






Elasticsearch概述
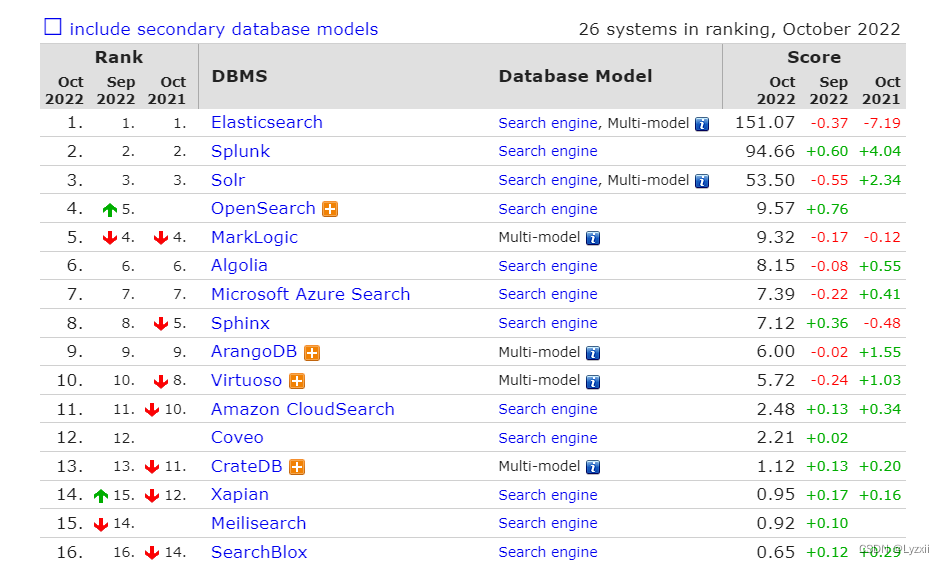
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,其在 DB-Engines “兵器”排行榜中长期位列第一
DB-Engines Ranking - popularity ranking of search engines
除了搜索领域外,Elasticsearch 与 Kibana、Logstash 组成的 ELK 系统还可以应用到日志采集、分析、监控等领域。其中:
- Logstash (或 Beats)是免费且开放的服务器端数据处理管道,能从多个来源采集数据,转换数据,并将数据存储在 Elasticsearch 中。
- Kibana 用于数据展示。
- Elaticsearch是整个 ElasticStack 技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。除了搜索领域外。
Elasticsearch优点
-
Elasticsearch 能够以多种搜索方式执行及合并多种类型的搜索(结构化数据、非结构化数据、地理位置、指标)
-
高扩展性,能够水平扩展,每秒钟可处理海量事件,同时能够自动管理索引和查询在集群中的分布方式,以实现极其流畅的操作。
-
访问数据速度极快。
-
安全性和可靠性。Elasticsearch 可以为你检测到硬件、网络分区等故障,并确保你的集群和数据的安全性和可用性。通过跨集群复制功能,辅助集群可以作为热备份随时投入使用。
-
全文搜索引擎,Google、百度等搜索网站,都是根据网页中的关键字生成索引,然后将该关键字即索引匹配到的所有网页返回
结构化数据和非结构化数据
结构化数据:包括字段名和字段对应的值,类似key-value的数据结构,一般可以存在数据库。
非结构化数据:比如文档,视频等
Elasticsearch的安装
docker安装ES
docker pull elasticsearch:7.6.2
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms84m -Xmx512m" \
-v /usr/es_docker/config/elasticsearch.yml:/usr/es/config/elasticsearch.yml \
-v /usr/es_docker/data:/usr/es/data \
-v /usr/es_docker/plugins:/usr/es/plugins \
-d elasticsearch:7.6.2注意: 9300 端口为 Elasticsearch 集群间组件的通信端口, 9200 端口为浏览器访问的 http协议 RESTful 端口。
安装成功后,在浏览器中访问 localhost:9211,以下结果即运行成功:
{
"name" : "5467cb121d7b",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "siDO7_8DTb6s5N6-OE1t0A",
"version" : {
"number" : "7.6.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}docker安装kibana
Kibana 是官方的数据分析和可视化平台,可以当作 ES 查询的调试工具, Kibana 与 ES 的版本是有对应关系的,需要使用相同版本;
docker pull kibana:7.6.2
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://localhost:9200 -p 5601:5601 -d kibana:7.6.2
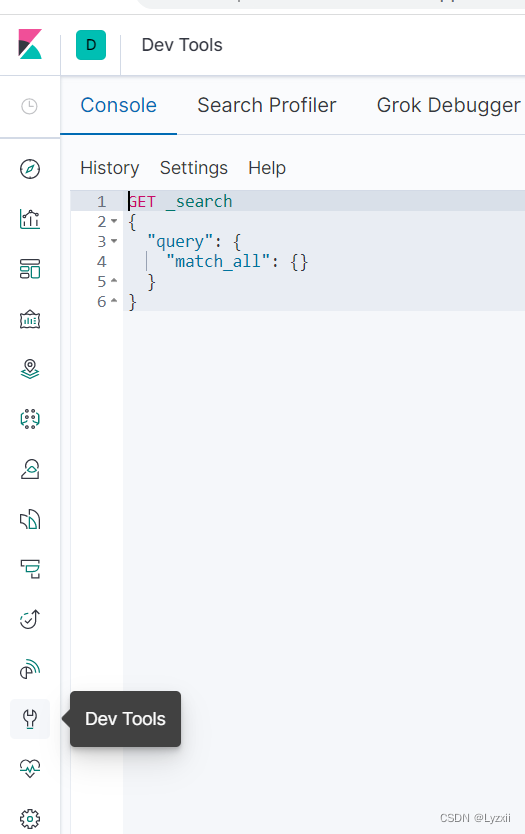
安装成功后,通过浏览器访问:localhost:5601/app/kibana#/dev_tools/console, 通过Dev Tool可以操作ESKibana
Elasticsearch中的基本概念
Elasticsearch服务概念
集群 Cluster
多个协同工作的 ES 实例(节点Node)组合成的集合称为集群,分布式的 ES 集群可以存储海量的数据,也可以从容地面对更高的并发量。高可用,可扩展。
