







 本文详细介绍了如何在阿里云Serverless K8S(ASK)集群上部署Spark任务,并连接OSS进行数据处理。内容涵盖环境准备、OSS数据准备、代码编写与打包、Docker镜像制作、ASK集群创建、任务提交及结果查看等步骤。
本文详细介绍了如何在阿里云Serverless K8S(ASK)集群上部署Spark任务,并连接OSS进行数据处理。内容涵盖环境准备、OSS数据准备、代码编写与打包、Docker镜像制作、ASK集群创建、任务提交及结果查看等步骤。
在阿里云ASK集群上部署Spark任务并连接OSS
简介
ASK是阿里云的一个产品,属于Serverless Kubernetes 集群,这次实验是要在ASK集群上运行Spark计算任务(以WordCount为例),另外为了能让计算和存储分离,我使用了阿里云OSS来存放数据。
(连接OSS这块找了好多资料都不全,在本地可以运行的代码一放在集群就报错,遇到很多bug才终于弄好了,记录下来希望对以后的小伙伴有帮助)
环境准备
本机需要安装:
JAVA jdk1.8
IDEA
Maven
Docker(安装在Linux或者Windows)
需要在阿里云开通的服务有:
ASK集群:https://www.aliyun.com/product/cs/ask?spm=5176.166170.J_8058803260.27.586451643ru45z
OSS对象存储: https://www.aliyun.com/product/oss?spm=5176.166170.J_8058803260.32.58645164XpoJle
ACR镜像服务:https://www.aliyun.com/product/acr?spm=5176.19720258.J_8058803260.31.281e2c4astzVxy
一、在OSS中准备数据
- 在OSS对象存储中上传好txt文件(我的是hp1.txt)
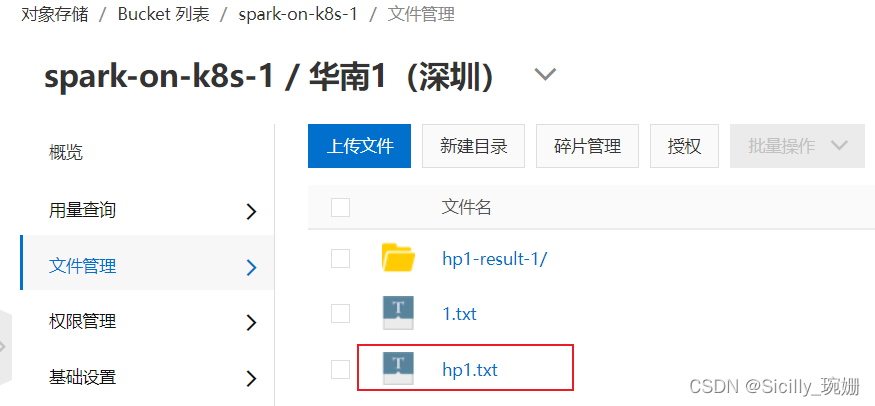
则访问该文件的url为,
oss://spark-on-k8s-1/hp1.txt
(按照这种【oss://桶名/路径/文件名】格式改成你自己的,后面代码要用到)
二、编写代码
1.使用IDEA新建一个maven项目
目录结构如下:
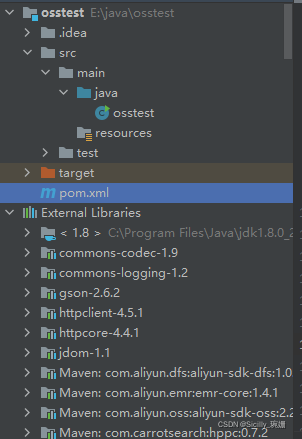
需要写的就只有pom.xml文件和java下的osstest.java文件。下面会给出代码:
(1)osstest.java
这是一份词频统计(wordcount)的代码。步骤是:
- 连接OSS,获取到实现准备好的hp1.txt文件
- 对hp1.txt进行词频统计
- 把最终结果传回到OSS上
具体实现如下:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
public class osstest {
public static void main(String[] args) {
// 这些都是OSS的依赖包,不写的话在本地能跑,放上集群会报错
List<String> jarList = new ArrayList<>();
jarList.add("emr-core-1.4.1.jar");
jarList.add("aliyun-sdk-oss-3.4.1.jar");
jarList.add("commons-codec-1.9.jar");
jarList.add("jdom-1.1.jar");
jarList.add("commons-logging-1.2.jar");
jarList.add("httpclient-4.5.1.jar");
jarList.add("httpcore-4.4.1.jar");
String ossDepPath = jarList.stream()
.map(s -> "/opt/spark/jars/" + s)
.collect(Collectors.joining(","));
SparkConf conf = new SparkConf().setAppName("JavaWordCount");
// 如果在本地IDEA执行,需要打开下面一行代码
// .setMaster("local");
conf.set("spark.hadoop.fs.oss.impl", "com.aliyun.fs.oss.nat.NativeOssFileSystem");
// 如果在本地IDEA执行,需要打开下面一行代码
// conf.set("spark.hadoop.mapreduce.job.run-local", "true");
conf.set("spark.hadoop.fs.oss.endpoint", "oss-cn-shenzhen.aliyuncs.com");// 改成你存放文本的OSS桶的地区
conf.set("spark.hadoop.fs.oss.accessKeyId", "*****"); // 改成你自己的accessKeyId
conf.set("spark.hadoop.fs.oss.accessKeySecret", "******");// 改成你自己的accessKeySecret
// 需要指定oss依赖的路径,否则会报错
conf.set("spark.hadoop.fs.oss.core.dependency.path", ossDepPath 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









