






1.greenplum数据库创建分布键
greenplum数据库定义分布键有两种方式,一种是建表时定义,另一种是用alter修改分布键
如果不在建表时定义分布键或修改分布键,默认为表第一个字段。
1、建表分布键跟存储类型一起设定
2、修改test表分布键:
alter table test set distributed by (id)
2.设定存储类型
数据库存储类型分为行存储row和列存储column
greenplum数据库如果不设定存储类型,默认heap表,只有行存储,
如果设定存储类型,就会设置为AO表,包括行存储和列存储,
在建表时定义存储类型和分布键:
CREATE TABLE "public"."student" (
"name" varchar(255) COLLATE "pg_catalog"."default" DEFAULT NULL,
"age" int4 DEFAULT NULL,
"id" int4 NOT NULL DEFAULT NULL
)
// 设置行存储,id为分布键
WITH (appendonly=true, orientation=row) distributed by (id);
// 设置列存储,id为分布键
WITH (appendonly=true, orientation=column) distributed by (id);
3.快速新增数据
代码如下(示例):
insert into student(id,name,age,create_dt) select generate_series(1,1000),'name',12,'2021-02-20';
4.创建分区表
1、
// 创建子表继承student
CREATE TABLE student_2021_02_20 () inherits (student);
// 增加表校验字段,create_dt = ‘2021-02-20’
ALTER TABLE student_2021_02_20
ADD CONSTRAINT almart_2021_02_20_check_date_key
CHECK (create_dt = '2021_02_20'::date);
CREATE INDEX almart_date_key_2021_02_20
ON student_2021_02_20 (create_dt);
2、
// 追加分区表
alter table public.student add partition p_order_detail_adt_20170601 START ('2017-05-01') END ('2017-06-01')
// 删除分区表
alter table public.student DROP partition p_order_detail_adt_20170601;
drop table tablename cascade;
3、创建表时创建分区表
CREATE TABLE "public"."student" (
"create_dt" date DEFAULT NULL,
"id" int4 NOT NULL DEFAULT NULL
)
WITH (APPENDONLY=true, COMPRESSLEVEL=1, ORIENTATION=column, COMPRESSTYPE=rle_type)
DISTRIBUTED by(id)
partition by range (create_dt)
(
partition "2021_" start ('2021-02-01') end ('2021-02-11') every (1),
default partition def
)
DROP TABLE IF EXISTS "public"."order_pickup_time";
CREATE TABLE "public"."order_pickup_time" (
"id" int8 DEFAULT NULL,
"order_id" int8 DEFAULT NULL,
"start_pickup_time" timestamp(6) DEFAULT NULL
)
distributed by (id)
partition by range(start_pickup_time)
(
partition "2021_" start ('2020-02-01') end ('2020-02-28') every (INTERVAL '1 day'),
default partition def
)
;
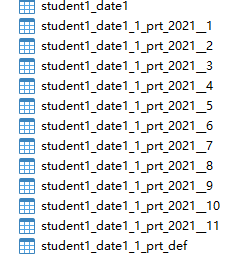
4、多级分区
create table "public"."student"
(
id int,
province varchar(64),
city varchar(64),
district varchar(64),
fdate date DEFAULT NULL
)
distributed by (id)
// fdate是一级分区,province是二级分区
partition by range(fdate)
subpartition by list(province)
subpartition template
(
subpartition c1 values ('黑龙江'),
subpartition c2 values ('辽宁')
)
(
partition "2021_" start ('2021-02-01') end ('2021-02-11') every (1),
default partition def
)
4.分页查询
代码如下(示例):
// 查询1~1000条数据
SELECT FROM student ORDER BY name LIMIT 1000 OFFSET 0
4.时间函数
代码如下(示例):
select date '2012-05-12 18:54:54'; 2012-05-12
select date (now() + interval '-1 month'); 2021-03-05 -> 2021-02-05
select to_char(now(), 'yyyy-mm-dd')
5.copy表结构
代码如下(示例):
