







一.建表.(分区、分桶)
1.建普通表
a.语句
CREATE% table dtjd.atest (
userid int,sex string
)
row FORMAT DELIMITED fields TERMINATED BY '\001' STORED AS TEXTFILE
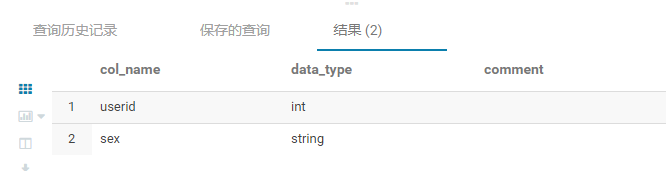
b. desc 查看表结构
2.建分区表
a.语句
CREATE% table dtjd.atestuser (
userid int,sex string
)
PARTITIONED% BY (username string) //指定分区
row FORMAT DELIMITED fields TERMINATED BY '\001' //指定字段分隔符
STORED AS TEXTFILE //指定存储类型为文件
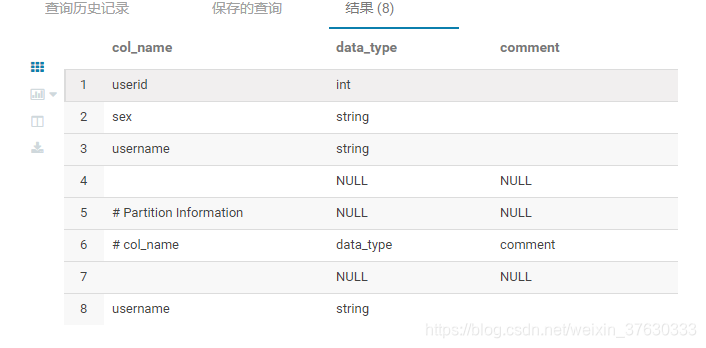
b.desc 查看表结构
c.知识点
①分区通过关键字partitioned by (username string)表示该表为分区表,并通过username分区
②分区字段的值不宜过多,底层会将同一个值存放在一个表文件
③如果某分区字段值太多,需这个参数
set hive.exec.max.dynamic.partitions.pernode=10000;
2.建分桶表
桶是对指定列进行哈希计算实现,hive使用对分桶所用的字段值进行hash,并用hash结果除以桶的个数取余计算的方式来分桶,保证了每个桶中都有数据,但每个桶中的数据量不一定相等。
a.语句
CREATE% table dtjd.atestuser (
userid int,sex string
) PARTITIONED BY (username string)
CLUSTERED BY (userid) SORTED BY (userid ASC) INTO 50 BUCKETS //分50桶
row FORMAT DELIMITED fields TERMINATED BY '\001' STORED AS TEXTFILE
3.分区分桶区别
a.分桶是通过指定列进行哈希计算,随机分割数据库,比较平均;
b.分区是按照字段值分割,容易造成数据倾斜;
c.在数据量够大的情况下,分桶比分区有更高的查询效率,分区数量过大时,则建议分桶处理.
4.sql
运行参数:
- set mapreduce.map.memory.mb=3072;
- set mapreduce.reduce.memory.mb=3072;
a. hive不支持group_concat(column)
- 用concat_ws(’,’, collect_set(column))替代
b.拼接
- concat(‘字段1’,‘哈哈’,‘cc’) 结果:字段1哈哈cc
concat:有一个参数为NULL,结果为null(默认【没有分隔符】)
concat_ws:有一个参数为NULL,则跳过该参数(指定【第一个参数】为分隔符)
c.regexp_extract
regexp_extract('pname:小张@Number:123456789','.*Number:(.*)',1) 结果:123456789
regexp_extract('pname:小张@Number:123456789','(.*)Number:.*',1) 结果:pname:小张@
d.if判断
- if(name is null, ‘’, name) 如果name为null,则name为空字符串
e.case判断
- 如果province字段为‘SD’ 则输出 ‘山东省’…
case province
when 'SD' then '山东省'
when 'NMG' then '内蒙古'
when 'HAN' then '海南省'
else '其他'
end as province
f.替换:regexp_replace
单引号替换双引号
regexp_replace(pname,'\'','\"')
替换掉[] 括号
regexp_replace(pname,'\\[|\\]','')
g.解析json:get_json_object
例子: json_str=
{
"name":"小张",
"age":15,
"aihao":{
"eat":[{"fruit":"苹果"},{"meat":"beef"}],
"sport":"篮球"
}
}
单层: get_json_object(json_str, '$.name')
结果:小张
多层: get_json_object(json_str, '$.aihao.sport')
结果:篮球
数组: get_json_object(json_str, '$.aihao.eat[0]')
h.转换
避免科学计数法:cast(regcap as bigint)
时间戳转换:from_unixtime(cast(sortTime/1000 as int),'yyyy-MM-dd') sortTime
i.gourp by having 后面不支持 count(distinct 字段)
-- 可以运行
insert into table dtjd.result_week
select Q,5 as score from dtjd.listlogs_new3
where inputdate>'20210531'
group by q,qtime
having count(AUTHCODE)>=3
-- hive不支持 (impala可以运行)
insert into table dtjd.result_week
select Q,5 as score from dtjd.listlogs_new3
where inputdate>'20210531'
group by q,qtime
having count(DISTINCT AUTHCODE)>=3
【解决办法:再嵌套一层】
select a.Q,5 as score from
(
select q,qtime,authcode from dtjd.listlogs_new3
where inputdate>'20210531' group by q,qtime,authcode
) a
group by a.q,a.qtime having count(a.AUTHCODE)>=3
g. hive不支持 not in 子查询
不可运行
INSERT into table dtjd.RESULT_P SELECT a.Q,a.score FROM dtjd.result_halfyear_5 a WHERE a.Q NOT IN( SELECT b.Q FROM dtjd.RESULT_P b );
解决办法(left join)
INSERT into table dtjd.RESULT_P SELECT a.Q,a.score FROM dtjd.result_halfyear_5 a left outer join dtjd.RESULT_P b on a.q=b.q;
h.hive-sql保存到hdfs
insert overwrite directory "/spark-apps/test_case/0625" ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
select rowkey,lanmuId from crv.sx where cast(createTime as bigint)>1624599000000














 520
520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









