







分布式日志—Seq(二)
话接上回哈,这一篇是对上一篇没有讲完整的seq功能的补充介绍。
3. docker容器日志集成Seq
3.1. GELF格式
GELF(Graylog 扩展日志格式)是s一种结构化日志事件格式,用于许多编程语言中的日志记录库。Seq可以通过TCP和UDP接收GELF事件,并支持压缩和分块等常见功能。
seq通过GELF格式接收日志信息需要先安装插件,而且windows部署和docker部署的seq在插件的安装上有所不同,docker部署的seq安装GELF插件需要启动一个 datalust/seq-input-gelf docker实例。
docker run \
--name seq-input-gelf \
-d \ --restart unless-stopped \
-p 12201:12201/udp \
-e SEQ_ADDRESS=http://<seq ip>:5341 \
datalust/seq-input-gelf
3.2. 收集doccker日志
seq可以通过GELF格式收集docker容器产生的日志,任何 Docker 容器的输出都可以通过在启动时配置其日志记录驱动程序来收集:
docker run \
--rm \
-it \
--log-driver gelf \
--log-opt gelf-address=udp://<seq-input-gelf ip>:12201 \
hello-world:latest
这样子启动的情况下,–log-driver gelf 命令设置 Docker 使用 GELF 日志记录驱动程序输出日志,–log-opt gelf-address=udp://localhost:12201 命令设置 Docker 通过 UDP 将日志发送到指定的主机/端口。
