







seleniumhq小记
暑假的第二个月初正好去打了2天的暑假工。
说是暑假工,其实是打字员。
看文件,然后录入文件的信息,太多重复的东西。
正常一套录入需要大概一分钟。
选择关键字过滤。 填写,下拉框吧啦吧啦。
过滤
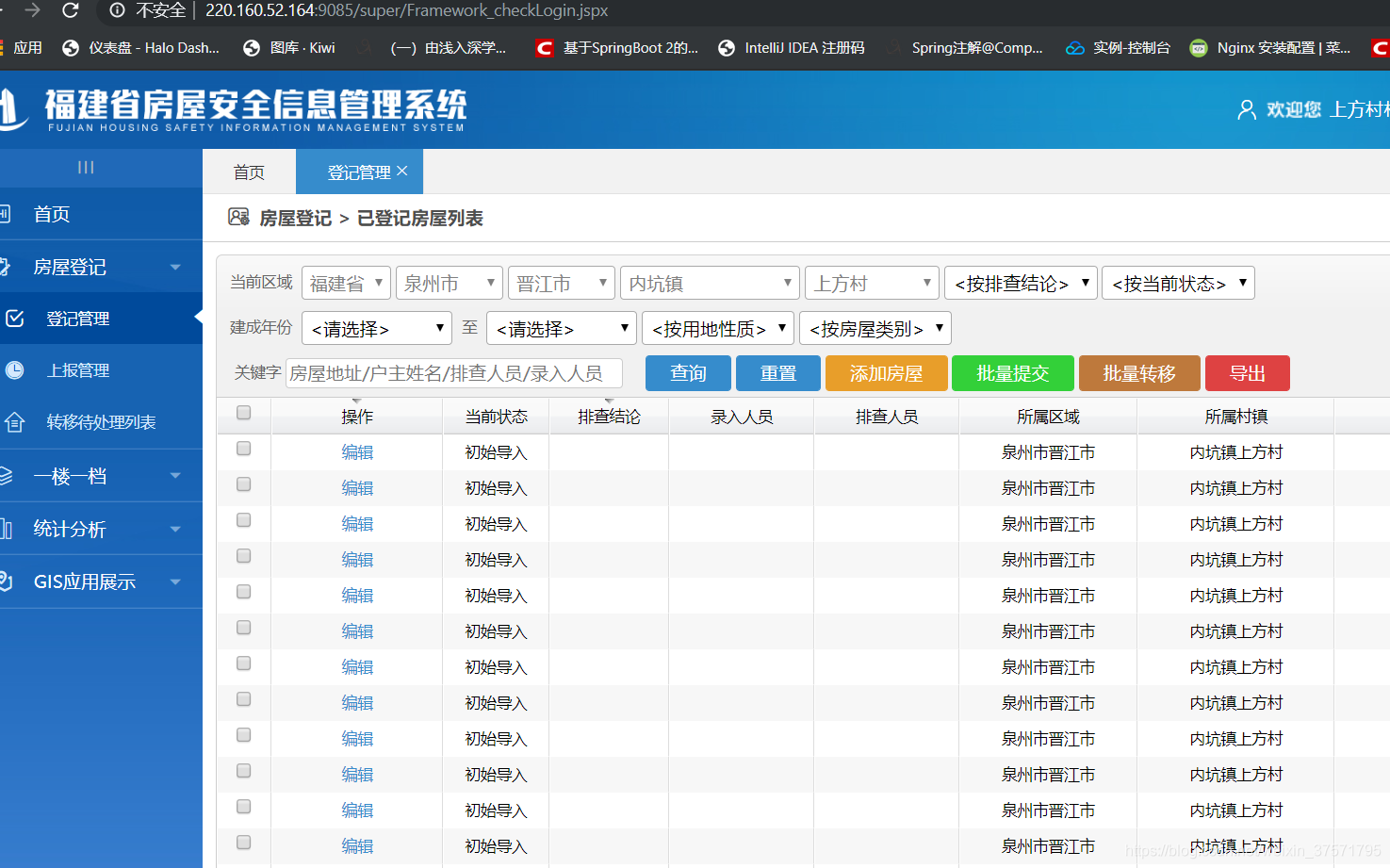
填写
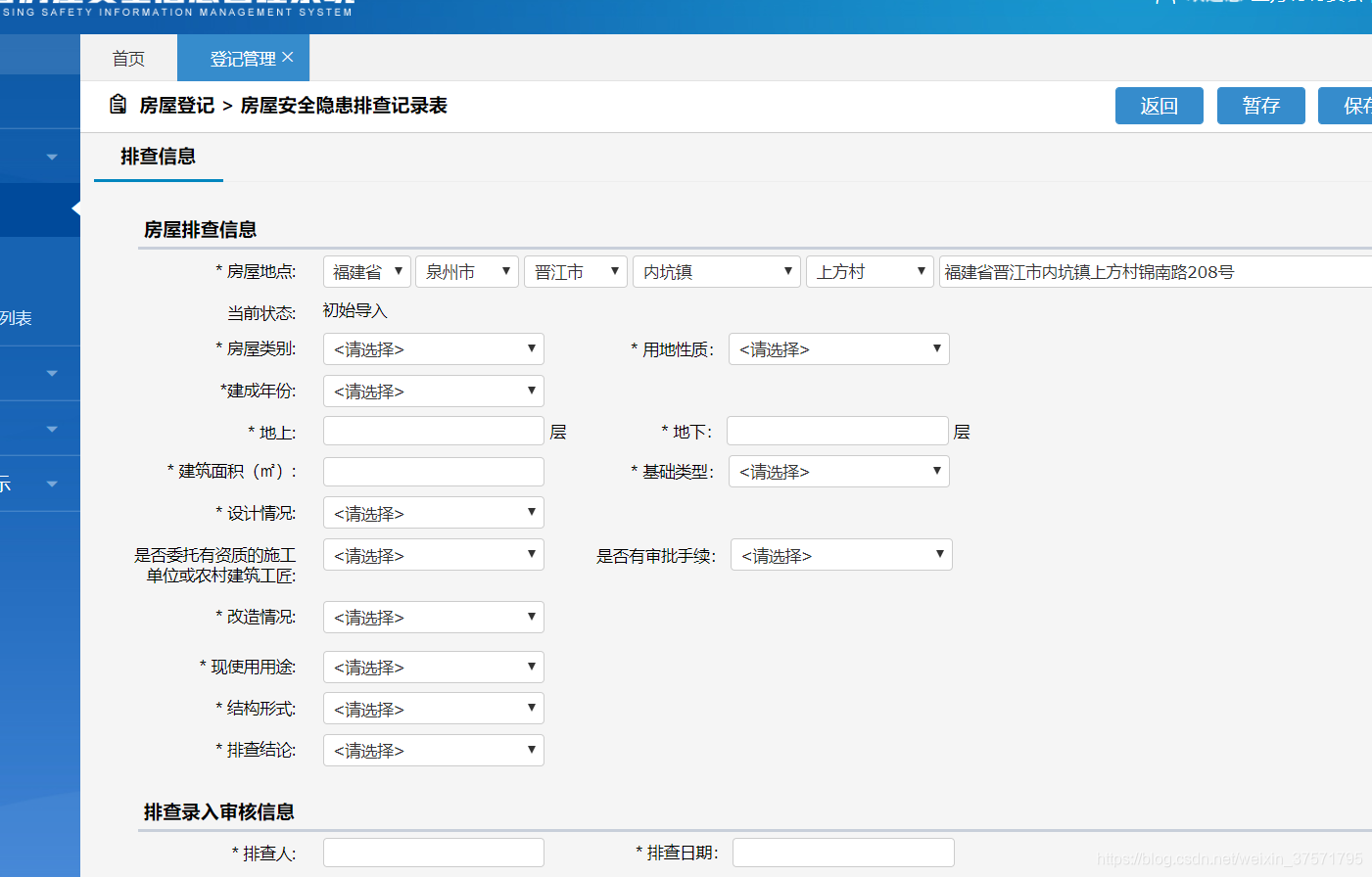
还要找到图片上传。真的麻烦。
实在是受不了了。
于是打算写个自动化填写。
开始Chrome->F12,看了一下,竟然是layui。
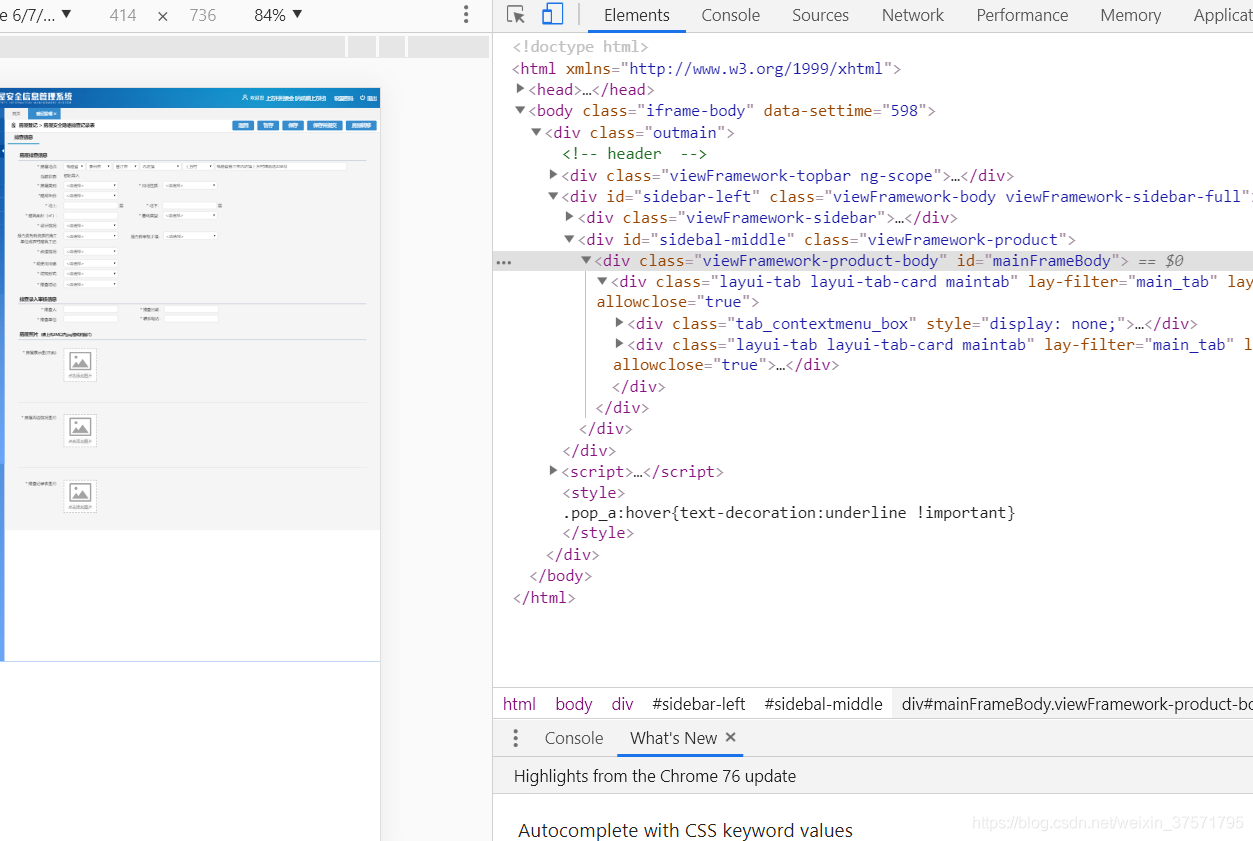
仔细看了一下url: 省略/super/Framework_checkLogin.jspx
jsp…嘻嘻。
很早的时候尝试过layui来写过某个项目,但是大概是啥忘了。
前端也是或多或少的了解。
毕竟是gov的东西。不是太敢做一些骚操作。
但是自动化填写。觉得不会太容易实现。第一个想法便是ocr加servlet。
思路很明确。ocr扫描图片,获取每一个关键字。通过servlet请求,登陆,输入等一系列黑框处理。
但是。
不是很应景,这个这么潦草的字(这个图不算潦草,潦草的比比皆是)
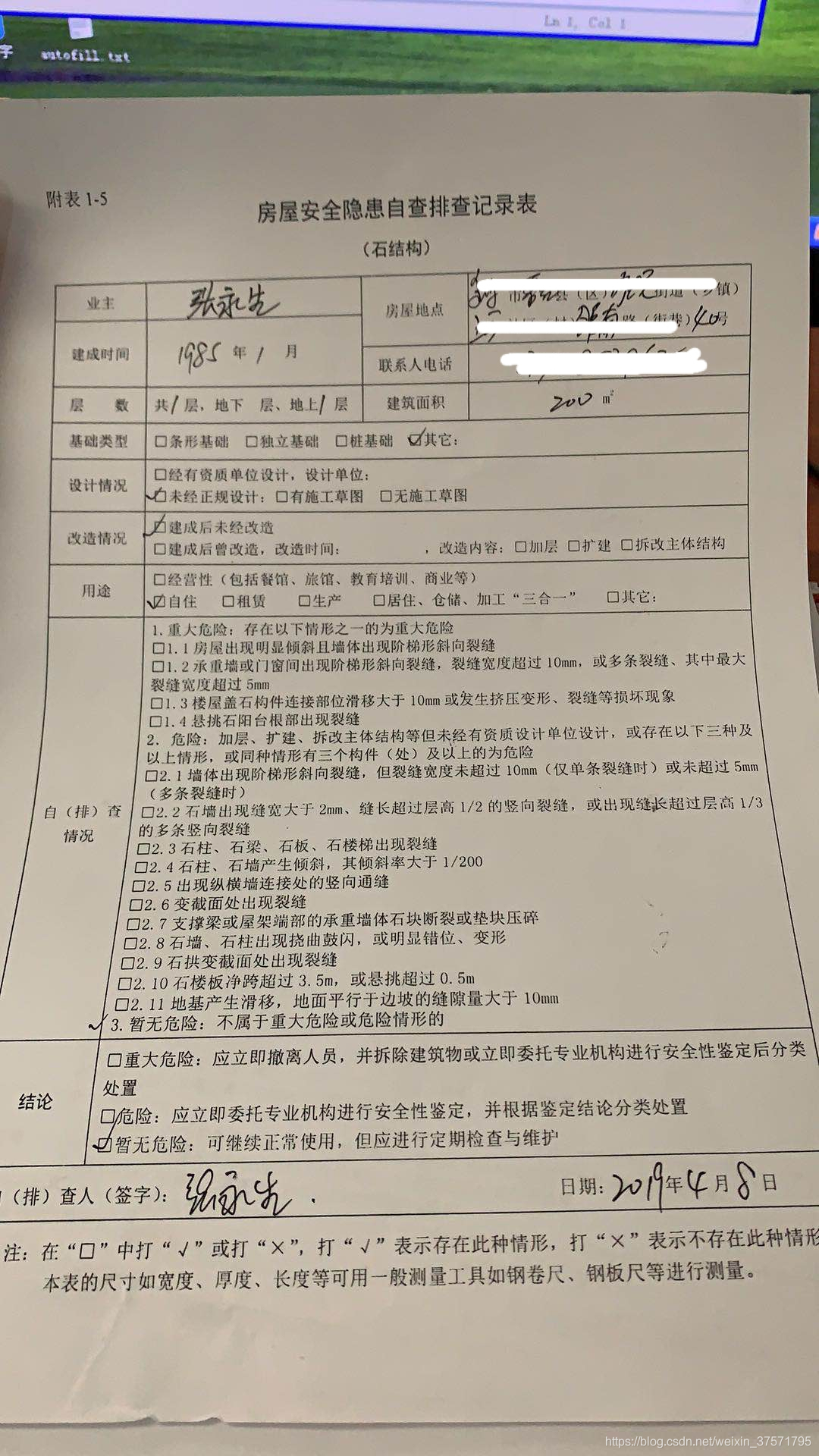
,
通过,阿里云,百度,腾讯的ocr api。
什么都没扫出来,但是还是得夸夸腾讯,百度的写了,高精度文字api,通用文字api。等等
腾讯只要文字扫描。
叮,腾讯还能识别出建成时间。房屋地点。百度凉凉。
其实也不是不可以扫描出来。可以自己弄个机器学习一波,从零开始根据开源案例。让机器学会潦草的字。只是不是太想了。
还是选择浏览器自动处理把。
通过查找。最后找到我想要的。
选择使用selenium
进入本文的话题。
用java还是python的选择,我最后选了java
虽然python写得短实现是真的快。
但是那总方式的写法依旧不习惯。但是如果拿来爬url的数据还是分析下载东西是真真的方便!这个必须力荐python。
老样子,这个玩意应该不需要任何框架。
就算不需要任何框架,还是需要maven的。毕竟如果要让我打lib dependencies?累了
先创建一个空的maven工程。
加入seleniumhq的 dependency
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-api</artifactId>