节点 Node
单个 ES 的服务实例叫做节点,本质上就是一个 Java 进程。每个实例都有自己的名字,通过配置里的 'node.name' 设置的内容。为了标识每个节点,每个节点启动后都会分配一个 UID,存储在 data 目录。各个节点受到集群的管理,我们可以通过增加或者减少节点来达到扩容或减容的目的。
节点分类:集群里的节点是有分类的,主要的节点类型如下。
-
主节点(Master):主节点在整个集群是唯一的,Master 从有资格进行选举的节点(Master Eligible)中选举出来。主节点主要负责管理集群变更、元数据的更改。
-
数据节点(Data Node):其负责保存数据,扩充存储时候需要扩展这类节点。数据节点还负责执行数据相关的操作,如:搜索、聚合、CURD 等。所以对节点机器的 CPU、内存、I/O 要求都比较高。
-
协调节点(Coordinating Node):负责接受客户端的请求,将请求路由到对应的节点进行处理,并且把最终结果汇总到一起返回给客户端。因为需要处理结果集和对其进行排序,需要较高的 CPU 和内存资源。
-
预处理节点(Ingest Node)。预处理操作允许在写入文档前通过定义好的一些 processors(处理器)和管道对数据进行转换。默认情况下节点启动后就是预处理节点。
-
Hot & Warm Node:不同硬件配置的 Data Node,用来实现 Hot & Warm 架构的节点,有利于降低集群部署成本。例如,在硬件资源好的机器中部署 Hot 类型的数据节点,而在硬件资源一般的机器上部署 Warm Node 节点。
在生产环境中建议将每个节点设置为单一角色。如果业务量或者并发量不大的情况下,为了节省成本可以调整为一个节点多种角色的集群。
节点角色的配置:
7.8 及之前版本各个节点类型的配置方式如下:
| 节点类型 | 配置 | 默认值 |
|---|---|---|
| Master Eligible | node.master | true |
| Data Node | node.data | true |
| Ingest Node | node.ingest | true |
| Coordinating Node | 不需要配置 | 默认就是coordinating,所以需要设置单一角色时,设置其他类型全部为false |
在新版的 ES 中,使用 node.roles 参数来指定一个节点的角色。其示例如下:
node.roles: [ master, data ] //设置节点为 master 候选节点和数据节点node.roles 的值是一个数组,说明一个节点可以有多个角色。node.roles 的可选项如下:
-
master:master 候选节点,master 将会从这些节点中选取出来。
-
voting_only:参与 master 选举的节点,其只有投票权限,当不会成为 master。
-
data:我们最熟悉的一类数据节点。保存文档数据的 shard 将分配到 data 节点中保存。
-
data_content:此角色的节点会处理用户创建的文档内容,如书本信息,歌曲信息这类数据。可以处理 CRUD、数据搜索和聚合等。
-
data_hot:此角色的节点会根据数据写入 ES 的时间存储时序数据,例如日志数据,data_hot 节点对数据读写要求快速,应当使用 SSD 存储。
-
data_warm:data_warm 节点会存储不会经常更新但是仍然被查询的数据,相对于 data_hot,其查询的频率要低。
-
data_cold:很少再被读取的数据可以存储在 data_cold,此类节点的数据是只读的。
-
data_frozen:专门用于存储 partially mounted indices 的数据节点。
-
inges:预处理数据的节点。
-
ml:提供机器学习的功能,此类节点运行作业并处理机器学习 API 请求。
-
remote_cluster_client:充当跨集群客户端并连接到其他集群。
-
transform:运行 transforms 并处理 transform API 请求。
注意:每个节点本身就是一个协调节点,无需设置。
分片 Shard
分片即是将一个大的数据集 Data 按照某些策略分为 几个部分,然后存储到不同个节点上面(一个节点一个分片),分片(Shard)是 ES 底层基本的读写单元,分片是为了分割巨大的索引数据,让读写可以由多台机器来完成,从而提高系统的吞吐量。