可以看到,seq-input-gelf实例启动成功,利用hello-world镜像进行测试的时候,该实例打印的信息也传输到了seq服务端上了。
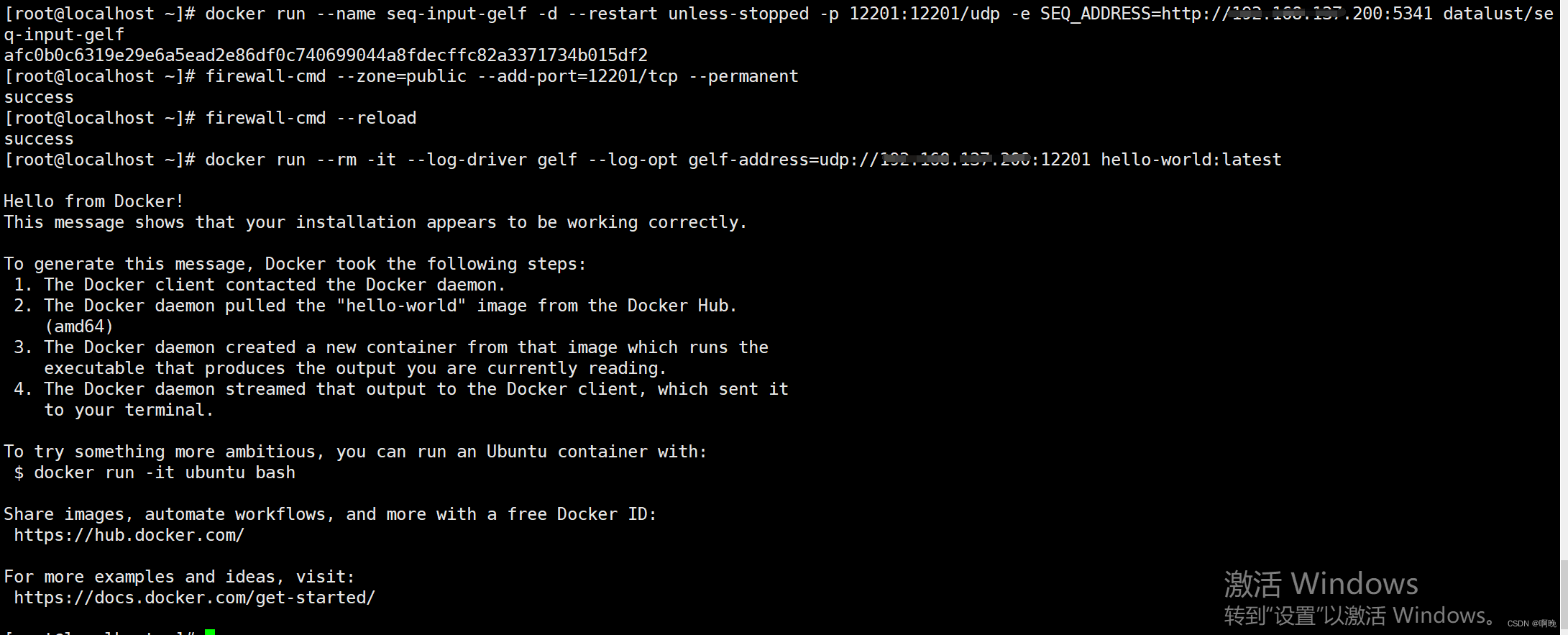
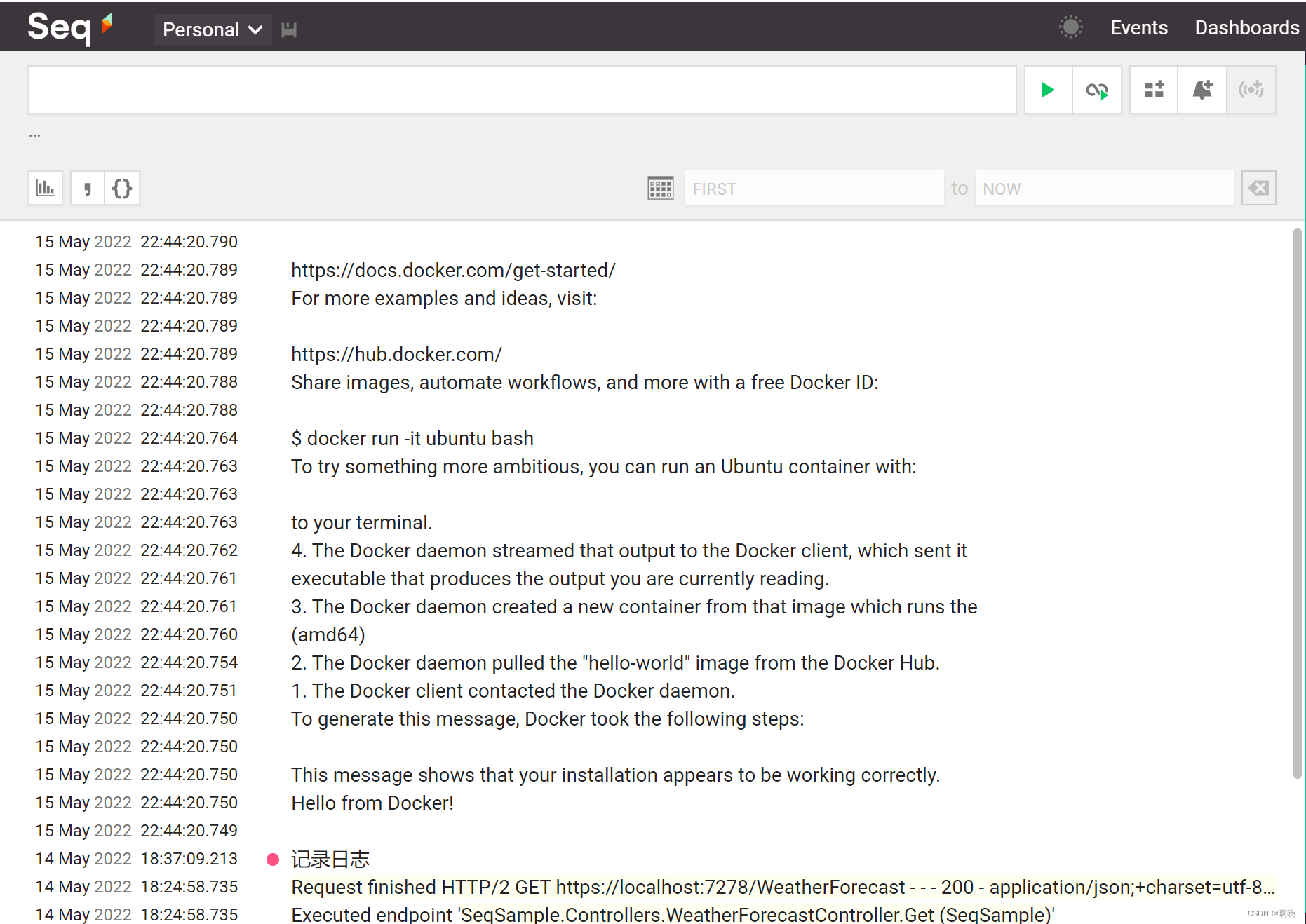
这里需要注意的是,无论是seq-input-gelf实例发送日志的地址,还是需要记录日志的容器配置的日志传输地址,都只能用域名或者ip,不能用localhost,因为这些地址都是在容器内部调用的。
4. 日志分析