<version>3.141.59</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-chrome-driver</artifactId>
<version>3.141.59</version>
</dependency>
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
</dependency>
再加一个httpclient 万一会用到
src-main-java 创建一个java文件
以下是我的整个工程。(已经完成后的)
我用的是chrome浏览器。
seleniumhq,需要对应浏览器的driver来运行。
所以需要下载相应的driver
chromedriver与chrome的对应表
| chromedriver版本 | 支持的Chrome版本 |
|---|---|
| v2.46 | v71-73 |
| v2.44 | v70-72 |
| v2.43 | v69-71 |
| v2.42 | v69-70 |
| v2.41 | v67-69 |
| v2.40 | v66-68 |
| v2.39 | v66-68 |
| v2.38 | v65-67 |
| v2.37 | v64-66 |
| v2.36 | v63-65 |
| v2.35 | v62-64 |
| v2.34 | v61-63 |
| v2.33 | v60-62 |
| v2.32 | v59-61 |
| v2.31 | v58-60 |
| v2.30 | v58-60 |
| v2.29 | v56-58 |
| v2.28 | v55-57 |
| v2.27 | v54-56 |
| v2.26 | v53-55 |
| v2.25 | v53-55 |
| v2.24 | v52-54 |
| v2.23 | v51-53 |
| v2.22 | v49-52 |
| v2.21 | v46-50 |
driver可以去下面选择下载
Google
阿里
(谷歌进不去就阿里的)
开始代码
先import
import org.openqa.selenium.By;
import org.openqa.selenium.Keys;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
这是目前可以用到的
开始。
System.setProperty("webdriver.chrome.driver","E:\\webDriver\\chromedriver.exe");
WebDriver driver =new ChromeDriver();