副本 Replica
为了保证数据可靠性,一般分布式系统都会对数据进行冗余备份,这个备份也就是副本了。ES将数据副本分为主从两类型:主分片(primary shard)和副分片(replica shard) 。在写入的过程中,先写主分片,成功后并发写副分片,在数据恢复时以主分片为主。多个副本除了可以保证数据可靠性外,还有一个好处是可以承担系统的读负载。
注:分片和副本的概念类似kafka中的分区和副本,作用都是相同的。
集群健康状态
通过集群的健康状态,了解集群是不是出现问题了。 集群健康状态有以下 3 种。
-
Green,集群处于健康状态,所有的主分片和副本分片都正常运行。
-
Yellow,所有的主分片都运行正常,但是有部分副本分片不正常,意味着可能存在单点故障的风险(如果部分主分片没有备份了,一旦这个主分片数据丢失,将导致这些数据永久丢失)。如果集群只有 3 个数据节点,但是分配了 4 个副本(主分片 + 副本分片的总数),这个时候有一个副本无法分配的,因为相同的两份数据不应该被分配到同一个节点上。
-
Red,有部分主分片没有正常运行。
需要注意的是,每个索引也有这三种状态,如果索引丢失了一个副本分片,那么这个索引和集群的状态都变为 Yellow 状态,但是其他索引的的状态仍为 Green。
Elasticsearch数据概念
Elasticsearch与MySQL比较
Elasticsearch 是面向文档型数据库,一条数据就是一个文档。 为了方便理解,将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比
| ElasticSearch | Index(索引) | Type(类型) | Document(文档) | Fields(字段) |
| MySQL | Database(数据库) | Table(表) | Row(行) | Column(列) |
ES 里的 Index 可以看做一个库,而 Types 相当于表, Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一个 index 下已经只能包含一个type, Elasticsearch 7.X 中, Type 的概念已经被删除了。
索引 Index
索引是一类相似文档的集合。ES 将数据存储在一个或者多个 Index 中,如将用户数据存储在 User Index 中,将订单数据存储在 Order Index 中。一个索引有一个或者多个分片,索引的数据会以某种方式分散到各个分片上去存储。
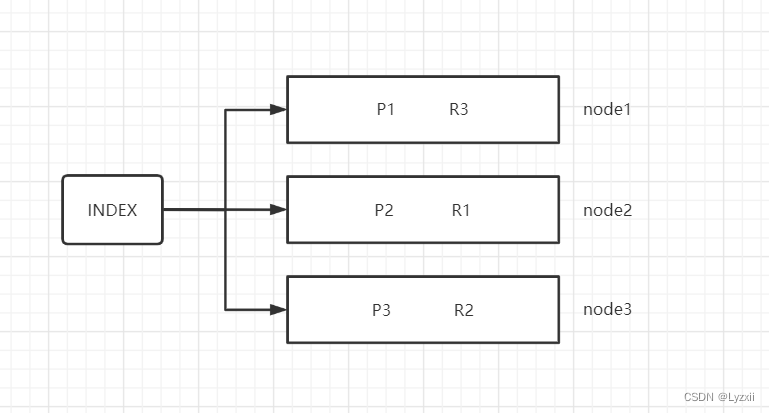 如上图,索引有 3 个分片,主分片分别是 P1、P2、P3,对应的副本分片为 R1、R2、R3,分别位于 3 个节点中。主分片和其副本分片不会同时分配在同一个节点上。这样是为了保证当一个节点上的主分片下线时,其他节点上的从副本可以升级为主分片,保证数据的可靠性。
如上图,索引有 3 个分片,主分片分别是 P1、P2、P3,对应的副本分片为 R1、R2、R3,分别位于 3 个节点中。主分片和其副本分片不会同时分配在同一个节点上。这样是为了保证当一个节点上的主分片下线时,其他节点上的从副本可以升级为主分片,保证数据的可靠性。
映射Mapping
Mapping 定义了索引里的文档到底有哪些字段及这些字段的类型,类似于数据库中表结构的定义。Mapping 有两种作用:
- 定义了索引中各个字段的名称和对应的类型;
- 定义各个字段、倒排索引的相关设置,如使用什么分词器等。
Mapping 一旦定义后,已经定义的字段的类型是不能更改的
文档 Doc
向 ES 中写入的每一条数据都是一个文档(类似数据库中的一条记录),并且我们搜索也是以文档为单位的,所以文档是 ES 中的主要实体
字段 Field
每个文档都有一个或者多个字段,每个字段都有指定的类型,常见的有:keyword、text、数字类型(integer、long、float、double等)、对象类型等。
- keyword 类型适合存储简短、结构化的字符串,例如产品 ID、产品名字等。
- text 类型的字段适合存储全文本数据,如短信内容、邮件内容等。
- 对象类型简单来说就是字段的值还是一个 json 对象。
词项 Term
