default for posix impl]
[-Z, --enable-zcopyenable zero copy send for the given sock implementation]
[注:这部分函数较多,建议横屏或网页端阅读]
3.性能分析和优化
scripts/rpc.py nvmf_create_transport --help会展示很多的参数,仅展示部分tcp相关参数:
-h, --help show this help message and exit
-t TRTYPE, --trtype TRTYPE
Transport type (ex. RDMA)
-g TGT_NAME, --tgt-name TGT_NAME
The name of the parent NVMe-oF target (optional)
-q MAX_QUEUE_DEPTH, --max-queue-depth MAX_QUEUE_DEPTH
Max number of outstanding I/O per queue
-m MAX_IO_QPAIRS_PER_CTRLR, --max-io-qpairs-per-ctrlr MAX_IO_QPAIRS_PER_CTRLR
Max number of IO qpairs per controller
-c IN_CAPSULE_DATA_SIZE, --in-capsule-data-size IN_CAPSULE_DATA_SIZE
Max number of in-capsule data size
-i MAX_IO_SIZE, --max-io-size MAX_IO_SIZE
Max I/O size (bytes)
-u IO_UNIT_SIZE, --io-unit-size IO_UNIT_SIZE
I/O unit size (bytes)
-n NUM_SHARED_BUFFERS, --num-shared-buffers NUM_SHARED_BUFFERS
The number of pooled data buffers available to the
Transport(io)
-b BUF_CACHE_SIZE, --buf-cache-size BUF_CACHE_SIZE
The number of shared buffers to reserve for each poll
Group
-z, --zcopy Use zero-copy operations if the underlying bdev
supports them(only malloc bdev can be used,and in_cap_sz must be 0)
-o, --c2h-success Disable C2H success optimization. Relevant only for
TCP transport
-e CONTROL_MSG_NUM, --control-msg-num CONTROL_MSG_NUM
The number of control messages per poll group.
Relevant only for TCP transport
默认参数配置:

-q MAX_QUEUE_DEPTH, --max-queue-depth MAX_QUEUE_DEPTH
QD影响的是队列深度,决定了Target端接受请求的数量,无论是单核还是多核情况下,Initiator端的QD和Target端的QD相近时获得较好的性能。此时即使再增加Target端的QD也不会获得较大的性能提升。在单核情况下,Target端的QD默认是128,逐步增加Initiator端的QD传输速率和IOPS均有所提升,当QD的数量超过Target端的QD一定程度时,传输速率和IOPS的增加减缓并趋于停滞,我们通过spdk_top查看core status可以发现,这时候单core性能已经达到了极限,因此增加Target端的QD也并不会再对性能有所提升,在SPDK中,所支持的max_queue_depth的值为65536。
-c IN_CAPSULE_DATA_SIZE, --in-capsule-data-size IN_CAPSULE_DATA_SIZE
In_capsule_data不支持Response capsules, 因为最大只有16 bytes,而在Fabrics and Admin Commands中,in_capsule data最大可以支持8192bytes, I/O Queue Command的In_Capsule Data可以支持64 bytes (IOCCSZ × 16) bytes。
从数据传输机制中我们可以看出,连接建立完成后首先传输的是CapsuleCmd,in_capsule_data_size代表CapsuleCmd中所能携带的数据大小,默认为4K,这意味着我们进行数据传输时减少了数据传输次数,节省了很多PDU头部开销,可以明显感觉到IOPS和传输速率的增加。以Initiator向Target传输数据为例,Initiator向Target传输数据时,直接将数据附到CapsuleCmd中。对于in_capsule_data_size参数来说,write的性能提升相对较为明显,这很好理解,当Initiator向Target写数据时,数据就被携带在CapsuleCmd中,而对于read命令来说,read是不需要携带大量数据的,而response capsules并不支持in_capsule_data。
In_capsule_data_size设定在接近io_size时获得较好的性能。举个例子,对于Initiator端发送2k,4k,8k的IO时,Target端默认的in_capsule_data_size为4k,此时,Initiator发送的数据IO在和in_capsule_data_size相近时会获得相对较优的IOPS和传输速率,相对提升较大。
注意:in_capsule_data_size须小于max_io_size,否则,会将in_capsule_data_size重置为max_io_size。
-i MAX_IO_SIZE, --max-io-size MAX_IO_SIZE
max_io_size必须大于等于8KB,且必须是2的倍数,默认为128k,max_io_size指对于传输的IO大小而言,传输的IO大小不能大于max_io_size,in_capsule_data_size和io_unit_size的值均不能大于max_io_size。在建立连接时,ic_resp->maxh2cdata也被设定为max_io_size以协商PDU包中data的大小。
一般情况下,当发送的IO大小较小时,可以获得较大的IOPS,此时IO的传输速率较小,延时也较小,而当发送的IO较大时,相对地,IOPS减小,传输速率增大,延时也增加了。
-n NUM_SHARED_BUFFERS, --num-shared-buffers
默认511
-b BUF_CACHE_SIZE, --buf-cache-size BUF_CACHE_SIZE
这两个参数都和内存池有关系。在transport创建时会创建一个内存池,内存池含有NUM_SHARED_BUFFERS个IO_UNIT_SIZE+ NVMF_DATA_BUFFER_ALIGNMENT数量的元素,transport的poll group中也会从内存池中获取buffer_cache_size个内存。
注意,poll group请求的内存不能超过内存池的大小,也就是说将内存池的内存分配给每个core上的poll group时,如果poll group的数量乘以buffer_cache_size的大小的内存超过了内存池的大小,这是不合理的。举个例子,当启动16个core时,默认num_shared_buffers是511,buffer_cache_size默认32,16*32=512,超过了内存池大小。
当数据需要buffer接收时,会优先从poll group的cache中获取,当poll group的cache用光后再从transport的内存池中获取buffer。
num_shared_buffers的增加会提升数据传输和处理的性能,当然此时会占用大量内存,所以也需要考虑和内存之间的平衡。buffer_cache_size参数需要在多核并且下发大量IO时对IOPS和传输速率的提升相对比较明显。
-z, --zcopy Use zero-copy operations if the underlying bdev supports them
零拷贝的操作需要底层bdev的支持,并且只有当in_capsule_data不使用的时候才起作用,换句话说,我们需要将in_capsule_data_size设置为0,并且只有在write命令时比较明显。以malloc bdev为例,当启用了--zcopy,将会直接将socket的buffer直接和bdev进行数据的传输,越过了transport层,此参数在Initiator端多核下发大量IO情况下提升较为明显。
-u IO_UNIT_SIZE, --io-unit-size IO_UNIT_SIZE
io_unit_size不能为0且必须是4字节对齐的,如果io_unit_size大于max_io_size的话会将max_io_size赋值给io_unit_size。max_io_size / io_unit_size的值不能大于16。
io_unit_size和NVMF_DATA_BUFFER_ALIGNMENT(4k)共同决定了内存池中的内存大小。而io_unit_size和num_shared_buffer共同决定了内存池的大小,对于同样大小的内存池来说,io_unit_size越大,那么num_shared_buffer就会越小,反之亦然, QD决定了Tareget端对于请求的接收数量,或者说可以接受的PDU的数量,这个值是固定的,当设定了io_unit_size,对于Initiator端发送的IO来说,
若io_size较小,那么IOPS固然相对会比较高,但是传输速率并不太好,因为对于每一个IO来说,都需要取用内存池中的buffer,buffer的大小和数量是固定的,小IO也分配一个buffer,并不能充分利用buffer的空间,这就造成了资源上的浪费。
而若io_size较大,那么大的IO就不得不被拆分,对于buffer来说,得到了充分的利用,但是会降低IOPS。
所以,对于io_unit_size的设定需要和Initiator端发送的IO大小相近时获得相对较好的性能,当然设定较小的io_unit_size总是可行的,当buffer空间小于IO大小时,可以使用多个buffer以满足IO的大小。
注意:无论哪一种参数在进行单核测试时都要避免使用0核,因为有较多的进程会默认在0核上运行,导致SPDK性能测试受到影响。
经过以上对于参数的分析,我们可以得到一些具体场景下的性能优化方向。
在读多写少的情况下,可以考虑将io_unit_size设置为与IO大小相近的值,并注意num_shared_buffer的调节。
在写多读少的情况下,可以考虑将in_capsule_data_size设置一个合适的值,最好与IO大小相近,若底层bdev支持zcopy,也可以启--zcopy,注意zcopy只有在in_capsule_data不启用的情况下才有用。
如果网络延时比较大,可以考虑增加QD,num_shared_buffer。
一般来说,in_capsule_data对于性能的优化是明显可见的,所以建议启用in_capsule_data。
当然,以上只是一些性能优化的建议,实际的调优还要和具体的系统环境和场景相结合,具体问题具体分析。
NVMe over TCP使用TCP/IP协议栈,相较于RDMA或者本地NVMe的方式来说,增加了TCP/IP协议栈的开销以及用户态和内核态之间切换的开销,这主要是由于NVMe over TCP的数据传输经过网卡,直接经过内核的协议栈[5]。社区也在不断地对NVMe over TCP的性能进行优化。
社区目前正在针对NVMe over TCP性能进行的一些优化:
使用DSA等一些硬件加速平台进行数据拷贝和计算的卸载,比如通过DSA offload nvme over tcp中crc32的计算(https://review.spdk.io/gerrit/c/spdk/spdk/+/11708)
通过uring支持对于网络IO的异步处理,若要想使用io_uring,需要在编译时加入./configure --with-uring,编译出的可执行文件会优先使用SPDK 实现的uring socket,而不是posix的socket实现。Uring的相关代码位于/spdk/module/uring[6]。
Nvme over TCP性能优化方向:
通过硬件加速平台对NVMe over TCP继续进行加速,前面也提到过,对于硬件加速平台进行软件计算和数据传输的卸载,并且效果比较明显。
减少NVMe over TCP传输路径上的数据拷贝,这实质上是针对NVMf Target端进行网络IO时的数据复制。
总结与展望
本文基于NVMe over TCP,对transport对数据传输性能影响较大的参数进行了分析,简述了SPDK的perf和Intel的VTune等工具在性能测试和调优过程中的具体用法,叙述了目前社区正在进行的NVMe over TCP方面的性能优化方案以及将来有可能进行优化的几个方向,希望能对大家进行NVMe over TCP的性能优化起到帮助。
References
[1].https://nvmexpress.org/developers/nvme-transport-specifications/
[2]. 搭建远端存储,深度解读SPDK NVMe-oF target
[3]. 深入理解 SPDK NVMe/TCP transport的设计
[4].https://www.intel.com/content/www/us/en/develop/documentation/vtune-help/top/introduction.html
[5]. SPDK NVMe-oF TCP transport 目前优化的一些工作和方向
[6]. 网络编程的未来,io_uring?

转载须知
推荐阅读
2022 SPDK美国线上论坛(一)| TCP Networking
在SPDK中体验一下E810网卡ADQ直通车


点点“赞”和“在看”,给我充点儿电吧~

















 1683
1683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