driver.get("http://220.160.52.164:9085");
- 先把下好的driver找到路径,注意,一定要对应chrome的版本
- new ChromeDriver实例
- driver.get()。里面的参数是地址。“http://220.160.52.164:9085”
这个只是我当时工作用的地址,后期这个地址应该会被dns反向解析。
输入密码和账号
driver.findElement(By.id("loginname")).sendKeys("------");
driver.findElement(By.id("loginpwd")).sendKeys("-----");
这里账号密码用—代替了哈。
findElement()是seleniumhq常用的函数。
里面By.id是通过id来找到元素
findElement里面的参数有如下
- id 定位 :driver.findElement(By.id(“id的值”));
- name定位 :driver.findElement(By.name(“name的值”));
- 链接的全部文字定位: driver.findElement(By.linkText(“链接的全部文字”));
- 链接的部分文字定位: driver.findElement(By.partialLinkText(“链接的部分文字”));
- css 方式定位 :driver.findElement(By.cssSelector(“css表达式”));
- xpath 方式定位 :driver.findElement(By.xpath(“xpath表达式”));
- Class 名称定位 : driver.findElement(By.className(“class属性”));
- TagName 标签名称定位 :driver.findElement(By.tagName(“标签名称”));
- Jquery方式 :Js.executeScript(“return jQuery.find(“jquery表达式”)”)
场景简单我建议用id。
id嘛,很容易找打的。
何为场景简单呢?我们来分析一下这个网站。
按F12
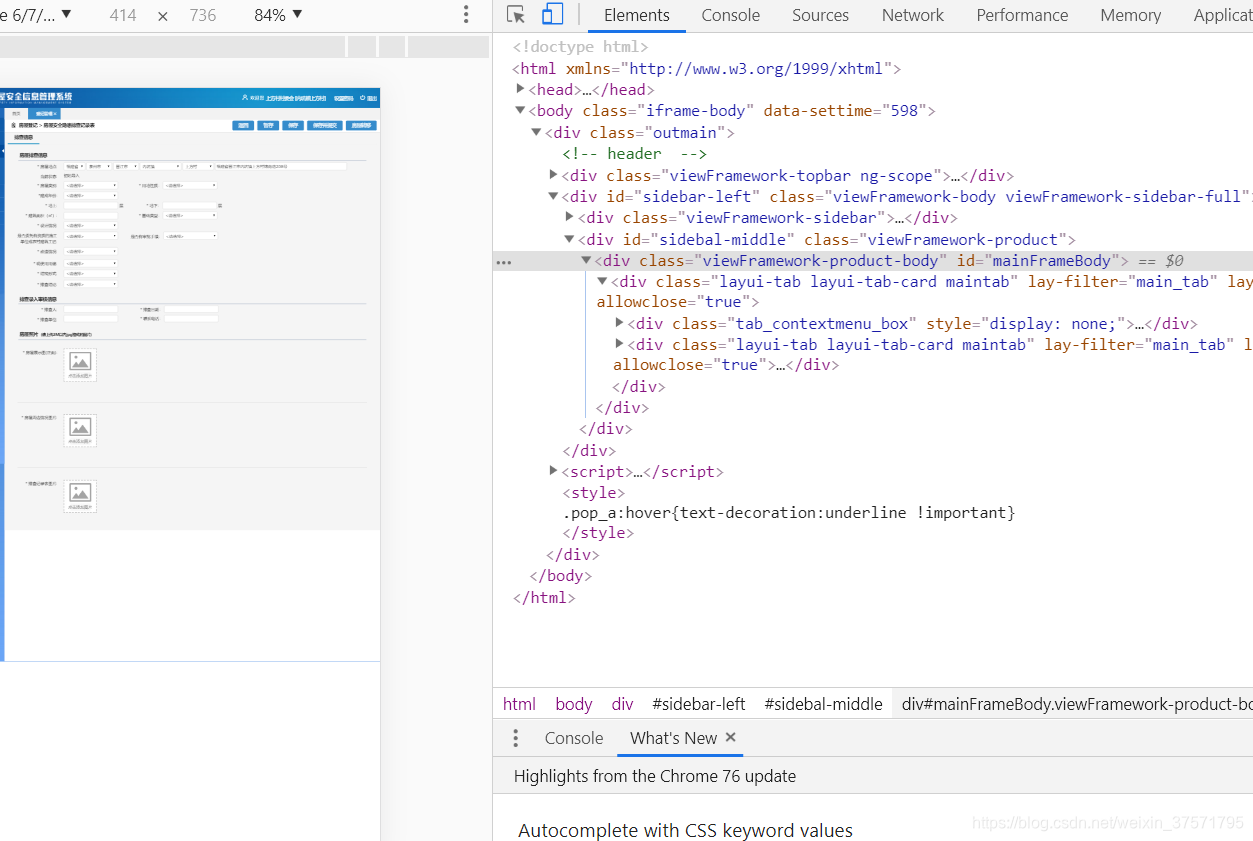
里面的元素标签很少对不对。
单纯看网站也能感觉到。
处理元素
chrome有一个很方便的方法找到元素
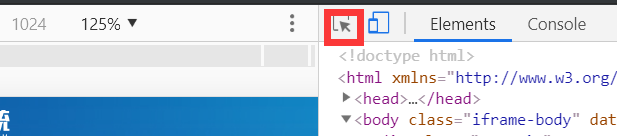
点击这个箭头。接着用鼠标去点你想要定位的元素。
如此,我们得到了“输入用户名”这个元素的定位。
