







 本文介绍了一种通过上传Excel表格数据,并将其按每500条数据一组进行分组导出的方法。该方法适用于特定的数据处理场景,通过随机插入分隔符实现数据的均匀分布。
本文介绍了一种通过上传Excel表格数据,并将其按每500条数据一组进行分组导出的方法。该方法适用于特定的数据处理场景,通过随机插入分隔符实现数据的均匀分布。
废话不多说,直接开讲!
昨天接到任务:通过上传excel表格数据,对数据进行500一组分组分割到excel表格进行导出!说实在的,这个问题并不常见!但是感觉可以实现,于是乎今天写博客记录下!
好了,废话不多说,直接看完整代码!
2021-03-06重新更新代码
# coding=utf-8
import math
import random
import time
from tkinter import filedialog, messagebox, ttk
import tkinter.messagebox
import requests
import xlrd
from tkinter.ttk import Label
from tkinter import *
import urllib3
import xlwt
from xlwt import Workbook
import threading
import tkinter as tk
urllib3.disable_warnings()
def main():
def selectExcelfile():
sfname = filedialog.askopenfilename(title='选择Excel文件', filetypes=[('Excel', '*.xlsx'), ('All Files', '*')])
# print(sfname)
# 传递参数,目前参数固定值,可以设置以下动态参数
sku = e_1.get()
num = e_2.get()
iscode = comboxlist.get()
# print(sku,num,iscode)
doProcess(sfname)
text1.insert(INSERT, sfname)
def shop_goodid(id):
url = 'https://item.jd.com/{}.html'.format(id)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
ss = requests.get(url, headers=headers).text
skuid = re.findall('colorSize:(.*?],)', ss)[0]
start = time.time()
#
time.sleep(0.1)
# 考虑性能放弃下面循环
dd = re.findall('"skuId":(\d+),', skuid)
num = 0
for ids in dd:
num+=1
file = Workbook(encoding='utf-8')
# 指定file以utf-8的格式打开
table = file.add_sheet('data')
# 指定打开的文件名
# 字典数据
datatime = time.strftime("%Y-%m-%d%H-%M-%S", time.localtime())
table.write(0, 0, 'sku数据')
table.write(0, 1, 'spu数据')
table.write(num, 0, ids)
table.write(num, 1, id)
print(ids,id)
# file.save('sku数据' + datatime + '.xlsx')
end = time.time() - start
# print(end)
def good_id(goodid):
try:
url = 'https://club.jd.com/comment/productCommentSummaries.action?referenceIds={}&callback=jQuery1982868&_=1592352931024'.format(
goodid)
headers = {
'Host': 'club.jd.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.12 Safari/537.36',
# 'cookie': 'shshshfpa=d1cf61f9-0c3c-a4e9-7480-e08635b84d37-1607913649; shshshfpb=yYxp3xqZQQ%20AKGOa2zG66jQ%3D%3D; unpl=V2_ZzNtbUNeFxx3DUIHcx0IUWIDEQ4SU0ccJgxAAH1LWgZmURtZclRCFnUUR1RnGV4UZwIZXEJcRxRFCEdkexhdBGYAE1pKVXMlRQtGZHopXAJmCxdVQlZFE3wMTlR8G1gFZAsUW3JnRBV8OHZUeRtUDW4HGltBVS1URQ1HUX4cXwNkBiJccldKHHYKTlVzH1s1LG0TEEJQQh1wAEZVfR9VAW8DFV9GV0Adcw52VUsa; __jdv=76161171|ajdo.ubfgho.com|t_1000020693_|tuiguang|08e8345b95ee412ba558b57e7c720c85|1610503315749; shshshfp=d2b0cf0825e71c58c4ea5772d72a8e0e; areaId=12; user-key=0ecd7836-6752-4f2a-b407-21aa747837b7; ipLoc-djd=12-978-2927-51582.3076064641; ipLocation=%u6c5f%u82cf; cn=0; logintype=wx; npin=jd_4af2b33dd6a59; TrackID=1ZdTkJ7YGTF7AvxQ8lOf9vPzhGHiFpiMxv3f4yCkxsEP3_2p1Q_g3ZVuQqsyfcYz_eDTnyQnYurQ7t9C-j-_F7iuKLcmwasMN-h3jkNA5YYI; pinId=LxgJESmodokf_AhbrnKClw; pin=jinshiyuan1123; unick=jinshiyuan1123; _tp=qTmSS0pjZ%2BpSltacjzri4w%3D%3D; _pst=jinshiyuan1123; 