







今天和大家分享一下
1.作业(job),2.调度(scheduler),3.程序(program),4.链(chain),4.作业类(job_class),5.窗口(window),6.窗口组(window_group)
彻底揭开他们神秘的面纱。
在oracle 8i,9i中使用dbms_job方式留作业。其限制有二。
一是调度的时间不好控制,不太灵活,对时间的间隔难于把握。
二是不能调度操作系统的脚本,只能调度数据库内的程序或者语句。
随着技术的发展,oracle在10g,11g 中推出了新的一代调度程序dbms_scheduler,这个程序克服了上面的两个缺点。
下面我们介绍如何使用调度程序dbms_scheduler。
我们首先了解一下时间间隔的问题。
repeat_interval => 'FREQ=MINUTELY; INTERVAL=30'
这句话的含义为:每30分钟运行重复运行一次!
repeat_interval => 'FREQ=YEARLY; BYMONTH=MAR,JUN,SEP,DEC; BYMONTHDAY=30'
这句话的含义为:每年的3,6,9,12月的30号运行job
一眼看上去格式有点乱,没有章法,不如以前的时间间隔明白。因为我们不知道格式的含义。
日历表达式基本分为三部分:
第一部分是频率,也就是"FREQ"这个关键字,它是必须指定的;
第二部分是时间间隔,也就是"INTERVAL"这个关键字,取值范围是1-999. 它是可选的参数;
最后一部分是附加的参数,可用于精确地指定日期和时间,它也是可选的参数,例如下面这些值都是合法的:
BYMONTH,BYWEEKNO,BYYEARDAY,BYMONTHDAY,BYDAY,BYHOUR,BYMINUTE,BYSECOND
repeat_interval => 'FREQ=HOURLY; INTERVAL=2' 每隔2小时运行一次job
repeat_interval => 'FREQ=DAILY' 每天运行一次job
repeat_interval => 'FREQ=WEEKLY; BYDAY=MON,WED,FRI" 每周的1,3,5运行job
既然说到了repeat_interval,你可能要问:“有没有一种简便的方法来得出,或者说是评估出job的每次运行时间,以及下一次的运行时间呢?”
dbms_scheduler包提供了一个过程evaluate_calendar_string,可以很方便地完成这个需求. 来看下面的例子:
declare
L_start_date TIMESTAMP; --声明需要的变量
l_next_date TIMESTAMP;
l_return_date TIMESTAMP;
begin
l_start_date := trunc(SYSTIMESTAMP); --取当前的时间
l_return_date := l_start_date;
for ctr in 1..10 loop --循环10次
dbms_scheduler.evaluate_calendar_string(
'FREQ=DAILY; BYDAY=MON,TUE,WED,THU,FRI; BYHOUR=7,15',
l_start_date, l_return_date, l_next_date);
dbms_output.put_line('Next Run on: ' ||
to_char(l_next_date,'mm/dd/yyyy hh24:mi:ss')); --打印下次运行的时间
l_return_date := l_next_date;
end loop;
end;
/
结果如下:
Next Run on: 08/08/2014 07:00:00
Next Run on: 08/08/2014 15:00:00
Next Run on: 08/11/2014 07:00:00
Next Run on: 08/11/2014 15:00:00
Next Run on: 08/12/2014 07:00:00
Next Run on: 08/12/2014 15:00:00
Next Run on: 08/13/2014 07:00:00
Next Run on: 08/13/2014 15:00:00
Next Run on: 08/14/2014 07:00:00
Next Run on: 08/14/2014 15:00:00
我们看一下数据库自己带的调度的时间间隔。
SQL>select job_name,repeat_interval from dba_scheduler_jobs;
JOB_NAME REPEAT_INTERVAL
------------------------------ ------------------------------------------
AUTO_SPACE_ADVISOR_JOB
GATHER_STATS_JOB
FGR$AUTOPURGE_JOB freq=daily;byhour=0;byminute=0;bysecond=0
PURGE_LOG
RLM$SCHDNEGACTION FREQ=MINUTELY;INTERVAL=60
RLM$EVTCLEANUP FREQ = HOURLY; INTERVAL = 1
已选择6行。
我们发现有6个作业存在,但只有3个有时间的间隔。
很好理解,每天0点运行,其它的为间隔1小时运行,但为什么有3个没有时间间隔呢?