id为"loginname"
于是
driver.findElement(By.id(“loginname”)).sendKeys("------");
sendkeys便是我们想要在输入框中填入的参数。
它便会自动填入 -----
账号密码填入后继续验证码
处理验证码和点击登陆按钮
System.out.println("请输入验证码");
Scanner sc=new Scanner(System.in);
String code=sc.nextLine();
driver.findElement(By.id("checkCode")).sendKeys(code);
driver.findElement(By.id("login")).click();
验证码的处理很简单。
可以使用ocr,来处理验证码的图片转化成,然后我们写入。
可以使用使用Tess4J进行ocr识别。
github有很多开源代码。下载编译即用。
但是Tess4j的使用麻烦,需要下好它的自带部件。详细可以去查。
而且Tess4j对中文的识别并不是太优秀。
但是针对纯ascii验证码就够了。
不过出于场景。我们的目的是为了让他里面填写的实现自动化。
验证码自己输入就够了。
我没有太多时间去测试和写这个ocr实现。
- 使用Scanner输入。
- 验证码传值
- 点击登陆
进入
driver.findElement(By.xpath("//span[text()=\"房屋登记\"]")).click();
driver.findElement(By.xpath("//span[text()=\"登记管理\"]")).click();
这里使用了By.xpath
xpath特别特别好用。对应复杂场景用xpath。
这里的场景,是十分的复杂的。
分析:
他的前端基于layui。
这里还有frame嵌套。
如果写过这样的前端大概是知道的。
标签使用<include > 另一个页面
正好目前还在测试的项目没关掉。
<nav class="navbar-default navbar-static-side" role="navigation" th:include="nav :: navigation"></nav>
<div id="page-wrapper" class="gray-bg">
<div class="border-bottom" th:include="header :: headerTop"></div>
<li>