Seq日志查询分析的方式这里只介绍一些常用的,更加具体的可以查看官网的文档:Search and Analyze Logs (datalust.co)
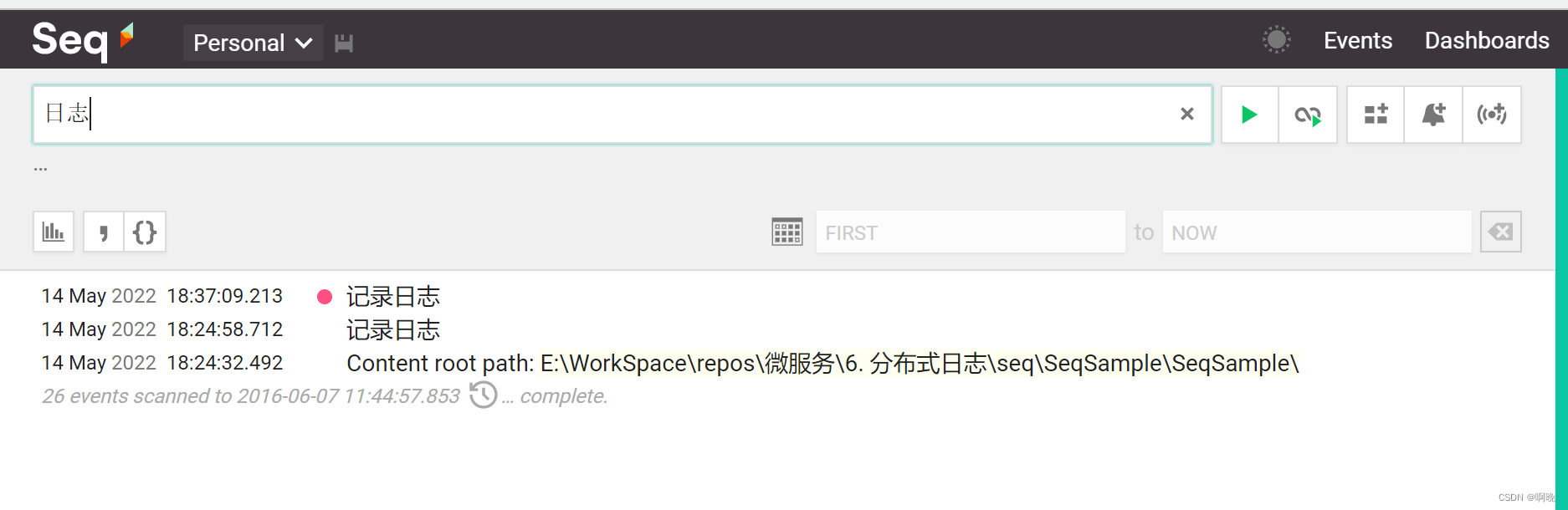
4.1. 普通查询
以模糊查询的方式直接通过错误信息包含的关键字过滤
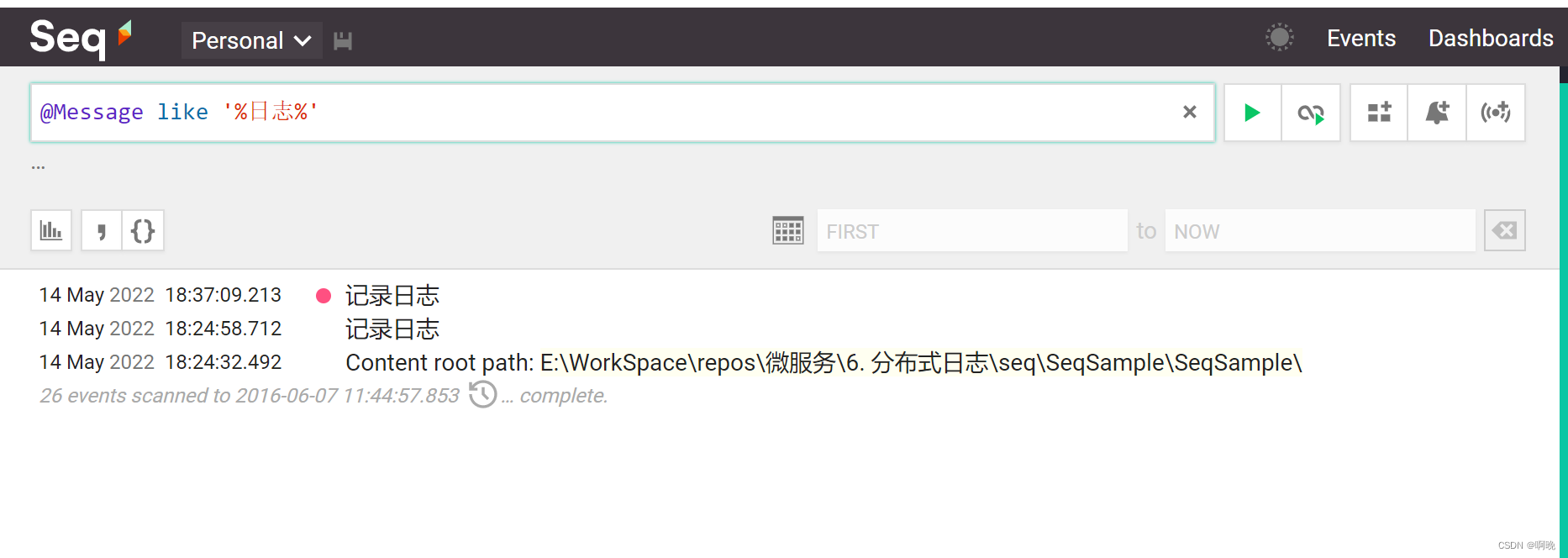
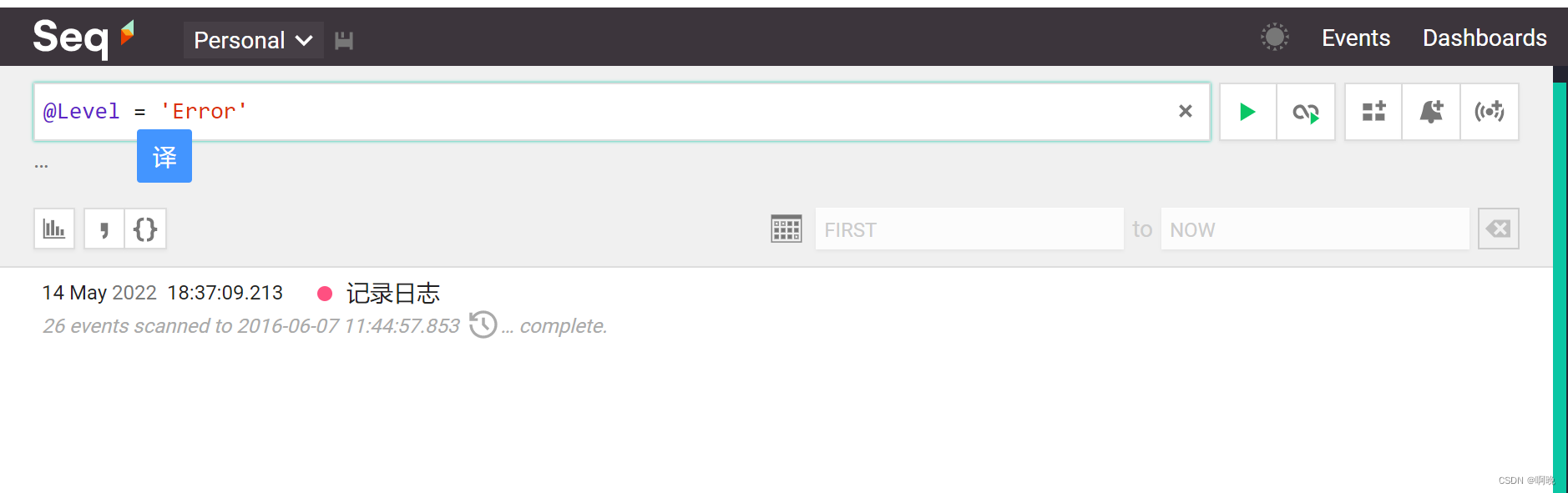
4. 2. @关键字结合运算符过滤