3AB9D23F7A4B3C9B=77ANC4CUAEAS5WLYFJ3LFTSZSIPEYNE4Y3ZS62WMGYYW42YQ7BLCPOH5UY2SNI2H4H5D7UTCIRHWPYPEBZIQGHO2KM; __jda=122270672.16110518206731258489497.1611051821.1611285111.1611305375.6; jwotest_product=99; __jdu=1608511737771113412215'
}
con = requests.get(url, headers=headers, verify=False)
# texts = re.findall('"CommentsCount":\[.*?]}',ss.text)
# print(ss.text)
CommentCount = re.findall('"CommentCount":\d+', con.text)
# time.sleep(0.1)
json = CommentCount[0].split(':')[1]
return json
except Exception:
return '暂无'
pass
def write_excel(res,s_r,sh):
update_time = time.strftime('%Y%m%d', time.localtime(time.time()))
book = xlwt.Workbook() # 创建一个excel
sheet = book.add_sheet("采购入库单商品导入模板")
title = ['CLPS事业部商品编码', '外部店铺商品编码','商品数量(个)','代贴条码(是/否)','单价(全球购采购单必填)','质检比例(大件且开通质检服务)0-100','是否序列号入库(是/否)','商家包装规格编码','包装单位']
i = 0
for header in title:
sheet.write(0, i, header)
i += 1
# 写入数据
num = 0
# rows = int(sh.row_values(row)[0])
# print(res,rows)
for row in res:
num+=1
sheet.write(num, 1, str(int(sh.row_values(row)[0]))+str('\t'))
sheet.write(num, 2, 6)
sheet.write(num, 3, '否')
# row+=1
# print(row)
book.save('采购入库单商品导入模板{}{}.xlsx'.format(update_time,s_r))
# print("导出成功!")
def write_excel_two(res,s_r,sh):
update_time = time.strftime('%Y%m%d', time.localtime(time.time()))
book = xlwt.Workbook() # 创建一个excel
sheet = book.add_sheet("POP店铺商品编号")
title = ['POP店铺商品编号(SKU编码)', '商家商品标识','商品条码']
i = 0
for header in title:
sheet.write(0, i, header)
i += 1
# 写入数据
num = 0
for row in res:
num+=1
sheet.write(num, 0,str(int(sh.row_values(row)[0]))+'\t')
sheet.write(num, 1, str(int(sh.row_values(row)[0]))+'\t')
sheet.write(num, 2,str(int(sh.row_values(row)[0]))+'\t')
# row+=1
# print(row)
book.save('POP店铺商品编号{}{}.xlsx'.format(update_time,s_r))
print("导出成功!")
def write_excel_three(res,s_r,sh):
update_time = time.strftime('%Y%m%d', time.localtime(time.time()))
book = xlwt.Workbook() # 创建一个excel
sheet = book.add_sheet("事业部商品编码")
title = ['事业部商品编码(若此列不为空,以此编码获取的商品为准)', '事业部编码(事业部商品编码为空时必填)','商家商品编号(事业部商品编码为空时必填)','长(mm)(必填,大于0)','宽(mm)(必填,大于0)','高(mm)(必填,大于0)','净重(kg)','毛重(kg)(必填,大于0)']
i = 0
for header in title:
sheet.write(0, i, header)
i += 1
# 写入数据
num = 0
for row in res:
num+=1
sheet.write(num, 2, str(int(sh.row_values(row)[0]))+'\t')
sheet.write(num, 3, 10)
sheet.write(num, 4, 10)
sheet.write(num, 5, 10)
sheet.write(num, 7, 0.01)
# row+=1
# print(row)
book.save('事业部商品编码{}{}.xlsx'.format(update_time,s_r))
print("导出成功!")