<a href="#"><i class="fa fa-envelope"></i> <span class="nav-label">订单管理</span><span class="label label-warning pull-right" th:text="${session.order}"></span></a>
<ul class="nav nav-second-level collapse">
<li id="orderManage"><a th:href="@{orderManage_0_0_0}">订单管理</a></li>
<li id="orderRefund"><a th:href="@{orderRefund_0_0_0}">订单退款</a></li>
<li id="shippingManage"><a th:href="@{shippingManage_0_0_0}">发货管理</a></li>
<li id="deliveryManage"><a th:href="@{deliveryManage}">物流公司</a></li>
</ul>
</li>
这个项目基于thymeleaf模板
所以写法是如此。
引用了另一个标签页
也就是会出现标签。
里面可能会出现多个id重复。
如此。需要xpath定位。
xpath很简单。理解dom结果大致就随意能看懂。
“//span[text()=“登记管理”]”
这个意思是找到 标签里的text值未“登记管理”的元素
.click为点击
如此,seleniumhq帮我们完成了这两个按钮的点击。
内嵌标签的寻找
这里是一个重点,我找了半个小时的bug
//点击frame
driver.findElement(By.xpath("//*[@id=\"mainFrameBody\"]/div/div[2]/ul/li[2]/span")).click();
//定位frame,
driver.switchTo().frame(driver.findElement(By.xpath("//*[@id=\"mainFrameBody\"]/div/div[2]/div/div[2]/iframe")));
因为我们点击了登记管理后。
frame出现了新的标签页
所以。
-第一句
driver.findElement(By.xpath("//*[@id=“mainFrameBody”]/div/div[2]/ul/li[2]/span")).click();
我们先点击我们需要的标签页“登记管理"也就是上图没有写数字的框。
那xpath的路径是怎么获得的呢?
我肯定不是手打的。
如此,需要借助chrome了。
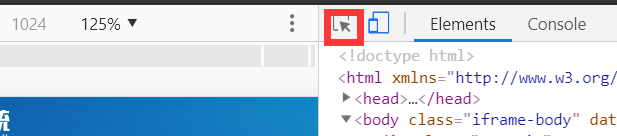
再次点击这个
