







 本文继续深入介绍Python字符串的常用方法,如str.index用于查找子串并处理找不到时的错误,str.isalnum解释了如何判断字符串是否全由字母或数字组成,str.isalpha说明了字母字符的范围,str.join用于合并字符串,str.ljust用于左对齐填充,str.lower用于转换为小写,以及str.lstrip用于去除前导字符。此外,还提到了新特性str.removeprefix用于移除前缀。通过这些方法,能更高效地操作和处理字符串。
本文继续深入介绍Python字符串的常用方法,如str.index用于查找子串并处理找不到时的错误,str.isalnum解释了如何判断字符串是否全由字母或数字组成,str.isalpha说明了字母字符的范围,str.join用于合并字符串,str.ljust用于左对齐填充,str.lower用于转换为小写,以及str.lstrip用于去除前导字符。此外,还提到了新特性str.removeprefix用于移除前缀。通过这些方法,能更高效地操作和处理字符串。
字符串方法介绍二
上篇我们介绍了一些字符串的方法,没有看的可以点击下方链接
今天我们继续来介绍剩余的一些方法
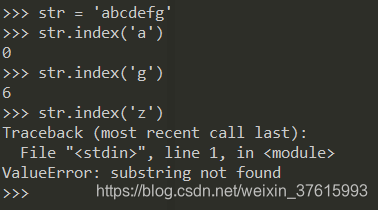
str.index(sub[, start[, end]])
这个方法类似于 find(),但在找不到子类时会引发 ValueError
start,end可以默认不写
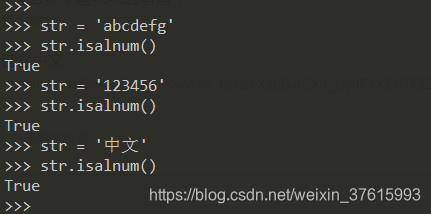
str.isalnum()
看下官网的描述:
如果字符串中的所有字符都是字母或数字且至少有一个字符,则返回 True , 否则返回 False 。 如果 c.isalpha() , c.isdecimal() , c.isdigit() ,或 c.isnumeric() 之中有一个返回 True ,则字符c是字母或数字
我们可以看到中文的字符串返回的也是True,这个地方可以参考下方的 isalpha()方法
str.isalpha()
如果字符串中的所有字符都是字母,并且至少有一个字符,返回 True ,否则返回 False 。字母字符是指那些在 Unicode 字符数据库中定义为 “Letter” 的字符,即那些具有 “Lm”、“Lt”、“Lu”、“Ll” 或 “Lo” 之一的通用类别属性的字符。 注意,这与 Unicode 标准中定义的"字母"属性不同
str = '中文'
str.isalpha()
结果:True
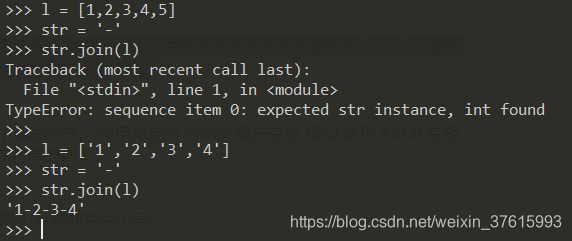
str.join(iterable)
返回一个由 iterable 中的字符串拼接而成的字符串。 如果 iterable 中存在任何非字符串值包括 bytes 对象则会引发 TypeError。 调用该方法的字符串将作为元素之间的分隔。
str.ljust(width[, fillchar])
返回长度为 width 的字符串,原字符串在其中靠左对齐。 使用指定的 fillchar 填充空位 (默认使用 ASCII 空格符)。 如果 width 小于等于 len(s) 则返回原字符串的副本
str = 'abc'
str,ljust(10,'*')
结果:'abc*******'
str.lower()
返回原字符串的副本,其所有区分大小写的字符均转换为小写
str = 'AbCdEfG'
str.lower()
结果:abcdefg
str.lstrip([chars])
返回原字符串的副本,移除其中的前导字符。 chars 参数为指定要移除字符的字符串。 如果省略或为 None,则 chars 参数默认移除空格符。 实际上 chars 参数并非指定单个前缀;而是会移除参数值的所有组合:
' spacious '.lstrip()
结果:'spacious '
'www.example.com'.lstrip('cmowz.')
结果:'example.com'
str.removeprefix(prefix, /)
如果字符串以 前缀 字符串开头,返回 string[len(prefix):] 。否则,返回原始字符串的副本:
'TestHook'.removeprefix('Test')
结果:‘Hook’
'BaseTestCase'.removeprefix('Test')
结果:‘'BaseTestCase'’
注:此为3.9新功能
大家如果看博客感觉不是很方便的可以关注一下我的公众号,我会同步的推送文章。同时,也希望和大家多多交流学习


















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