将全文本的内容进行分词后得到的词语就是词项了。例如 "Programmers Love Cat" 使用标准分词器分词后得到 [programmer, love, cat] 这 3 个词项,需要注意的是:分词器除了进行分词外还会进行大小写转换等其他操作。
倒排索引
索引从本质来讲就是一种为了加快检索数据的存储结构,如下图保存了实体 ID 到实体数据关联关系的key-value数据结构,这种实体 ID 到数据实体内容的关联关系的索引我们称为正排索引。正排索引非常适合处理键值查询的场景,一般实现正排索引的数据结构主要有三种:哈希表、有序数组和 B+ 树。熟知的 MySQL InnoDB 的索引就是正排索引,使用的是 B+ 树来实现。
| id | content |
| 1001 | my name is zhangsan |
| 1002 | my name is lisi |
倒排索引
在需要找出内容中包含给定词语的诗词,这个就没有办法使用正排索引来处理了,分词后保存词项到文档实体 ID 关系的索引称为倒排索引,如下图:
| keyword | id |
| name | 1001,1002 |
| zhangsan | 1001 |
| lisi | 1002 |
系统层面概念
近实时系统
ES 是一个近实时系统,我们写入的数据默认的情况下会在 1 秒后才能被查询到。ES 每秒都会把缓存中的数据写入到 Segment 文件中(写入到 Segment 中才能被检索),然后根据某些规则进行刷盘,并且合并这些 Segment。所以需要注意的是,不能在写入数据成功后,立刻进行查询,这个时候可能会出现查询不到数据或者获取到旧数据的情况。
Lucene 与 ES 的关系
Lucene 是一个用于全文检索的开源项目,ES 在搜索的底层实现上用的就是 Lucene。你可以简单认为,ES 就是在 Lucene 上增加了分布式特性的系统服务。
Lucene 也有索引,那 Lucene 的索引和 ES 的索引是个怎么样的关系呢?其实 ES 上的分片(Shard)就是一个完整的 Lucene 索引。
相关性评分
对于一个搜索引擎来说,对检索出来的数据进行排序是非常重要的功能。全文本数据的检索通常无法用是否相等来得出结果,而是用相关性来决定最后的返回结果。而相关性的指标为相关性评分。
至于相关性评分是如何计算的,这里不展开,我们后续的内容会有非常详细的介绍,这里我们简单举个例子来说明。
例如下面两句话就非常相似:“红色的猫喜欢吃苹果”(这是检索的内容)、“红色的猫猫非常喜欢吃大苹果”(这个是库里的内容,被检索的内容)。 它们相似的原因是因为它们都有 “红色”、“猫”、“苹果” 这 3 个有效词。如果要转化为数学模型的话,简单来说,相关性可以由句子中有效的词语在句子中出现的频率来表示。当然有效的算法比这个复杂很多,要考虑的因素也非常多
索引管理
索引的增删改查
索引的增删改查主要有以下3中方式去实现
- Restful格式的Http请求直接访问ES去操作索引
- 使用Java API去操作ES
- 使用kibana去操作ES
创建索引:
PUT 请求 : http://127.0.0.1:9200/books
kibana创建:索引中记录书本的 ID、名字、作者、简介。定义如下 Mapping,并且创建索引
PUT books
{
"mappings": {
"properties": {
"book_id": {
"type": "keyword"
},
"name": {
"type": "text"
},
"author": {
"type": "keyword"
},
"intro": {
"type": "text"
}
}
},
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}创建索引成功
{
"acknowledged": true,//响应结果
"shards_acknowledged": true,//分片结果
"index": "books"//索引名称
}
创建 books 索引成功,books 索引包含 book_id(书本 ID)、name(书本名字)、author(作者)、intro(简介)四个字段, books 索引还有 3 个分片和 1 个副本备份。
查看索引
查看单个索引
GET 请求 : http://127.0.0.1:9200/books
kibana查询单个索引:GET books