定位到顶部的标签栏”登记管理

定位
按右键
copy->copy Xpath
得到
//*[@id=“mainFrameBody”]/div/div[2]/ul/li[2]/span
贴贴到By.xpath中便可。
- 第二句
定位frame
seleniumhq毕竟是一个库,编程并不会太聪明。所以需要让他自己定位到“登记管理”的frame中
使用
driver.switchTo().frame()
找到frame标签。
如果不知道怎么找,可以再到用chrome的那个小箭头点击“登记管理”
自行找到带frame的标签
这个标签教做iframe
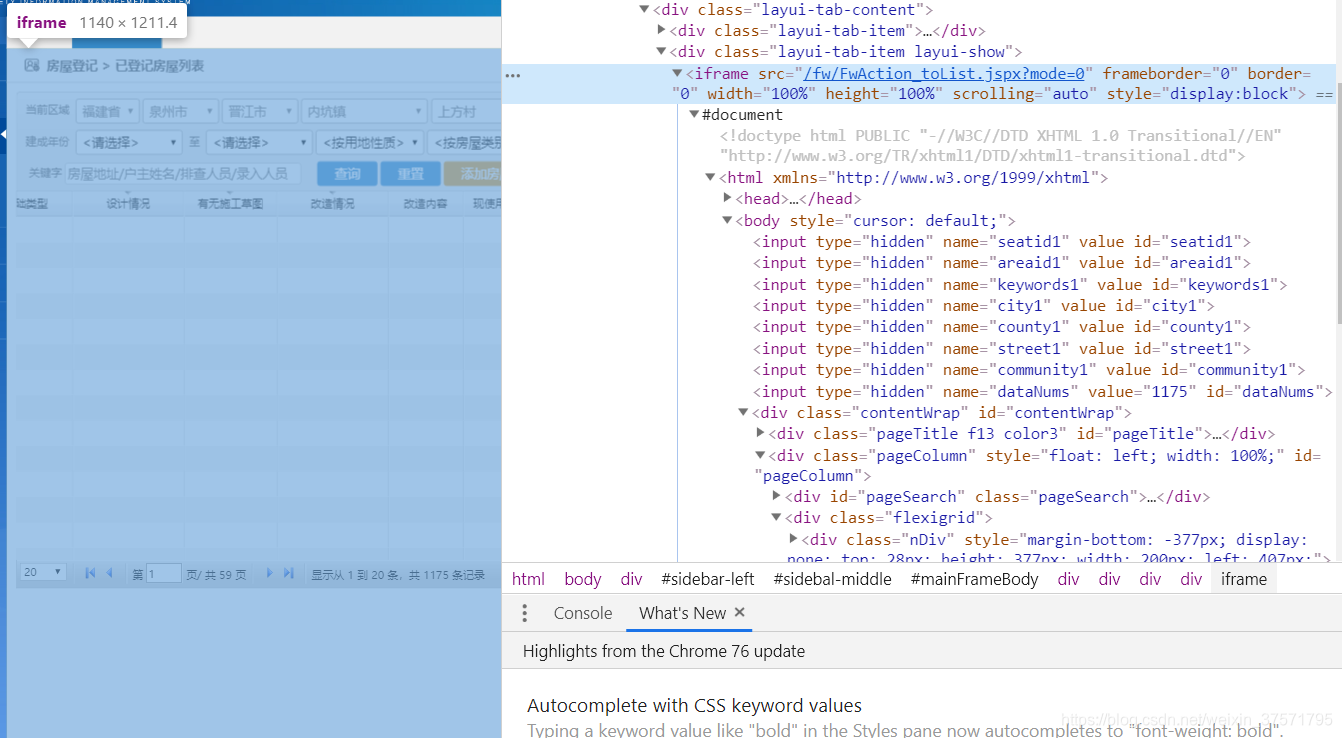
移到那个标签上,全局显示了我们想要让他进入的元素。
对了就是他。
copy xpath
driver.switchTo().frame(driver.findElement(By.xpath("//*[@id=“mainFrameBody”]/div/div[2]/div/div[2]/iframe")));
需要让他找到元素的定位才能真正的switch到frame
大功告成
输入关键字
System.out.println("请输入关键字");
String key = sc.nextLine();
String TrueKey = Constant.keyValue + key + Constant.prefix;
//传入关键字
driver.findElement(By.xpath("//*[@id=\"keywords\"]")).sendKeys(TrueKey);
//点击查询
driver.findElement(By.xpath("//*[@id=\"infoform\"]/div/input[5]")).click();
这里的Constant.keyValue 和 Constant.prefix;
是我自己设定的字符串常量。基于写代码的规范。嘻嘻
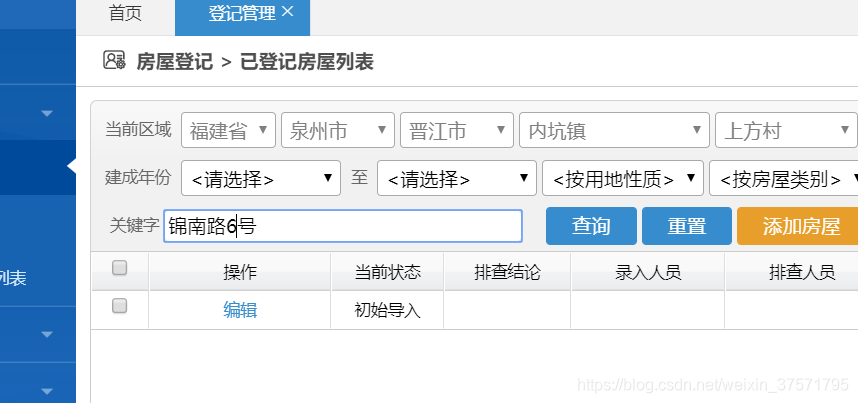
点击编辑
//回到默认frame再重新回去
driver.switchTo().defaultContent();
Thread.sleep(2);
driver.findElement(By.xpath("//*[@id=\"mainFrameBody\"]/div/div[2]/ul/li[2]/span")).click();
Thread.sleep(2);
driver.switchTo().frame(driver.findElement(By.xpath("//*[@id=\"mainFrameBody\"]/div/div[2]/div/div[2]/iframe")));