'''
统计总数据
'''
def group(totals=None):
print(totals)
# totals = 1601
s_r = math.ceil(totals / 500)-1
print(s_r)
arr_n = []
nums = 0
for n in range(1, s_r):
nums += 1
t_da = nums * 500
arr_n.append(t_da)
X = [x for x in range(1, totals)]
print(arr_n)
a = nums
while a > 0:
r = random.choice(arr_n)
# print(arr_n)
# print(r)
if X[r] != 0 and X[r - 1] != 0 and X[r + 1] != 0:
# print(r)
X.insert(r, 0)
a -= 1
z = X.index(0)
nn = 0
while z:
nn += 1
t = tuple(X[:z])
print(nn, X[:z])
X = X[z + 1:]
try:
z = X.index(0)
except ValueError:
print(s_r, X)
break
def doProcess(sfname=None):
fname = sfname
bk = xlrd.open_workbook(fname)
shxrange = range(bk.nsheets)
sh = bk.sheet_by_name("Sheet1")
# 列数
da = sh.nrows
ncols = sh.ncols
rows = sh.row_values(0)
list1 = []
list2 = []
list3 = []
# 统计总数据,分组切割
totals = da
s_r = math.ceil(totals / 500)
# print(s_r,888)
arr_n = []
nums = 0
for n in range(1, s_r):
nums += 1
t_da = nums * 500
arr_n.append(t_da)
X = [x for x in range(1, totals)]
# print(X)
a = nums
# print(arr_n)
while a > 0:
r = random.choice(arr_n)
if X[r] != 0 and X[r - 1] != 0 and X[r + 1] != 0:
X.insert(r, 0)
a -= 1
z = X.index(0)
nn = 0
while z:
if z!=500:
z = 500
nn += 1
t = tuple(X[:z])
arrs = []
# time.sleep(3)
# if X[:z][-1]==0:
# print(type(X[:z][-1]),X[:z][-1], X[:z][-2], X[:z][-2] + 1)
# X[:z][-1] = (X[:z][-2]+1,)
# print(X[:z][-1])
#
# if X[:z][-2] == 0:
# print(X[:z][-2], X[:z][-1], X[:z][-1] + 1,222)
# X[:z][-2] = (X[:z][-1] + 1,)
# print(X[:z][-2])
list2.append(X[:z])
X = X[z + 1:]
try:
z = X.index(0)
except ValueError:
if s_r:
three = X[0]-1
# print(three)
# X.append(three)
# print(s_r,X)
for ii in X:
rowss = sh.row_values(ii)
goodid = int(rowss[0])
skuids = goodid
list2.append(X)
break
nus=0
for ff in list2:
nus+=1
if ff[-1] == 0:
ff[-1] = ff[-2]+1
if ff[-2] == 0:
ff[-2] = ff[-1]+1
if ff[-1]%500 !=0:
ff[-1] = 0
# print(ff)
t1 = threading.Thread(target=write_excel, args=(ff,nus,sh))
t2 = threading.Thread(target=write_excel_two, args=(ff,nus,sh))
t3 = threading.Thread(target=write_excel_three, args=(ff,nus,sh))
t1.setDaemon(True)
t1.start()
t2.setDaemon(True)
t2.start()
t3.setDaemon(True)
t3.start()
# print(ff[1])
tkinter.messagebox.showinfo('提示', '处理Excel文件的添加成功。')
def log2():
