







HashMap是怎么解决哈希冲突的?
在解决这个问题之前,我们首先需要知道什么是哈希冲突,而在了解哈希冲突之前我们还要知道什么是哈希才行;
什么是哈希?
Hash,一般翻译为“散列”,也有直接音译为“哈希”的, Hash就是指使用哈希算法是指把任意长度的二进制映射为固定长度的较小的二进制值,这个较小的二进制值叫做哈希值。
什么是哈希冲突?
当两个不同的输入值,根据同一散列函数计算出相同的散列值的现象,我们就把它叫做碰撞(哈希碰撞)。
HashMap的数据结构
在Java中,保存数据有两种比较简单的数据结构:数组和链表。
-
数组的特点是:寻址容易,插入和删除困难;
-
链表的特点是:寻址困难,但插入和删除容易;
所以我们将数组和链表结合在一起,发挥两者各自的优势,就可以使用俩种方式:链地址法和开放地址法可以解决哈希冲突:
- 链表法就是将相同hash值的对象组织成一个链表放在hash值对应的槽位;
- 开放地址法是通过一个探测算法,当某个槽位已经被占据的情况下继续查找下一个可以使用的槽位。
但相比于hashCode返回的int类型,我们HashMap初始的容量大小DEFAULT_INITIAL_CAPACITY = 1 << 4 (即2的四次方16)要远小于int类型的范围,所以我们如果只是单纯的用hashCode取余来获取对应的bucket这将会大大增加哈希碰撞的概率,并且最坏情况下还会将HashMap变成一个单链表,所以我们还需要对hashCode作一定的优化
hash()函数
上面提到的问题,主要是因为如果使用hashCode取余,那么相当于参与运算的只有hashCode的低位,高位是没有起到任何作用的,所以我们的思路就是让hashCode取值出的高位也参与运算,进一步降低hash碰撞的概率,使得数据分布更平均,我们把这样的操作称为扰动,在JDK 1.8中的hash()函数如下:
static final int hash(Object key) {
int h;
// 与自己右移16位进行异或运算(高低位异或)
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
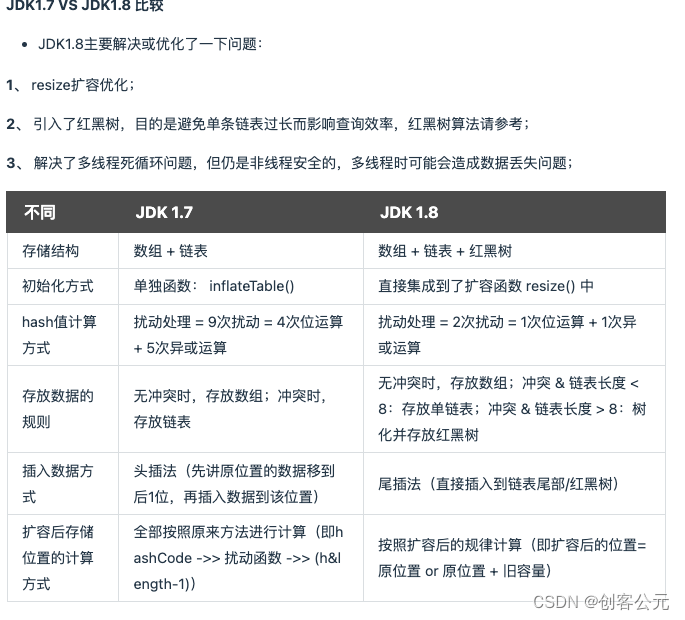
这比在JDK 1.7中,更为简洁,相比在1.7中的4次位运算,5次异或运算(9次扰动),
在1.8中,只进行了1次位运算和1次异或运算(2次扰动);
总结
简单总结一下HashMap是使用了哪些方法来有效解决哈希冲突的:
链表法就是将相同hash值的对象组织成一个链表放在hash值对应的槽位;
开放地址法是通过一个探测算法,当某个槽位已经被占据的情况下继续查找下一个可以使用的槽位。
JDK1.7 VS JDK1.8 比较
















 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