Thread.sleep(1000);
//进入编辑,默认第一个
driver.findElement(By.xpath("//*[@id=\"grid\"]/tbody/tr/td[2]/div")).click();
seleniumhq帮我们点击了查询后又会默默的变傻掉。
丢失了自己的位置,所以需要回到默认的全局页面。
使用driver.switchTo().defaultContent();
开个玩笑。
其实是点击后页面会重新请求,毕竟这个是重定向了。
如果只是简单的javascript事件就不需要。
重新使用
driver.findElement(By.xpath("//*[@id=\"mainFrameBody\"]/div/div[2]/ul/li[2]/span")).click();
driver.switchTo().frame(driver.findElement(By.xpath("//*[@id=\"mainFrameBody\"]/div/div[2]/div/div[2]/iframe")));
这两个步骤回到“登记管理”
中间穿插的Thread.sleep(2),
控制它不会因为光速点击导致自己请求失败。
注意:
driver.findElement(By.xpath("//[@id=“grid”]/tbody/tr/td[2]/div")).click();
这里的编辑按钮我们使用点击div来寻找的。
自行分析一下。

如果我们用的是
//[@id=“grid”]/tbody/tr/td[2]/div/a
这里的a标签里面的地址是动态变化的。
所以正常定位不到,但是我们点击了div标签同理能点击到“编辑”按钮
如此,我们点击了“编辑”这个按钮。
填写信息
这里的代码就不怎么详细贴出来了
但是我贴一下处理选项框的代码
System.out.print("排查人:");
String paiName = sc.nextLine();
System.out.print("排查日期:");
String paiTime = sc.nextLine();
//开始默认处理
//房屋类别
driver.findElement(By.xpath("//*[@id=\"fwlb\"]")).click();
driver.findElement(By.xpath("//*[@id=\"fwlb\"]/option[3]")).click();
自动点击选项框,并且点击选项框内嵌标签的option[?]