#
# 判断编辑框的内容
# messagebox.showinfo(title="提示",message="取消登录!")
if messagebox.askokcancel("确定", "取消操作!!"):
root.destroy()
def log1():
#
sku = e_1.get()
num = e_2.get()
iscode = comboxlist.get()
print(sku, num,iscode)
def go(*args): # 处理事件,*args表示可变参数
print(comboxlist.get()) # 打印选中的值
# 初始化
root = Tk()
# 设置窗体标题
root.title('Excel 数据上传')
# 设置窗口大小和位置
root.geometry('500x300+570+200')
f_1 = tk.Frame(root)
f_1.place(x=100, y=50)
# 标签1
l_1 = tk.Label(f_1, text="SKU:")
l_1.pack()
# 标签2
l_2 = tk.Label(f_1, text="数量:")
l_2.pack()
l_21 = tk.Label(f_1, text="代贴条码:")
l_21.pack()
f_2 = tk.Frame(root)
f_2.place(x=170, y=50)
f_3 = tk.Frame(root)
f_3.place(x=320, y=90)
# 编辑框1
e_1 = tk.Entry(f_2, width=20)
e_1.pack()
# f_5 = tk.Frame(root)
# f_5.place(x=180, y=180)
# 编辑框2,隐藏输入的内容
e_2 = tk.Entry(f_2, width=20)
e_2.pack()
f_0 = tk.Frame(root)
f_0.place(x=80, y=20)
label1 = tk.Label(f_0, text='请选择文件:')
label1.pack()
# label1 = tk.Frame(root)
# label1.place(x=470, y=50)
# text1 = Entry(root, bg='red', width=20)
# text1.pack()
text1 = tk.Frame(root)
# text1.place(x=70, y=20)
button1 = Button(root, text='浏览', width=8, command=lambda: thread_it(selectExcelfile))
e_3 = tk.Entry(text1, width=20)
e_3.pack()
label1.pack()
text1.pack()
button1.pack()
# label1.place(x=30, y=30)
text1.place(x=170, y=15)
button1.place(x=350, y=13)
f_3 = tk.Frame(root)
f_3.place(x=190, y=190)
# 创建登陆按钮
button = tk.Button(f_3, text="执行",width = 10, height = 1, command=log1, bg="green")
button.pack()
f_4 = tk.Frame(root)
f_4.place(x=290, y=190)
# 创建取消按钮
button = tk.Button(f_4, text="取消",width = 10, height = 1, command=log2, bg="red")
button.pack()
comvalue = tk.Frame(root) # 窗体自带的文本,新建一个值
f_5 = tk.Frame(root) # 窗体自带的文本,新建一个值
f_5.place(x=160,y=100)
comboxlist = ttk.Combobox(f_5, textvariable=comvalue) # 初始化
comboxlist["values"] = ("是", "否")
comboxlist.current(0) # 选择第一个
comboxlist.bind("<<ComboboxSelected>>", go) # 绑定事件,(下拉列表框被选中时,绑定go()函数)
e_5 = tk.Entry(comboxlist, width=10)
comboxlist.pack()
# e_5.pack()
root.mainloop()
def thread_it(func, *args):
'''将函数打包进线程'''
# 创建
t = threading.Thread(target=func, args=args)
# 守护 !!!
t.setDaemon(True)
# 启动
t.start()
# 阻塞--卡死界面!
# t.join()
if __name__ == "__main__":
main()
模板
看下结果:
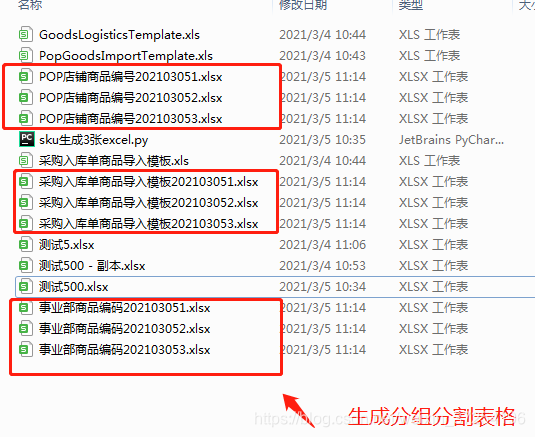
看下分组分割部分代码:
s_r = math.ceil(totals / 500)
print(s_r)
arr_n = []
nums = 0
for n in range(1, s_r):
nums += 1
t_da = nums * 500
arr_n.append(t_da)
X = [x for x in range(1, totals)]
print(arr_n)
a = nums
while a > 0:
r = random.choice(arr_n)
# print(arr_n)
# print(r)
if X[r] != 0 and X[r - 1] != 0 and X[r + 1] != 0:
# print(r)
X.insert(r, 0)
a -= 1
z = X.index(0)
nn = 0
while z:
nn += 1
t = tuple(X[:z])
print(nn, X[:z])
X = X[z + 1:]
try:
z = X.index(0)
except ValueError:
print(s_r, X)
break
欢迎下方留言!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