查询结果:
{
"books" : {
"aliases" : { },
"mappings" : {
"properties" : {
"author" : {
"type" : "keyword"
},
"book_id" : {
"type" : "keyword"
},
"intro" : {
"type" : "text"
},
"name" : {
"type" : "text"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1660641408504",
"number_of_shards" : "3",
"number_of_replicas" : "1",
"uuid" : "FchVEcuCS76Qvp_Dv7m-LQ",
"version" : {
"created" : "7060299"
},
"provided_name" : "books"
}
}
}
}查看所有索引
GET 请求 : http://127.0.0.1:9200/_cat/indices?v;
kibana查询所有索引:GET _cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open books FchVEcuCS76Qvp_Dv7m-LQ 3 1 0 0 849b 849b
yellow open .kibana J34h0WqvQvSBcB9tfB_o0A 1 1 23 3 75.1kb 75.1kb其中:具体含义如下:
- health :当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常)
- status :索引打开、关闭状态
- index: 索引名
- uuid: 索引统一编号
- pri :主分片数量
- rep: 副本数量
- docs.count: 可用文档数量
- docs.deleted: 文档删除状态(逻辑删除)
- store.size :主分片和副分片整体占空间大小
- pri.store.size:主分片占空间大小
删除索引
DELETE 请求 : http://127.0.0.1:9200/books;
kibana查询所有索引:DELETE books
{
"acknowledged": true
}
文档管理
有了索引后就可以在索引中创建文档,操作文档,文档的操作方法和索引一样,通过Http请求、Java API或者Kibana都是可以的,省略其他方法,主要以Kibana为参考,底层都是向ES发起Http请求。
创建文档
使用 Index API 索引文档
PUT books/_doc/1
{
"book_id": "4ee82462",
"name": "深入Linux内核",
"author": "toms hulus",
"intro": "内容全面深入,领略linux内核的无限风光。"
}创建成功:
{
"_index" : "books",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}将 Mapping 中对应的字段做成 Json Object 对应的 Key 即可,并且上面的例子中我们指定文档 ID 为 1。需要说明的是,在 ES 7.0 版本后 type 统一为 _doc。
当索引的文档已经存在,在不改变文档 ID 的情况下多次执行上面的索引文档的语句,并不会报错,而是将返回结果中 "_version" 字段的值自加。因为在索引一个文档的时候,如果文档 ID 已经存在,会先删除旧文档,然后再写入新文档的内容,并且增加文档版本号。
使用 Create API 创建文档
使用 Create API 创建文档有两种写法:PUT 和 POST 方式,其示例分别如下:
# 使用 PUT 的方式创建文档
PUT books/_create/2
{
"book_id": "4ee82463",
"name": "时间简史",
"author": "Stephen William Hawking",
"intro": "探索时间和空间核心秘密的引人入胜的故事。"
}
# PUT 方式返回的结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "2",
"_version" : 1
......