col SCHEDULE_NAME for a25
SQL> select JOB_NAME,REPEAT_INTERVAL,SCHEDULE_NAME from DBA_SCHEDULER_JOBS;
JOB_NAME REPEAT_INTERVAL SCHEDULE_NAME
----------------------- --------------------------------------------- ------------------------
AUTO_SPACE_ADVISOR_JOB MAINTENANCE_WINDOW_GROUP
GATHER_STATS_JOB MAINTENANCE_WINDOW_GROUP
FGR$AUTOPURGE_JOB freq=daily;byhour=0;byminute=0;bysecond=0
PURGE_LOG DAILY_PURGE_SCHEDULE
RLM$SCHDNEGACTION FREQ=MINUTELY;INTERVAL=60
RLM$EVTCLEANUP FREQ = HOURLY; INTERVAL = 1
已选择6行。
我们看到一个现象,有时间间隔的没有调度的名称,有调度名称的就没有时间间隔。
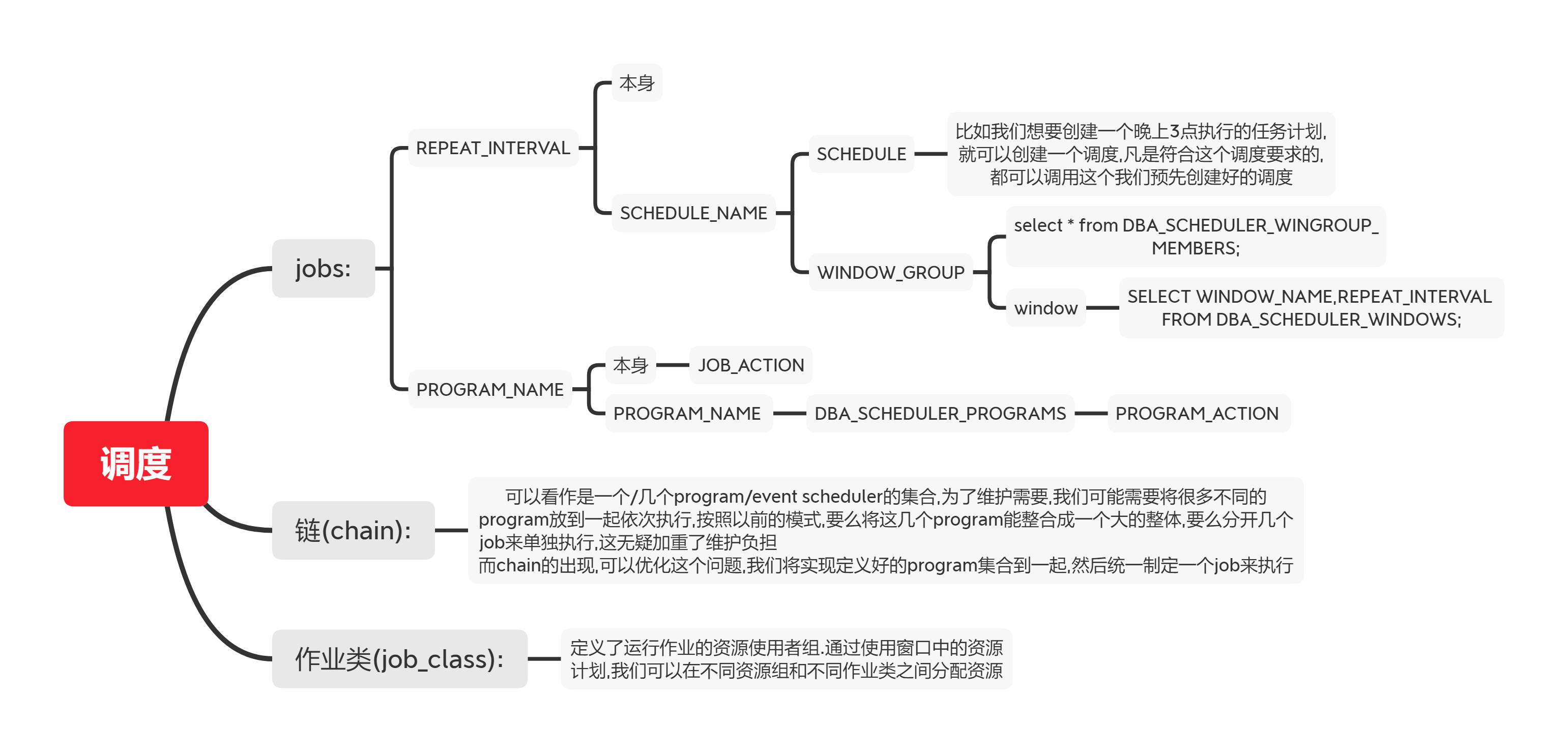
那什么是调度呢?数据库为常用的时间间隔编写一个程序策略。叫做调度(scheduler)。
例如:
一个任务计划执行的时间策略.比如我们想要创建一个晚上3点执行的任务计划,就可以创建一个调度,凡是符合这个调度要求的,都可以调用这个我们预先创建好的调度.可以用dbms_scheduler.create_schedule来创建一个调度.