// 复制表结构,但是不能复制非空,主键和分布键
// 复制student表结构和数据
CREATE TABLE student_copy as SELECT * from student;
// 复制student表结构
CREATE TABLE student_copy as SELECT * from student WHERE 0 = 1;
// 只复制表结构(默认复制非空约束),没有数据
CREATE TABLE student_copy (like student);
// 如果希望索引、主键约束和唯一约束被复制的话,那么需要在后面加上参数including indexes(大小写无关)
CREATE TABLE student_copy (like student including indexes);
6.id自增
代码如下(示例):
CREATE SEQUENCE order_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
alter table order alter column id set default nextval('order_id_seq');
7.设置search_path
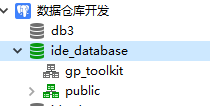
这个结构schema是ide_database,默认的查找路径是模块public,
如果你想新建一个模块ide_test,默认jdbc连接使用ide_test,就需要设置search_path
代码如下(示例):
1)连接greenplum
C:\Windows\system32>psql -h 1.2.345.678 -p 5432 -d tpc_1 -U gpuser
2)查看search_path
tpc_1# show search_path;
"$user".public
3)修改search_path
tpc_1=# alter database tpc_1 set search_path to "$user", ide_test;
8.删除无用表空间
全数据库(很慢)
VACUUM ANALYZE;
分表执行
VACUUM ANALYZE table1;
查询库占用磁盘大小
select pg_size_pretty(pg_database_size('MyDatabase'));
查询表占用磁盘大小
普通表
select pg_size_pretty(pg_relation_size('relation_name')) ;
查看所有表占用的表空间
SELECT
table_schema || '.' || table_name AS table_full_name,
pg_size_pretty(pg_total_relation_size('"' || table_schema || '"."' || table_name || '"')) AS size
FROM information_schema.tables
ORDER BY
pg_total_relation_size('"' || table_schema || '"."' || table_name || '"') DESC;
9.greenplum invalid byte sequence for encoding “UTF8”: 0x00
// 将字段进行替换
REPLACE(create_branch_name,'\0','') create_branch_name
10.优化
//关闭优化器
gpconfig -c optimizer -v off
// 查看关联优化器
gpconfig --show enable_mergejoin
// 打开优化器
gpconfig -c enable_mergejoin -v on
// 查看全部参数
psql -c 'show all' -d postgres
11.gpfdist数据导入
目标:将mysql数据导入到greenplum数据库
1、mysql数据导出csv文件,将文件上传到服务器/home/gpadmin/datafile/test.csv
2、gp服务器启动gpfdist
$ gpfdist -d /home/gpadmin/datafile/ -p 8001 &
3、设置gpfdist大小
gpfdist -d /home/gpadmin/datafile/ -m 268435456 -p 8001 &
4、创建外部表关联到csv文件
create external table test(id int,name VARCHAR(30),age int)location(‘gpfdist://192.168.1.234:8001/drugs.csv’)format’CSV’;
5、导入数据
insert into gp_test select * from test;
删除外部表
drop external table test;
12.创建数据库
1、列举数据库,相当于mysql的show databases
\l
列举表,相当于mysql的show tables
\dt
查看表结构,相当于desc tblname,show columns from tbname
\d tblname
gp常用语句
https://blog.csdn.net/u010457406/article/details/75647167
2、create database devdw; 创建数据库
3、导出ddl语句
pg_dump -E UTF8 -s -v ide_warn_test -n public>ide_warn_test.ddl -
4、导入ddl语句
nohup psql -d “ide_warm” -f /home/gpadmin/ddl/ide_warn_test.ddl >ide_warm.log &
13.重启数据库
1、重新加载配置
gpstop -u
2、启动gp
gpstart
3、停止gp
gpstop
4、重启gp
gpstop -r















 1007
1007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