}
# 使用 POST 的方式,不需要指定文档 ID, 系统自动生成
POST books/_doc
{
"book_id": "4ee82464",
"name": "时间简史(插画版)",
"author": "Stephen William Hawking",
"intro": "用精美的插画带你探索时间和空间的核心秘密"
}
# POST 方式返回的结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "LfwVtH0BxOuNtEd4yM4F",
"_version" : 1
......
}总结:使用 PUT 的方式创建文档需要指定文档的 ID,如果文档 ID 已经存在,则返回 http 状态码为 409 的错误。而使用 POST 的方式创建文档时候,则不需要指定文档 ID,系统会自动创建,在返回结果中可以看到,新创建的文档的 ID 为 'LfwVtH0BxOuNtEd4yM4F'。
| 序号 | 语句 | 特性描述 |
|---|---|---|
| 1 | PUT books/_doc/1 | 使用 Index API 索引文档,如果文档存在,会先删除然后再写入,即有覆盖原内容的功能。 |
| 2 | PUT books/_create/2 | Create API 中使用 PUT 的方式创建文档,需要指定文档 ID。如果文档已经存在,则返回 http 409 错误。 |
| 3 | POST books/_doc | Create API 中使用 POST 的方式,不需要指定文档 ID, 系统自动生成。 |
- 如果有更新文档内容的需求,应该使用第一种方式。
- 如果写入文档时有唯一性校验需求的话,应该使用第二种方式。
- 如果需要系统为你创建文档 ID,应该使用第三种方式。相对于第一种方式来说,第三种方式写入的效率会更高,因为不需要在库里查询文档是否已经存在,并且进行后续的删除工作。
查询文档
使用 ES 提供的 GET API 来获取文档内容。获取文档有 2 种情况,一种是只获取一个文档内容,另一种是同时获取多个文档的内容。
使用 GET API 获取单个文档
通过书本的 ID 获取书本使用 GET API 来实现,其示例如下:
GET books/_doc/1结果如下:
{
"_index" : "books",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"book_id" : "4ee82462",
"name" : "深入Linux内核",
"author" : "yanpeidong",
"intro" : "内容全面深入,领略linux内核的无限风光。"
}
}文档的原生内容保存在 "_source" 字段中,其他字段是这个文档的元数据。成功返回的http 状态码为 200,如果文档不存在则 http 状态码为 404,并且 found 字段为 false。
GET API 提供了多个参数,比较常用的:
| 参数 | 简介 |
|---|---|
| preference | 默认的情况下,GET API 会从多个副本中随机挑选一个,设置 preference 参数可以控制 GET 请求被路由到哪个分片上执行。 |
| realtime | 控制 GET 请求是实时的还是准实时的,默认为 true。 |
| refresh | 是否在执行 GET 操作前执行 refresh(后续我们有介绍),默认为 false。 |
| routing | 自定义 routing key。 |
| stored_fields | 返回在 Mapping 中 store 设置为 true 的字段,而不是 _source。默认为 false。 |
| _source | 指定是否返回 _source 的字段,或者设置某些需要返回的字段。 |
| _source_excludes | 不返回哪些字段,逗号分割的字符串列表。如果 _source 设置为 false,此参数会被忽略。 |
| _source_includes | 返回哪些字段,逗号分割的字符串列表。如果 _source 设置为 false,此参数会被忽略。 |
| version | 指定版本号,如果获取的文档的版本号与指定的不一样,返回 http 409。 |
使用 MGET API 获取多个文档
使用 ES 提供的 MGET API 可以一次获取多个文档数据,请求格式有 3 种,其示例如下:
# 1:在 body 中指定 index
GET /_mget
{
"docs": [
{ "_index": "books", "_id": "1" },
{ "_index": "books", "_id": "2" }
]
}
# 2:直接指定 index
GET /books/_doc/_mget
{
"docs": [
{ "_id": "1" },
{ "_id": "2" }
]
}
# 3:也可以简写为一下例子
GET /books/_mget
{
"ids" : ["1", "2"]
}
执行结果:
{
"docs" : [
{
"_index" : "books",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"book_id" : "4ee82462",
"name" : "深入Linux内核",
"author" : "yanpeidong",
"intro" : "内容全面深入,领略linux内核的无限风光。"
}
},
{
"_index" : "books",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"book_id" : "4ee82463",
"name" : "时间简史",
"author" : "Stephen William Hawking",
"intro" : "探索时间和空间核心秘密的引人入胜的故事。"
}
}
]
}更新文档
ES 提供了 Update API 来更新文档信息,使用如下:
# 更新文档
POST books/_update/2
{
"doc": {
"name":"时间简史(视频版)",
"intro": "探索时间和空间核心秘密的引人入胜的视频故事。"
}
}
执行结果:版本号会增加,"result" 字段为 updated。
{
"_index" : "books",
"_type" : "_doc",
"_id" : "2",
"_version" : 3,
"result" : "updated",
......