比如我创建一个名字叫MYTEST_SCHEDULE的调度,每天4:00执行.
dbms_scheduler.create_schedule(
repeat_interval => 'FREQ=DAILY;BYHOUR=4;BYMINUTE=0;BYSECOND=0',
start_date => systimestamp at time zone 'PRC',
comments => '---this is my test schedule---',
schedule_name => 'MYTEST_SCHEDULE');
END;
/
上面我们看到PURGE_LOG的作业调度为DAILY_PURGE_SCHEDULE。
2 SCHEDULE_NAME='DAILY_PURGE_SCHEDULE';
REPEAT_INTERVAL
---------------------------------------------
freq=daily;byhour=3;byminute=0;bysecond=0
我们看到了该策略为每天3点运行。
但GATHER_STATS_JOB的调度为MAINTENANCE_WINDOW_GROUP,这又是什么呢?
这是窗口组!
WINDOW_GROUP_NAME WINDOW_NAME
------------------------------ -------------------
MAINTENANCE_WINDOW_GROUP WEEKNIGHT_WINDOW
MAINTENANCE_WINDOW_GROUP WEEKEND_WINDOW
我们看到维护窗口组MAINTENANCE_WINDOW_GROUP中有两个窗口。
窗口又是什么呢?
SQL> COL REPEAT_INTERVAL FOR A79
SQL> SELECT WINDOW_NAME,REPEAT_INTERVAL FROM DBA_SCHEDULER_WINDOWS;
WINDOW_NAME REPEAT_INTERVAL
-------------------- ---------------------------------------------------------------------
WEEKNIGHT_WINDOW freq=daily;byday=MON,TUE,WED,THU,FRI;byhour=22;byminute=0; bysecond=0
WEEKEND_WINDOW freq=daily;byday=SAT;byhour=0;byminute=0;bysecond=0
平时每天晚上10点运行,周六0点运行!
窗口(window):
可以看成是一个更高功能的调度,窗口可以调用系统中存在的调度(也可以自行定义执行时间),而且,具有资源计划限制功能,窗口可以归属于某个窗口组.
可以使用DBMS_SCHEDULER.CREATE_WINDOW来创建一个窗口.
例如我创建了一个名为mytest_windows_1的窗口,采用DAILY_PURGE_SCHEDULE的调度方式,资源计划限制方案为 SYSTEM_PLAN,持续时间为4小时.
DBMS_SCHEDULER.CREATE_WINDOW(
window_name=>'mytest_windows_1',
resource_plan=>'SYSTEM_PLAN',
schedule_name=>'SYS.DAILY_PURGE_SCHEDULE',
duration=>numtodsinterval(240, 'minute'),
window_priority=>'LOW',
comments=>'');
END;
/
窗口组(window_group):
一个/几个窗口的集合.10g默认的自动采集统计信息的调度就是一个窗口组的形式,譬如,设置两个窗口,窗口一指定任务周日-----周五,晚上12点执行,而窗口二设定周六凌晨3点执行,这两个窗口组成了一个窗口组,形成了这个job的执行调度策略.
可以使用DBMS_SCHEDULER.CREATE_WINDOW_GROUP来创建一个窗口组.
DBMS_SCHEDULER.CREATE_WINDOW_GROUP(
group_name=>'mytest_window_group',
window_list=>'MYTEST_WINDOWS_1,WEEKEND_WINDOW');
END;
/
关于调度时间的问题我们搞清楚了,现在我们看一下调度的内容问题!