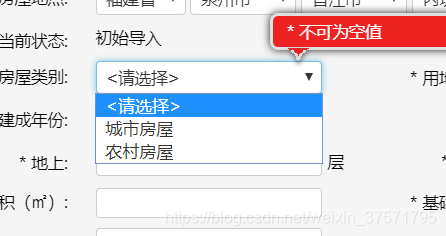
填写信息完成
图片导入
WebElement webElement = driver.findElement(By.cssSelector("body"));
webElement.click(); // 有的时候必须点击一下,下拉才能生效(有的网站是这样,原因未找到)
webElement.sendKeys(Keys.END);
//传送文件
driver.findElement(By.xpath("//*[@id=\"pcbg_upload\"]/div[2]/input")).sendKeys(Constant.arrayList.get(flag));
webElement.click(); // 有的时候必须点击一下,下拉才能生效(有的网站是这样,原因未找到)
webElement.sendKeys(Keys.UP);
代码注释已经很清除了。
这里用到了WebElement
能帮我们做出一些鼠标键盘的动作。


看一下图片的元素
div id=“”此处为动态生成的id
如果直接copy xpath会出现如下
//*[@id=“rt_rt_1dhbadv8ggdulh4af71prl1t561”]/input
ummmmmm,自己写xpath咯
pcbg_upload"]/div[2]/input 没毛病。
Constant.arrayList.get(flag)这个是我图片的路径传入的ArrayList。
随便写个循环遍历目录里的图片就行
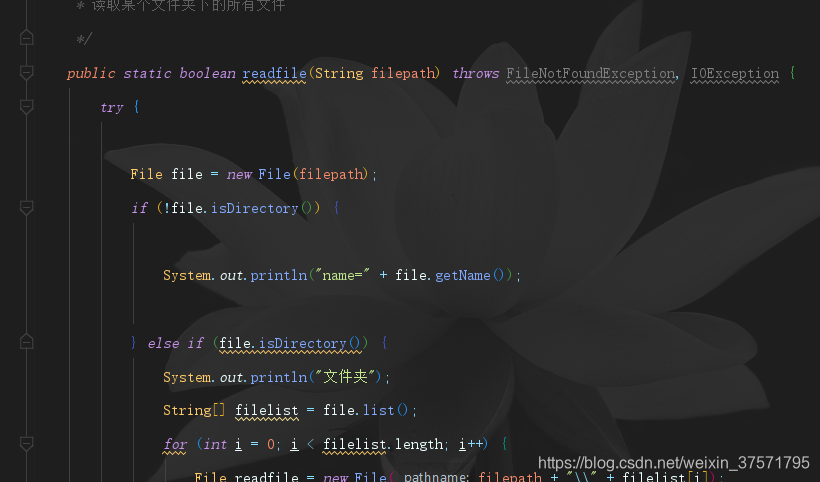
重新填写一遍
再次回到上个登记管理的页面
写个循环,没有难度。
这里有个重点。
driver.navigate().refresh();
我们刷新了页面一遍。
有session,不怕重新再登陆一次。
然后再次从最开始的
driver.findElement(By.xpath("//span[text()=\"房屋登记\"]")).click();
driver.findElement(By.xpath("//span[text()=\"登记管理\"]")).click();
开始一遍。
小结
那时候从下午6点开始写到晚上1点才写完这个自动化处理。
最后这个离开这个暑假工了。
毕竟还是得敲文档得字,对照。
其实如果我自己写个机器学习让他辨认那个文件的字应该就好多了。可是没时间学习了。
但是或多或少的学会了selenium的用法
可以运用再大学时的挂课上,还是一些烦琐的录入情况。
当然,配合ocr api无敌。
源码
后续
我辞职后第2天被他们hr叫去帮忙做网站。(挠头)














 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