}
索引文档的方式也有更新数据的效果,但是索引文档的方式会覆盖旧的数据,使其无法实现只更新某些字段的需求。
删除文档
ES 提供了 Delete API 来删除一个文档,只需要指定索引和文档 ID 即可,Delete API 使用如下:
# 删除文档 2
DELETE books/_doc/2
执行结果:
{
"_index" : "books",
"_type" : "_doc",
"_id" : "2",
"_version" : 4,
"result" : "deleted",
......
}
如果文档存在则删除成功,"result" 字段为 "deleted"。如果文档本身不存在,则返回 http 的状态码为 404。
除了指定文档 ID 进行文档删除外,我们还可以使用 Delete By Query API 进行查询删除。
# 使用 Delete By Query API 删除文档
POST /books/_delete_by_query
{
"query": {
"term": {
"book_id": "4ee82462"
}
}
}
批量操作文档
可以使用 Bulk API 来批量处理文档,Bulk API 支持在一次调用中操作不同的索引,使用时可以在 Body 中指定索引也可以在 URI 中指定索引。而且还可以同时支持 4 中类型的操作:
- Index
- Create
- Update
- Delete
Bulk API 的格式是用换行符分隔 JSON 的结构,第一行指定操作类型和元数据(索引、文档id等),紧接着的一行是这个操作的内容(文档数据,如果有的话。像简单的删除就没有。),其格式如下:
POST _bulk
# 第一行指定操作类型和元数据(索引、文档id等)
{ "index" : { "_index" : "books", "_id" : "1" } }
# 紧接着的一行是这个操作的内容(文档数据,如果有的话。像简单的删除就没有)
{ "book_id": "4ee82462","name": "深入Linux内核架构", ......}
下面示例是在 Bulk API 中同时使用多种操作类型的例子:
# 在 Bulk API 中同时使用多种操作类型的实例
POST _bulk
{ "index" : { "_index" : "books", "_id" : "1" } }
{ "book_id": "4ee82462","name": "深入Linux内核架构","author": "Wolfgang Mauerer","intro": "内容全面深入,领略linux内核的无限风光。" }
{ "delete" : { "_index" : "books", "_id" : "2" } }
{ "create" : { "_index" : "books", "_id" : "3" } }
{ "book_id": "4ee82464","name": "深入Linux内核架构第三版","author": "Wolfgang Mauerer","intro": "内容全面深入,再次领略linux内核的无限风光。" }
{ "update" : {"_index" : "books", "_id" : "4"} } # 指定操作类型、索引、文档 id
{ "doc" : {"intro" : "书本的内容非常好,值得一看"} } # 指定文档内容执行结果:
{
"items" : [
{
"index" : {
"_id" : "1",
"result" : "created",
......
}
},
{
"delete" : {
"_id" : "2",
"result" : "deleted",
......
}
},
{
"create" : {
"_id" : "3",
"result" : "created",
......
}
},
{
"update" : {
"_id" : "4",
"status" : 404,
......
}
}
]
}因为一个请求中有多个操作,所以返回结果中会对每个操作有相应的执行结果。如果其中一条操作失败,是不会影响其他操作的执行。
















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