SQL> select JOB_NAME,PROGRAM_NAME from DBA_SCHEDULER_JOBS;
JOB_NAME PROGRAM_NAME
----------------------- --------------------------------------
AUTO_SPACE_ADVISOR_JOB AUTO_SPACE_ADVISOR_PROG
GATHER_STATS_JOB GATHER_STATS_PROG
FGR$AUTOPURGE_JOB
PURGE_LOG PURGE_LOG_PROG
RLM$SCHDNEGACTION
RLM$EVTCLEANUP
已选择6行。
我们还研究GATHER_STATS_JOB这个作业,这个作业做什么?是一个程序,叫做GATHER_STATS_PROG,GATHER_STATS_PROG内容是什么呢?
where PROGRAM_NAME='GATHER_STATS_PROG';
PROGRAM_ACTION
---------------------------------------------------------------------
dbms_stats.gather_database_stats_job_proc
啊,原来就是一个存储过程。我们一步步的把调度的神秘面纱剥掉了!
现在我总结一下:有个程序GATHER_STATS_PROG,该程序调用了一个存储过程。
有个窗口组MAINTENANCE_WINDOW_GROUP,其内含有平时和周末两个策略。
我们的作业GATHER_STATS_JOB就是在MAINTENANCE_WINDOW_GROUP窗口组的时间内运行程序GATHER_STATS_PROG。搞的挺复杂,其实不难!
调度中还有两个概念我们没有讲到。一个为链(chain),一个为作业类(job_class)。
链(chain):
链可以看作是一个/几个program/event scheduler的集合,为了维护需要,我们可能需要将很多不同的program放到一起依次执行,按照以前的模式,要么将这几个program能整合成一个大的整体,要么分开几个job来单独执行,这无疑加重了维护负担,而chain的出现,可以优化这个问题,我们将实现定义好的program集合到一起,然后统一制定一个job来执行,可以使用dbms_scheduler.create_chain来创建一个chain.
比如,在我的系统中,我分别创建了一个EXECUTABLE类型的和一个STORED PROCEDURE类型的program,我需要他们顺次执行,于是我可以这么做:
dbms_scheduler.create_chain( chain_name =>'MYTEST_CHAIN');
dbms_scheduler.define_chain_step(chain_name =>'MYTEST_CHAIN', step_name =>'mytest_chain_1',program_name =>'P_1');
dbms_scheduler.alter_chain(chain_name =>'MYTEST_CHAIN', step_name =>'mytest_chain_1',attribute=>'skip',value=>FALSE);
dbms_scheduler.define_chain_step(chain_name =>'MYTEST_CHAIN',step_name =>'mytest_chain_2',program_name =>'P_2');
dbms_scheduler.alter_chain(chain_name =>'MYTEST_CHAIN',step_name =>'mytest_chain_2',attribute=>'skip', value=>FALSE);
dbms_scheduler.enable('MYTEST_CHAIN');
END;
/
作业类(job_class):
定义了运行作业的资源使用者组.通过使用窗口中的资源计划,我们可以在不同资源组和不同作业类之间分配资源.可以使用 dbms_scheduler.create_job_class创建一个作业类.
dbms_scheduler.create_job_class(
logging_level => DBMS_SCHEDULER.LOGGING_RUNS,
log_history => 100,
resource_consumer_group => 'AUTO_TASK_CONSUMER_GROUP',
job_class_name => 'MYTEST_JOB_CLASS');
END;
/
调度的概念都讲解完了,我们总结一下:
-
作业(job),2.调度(scheduler),3.程序(program),4.链(chain),4.作业类(job_class),5.窗口(window),6.窗口组(window_group)
这些不是必须的。我们可以直接留作业,和以前dbms_job一样,而且可以运行操作系统的脚本。
dbms_scheduler.create_job
(
job_name => 'ARC_MOVE',
repeat_interval => 'FREQ=MINUTELY; INTERVAL=30',
job_type => 'EXECUTABLE',
job_action => '/home/dbtools/move_arcs.sh',
enabled => true,
comments => 'Move Archived Logs to a Different Directory'
);
end;
/
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/12798004/viewspace-1247636/,如需转载,请注明出处,否则将追究法律责任。
总结:
拓展阅读
部分截取自互联网,如有侵权请与我联系。
wechat: 704012932
email: pkweibu@163.com
CSDN: https://blog.csdn.net/weixin_37423880














 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