常用的关键字有@Level、@Message、@MessageTemplate、@EventType、@Exception、@Properties
4. 3. 属性过滤
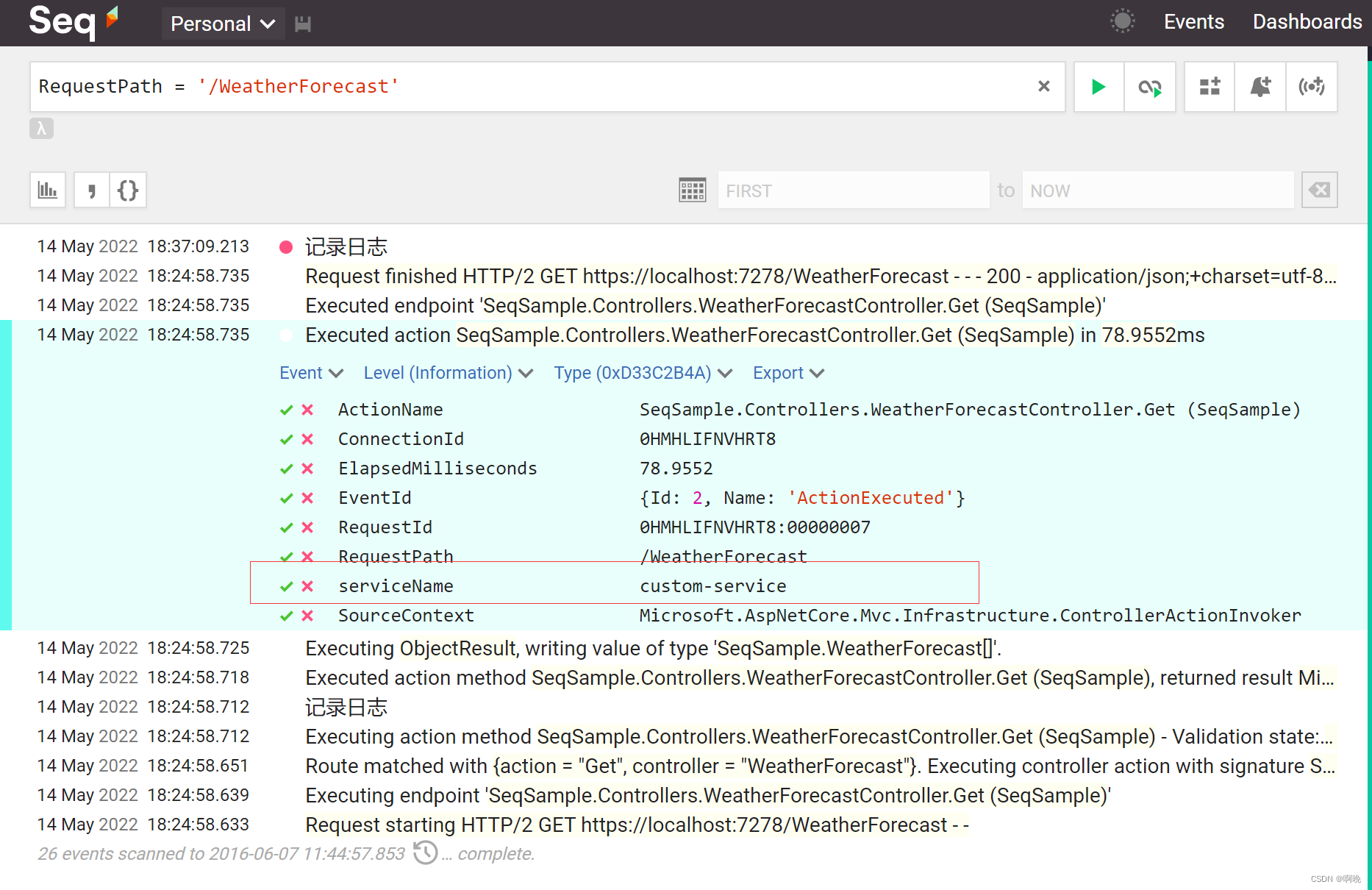
通过日志中包含的属性进行过滤,点开日志可以看到其中的属性,这些属性都可以用来过滤,如通过App Key添加的serviceName属性过滤某个应用的日志
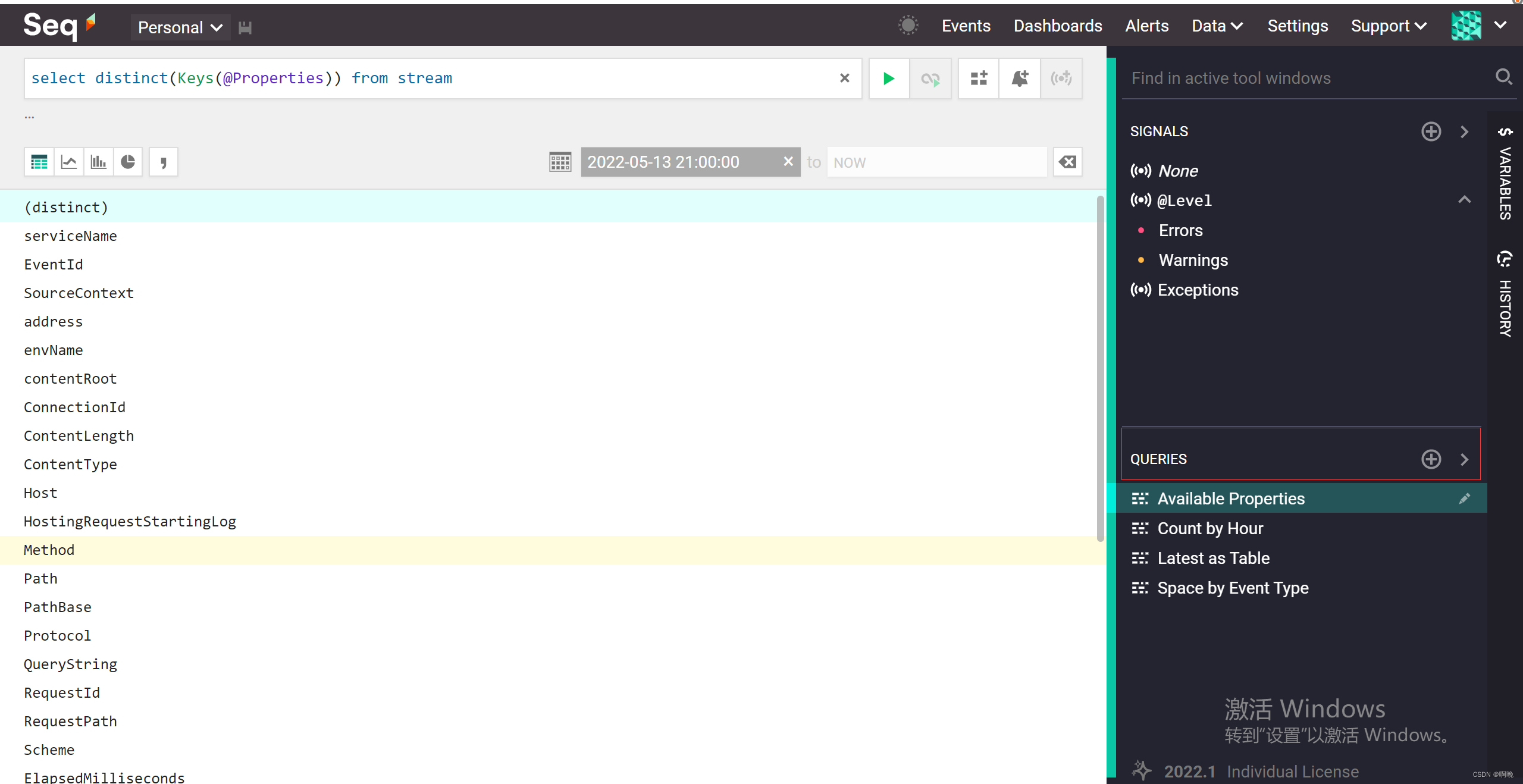
所有可用的属性可以通过右侧的QUERIES中的Available Properties查询。
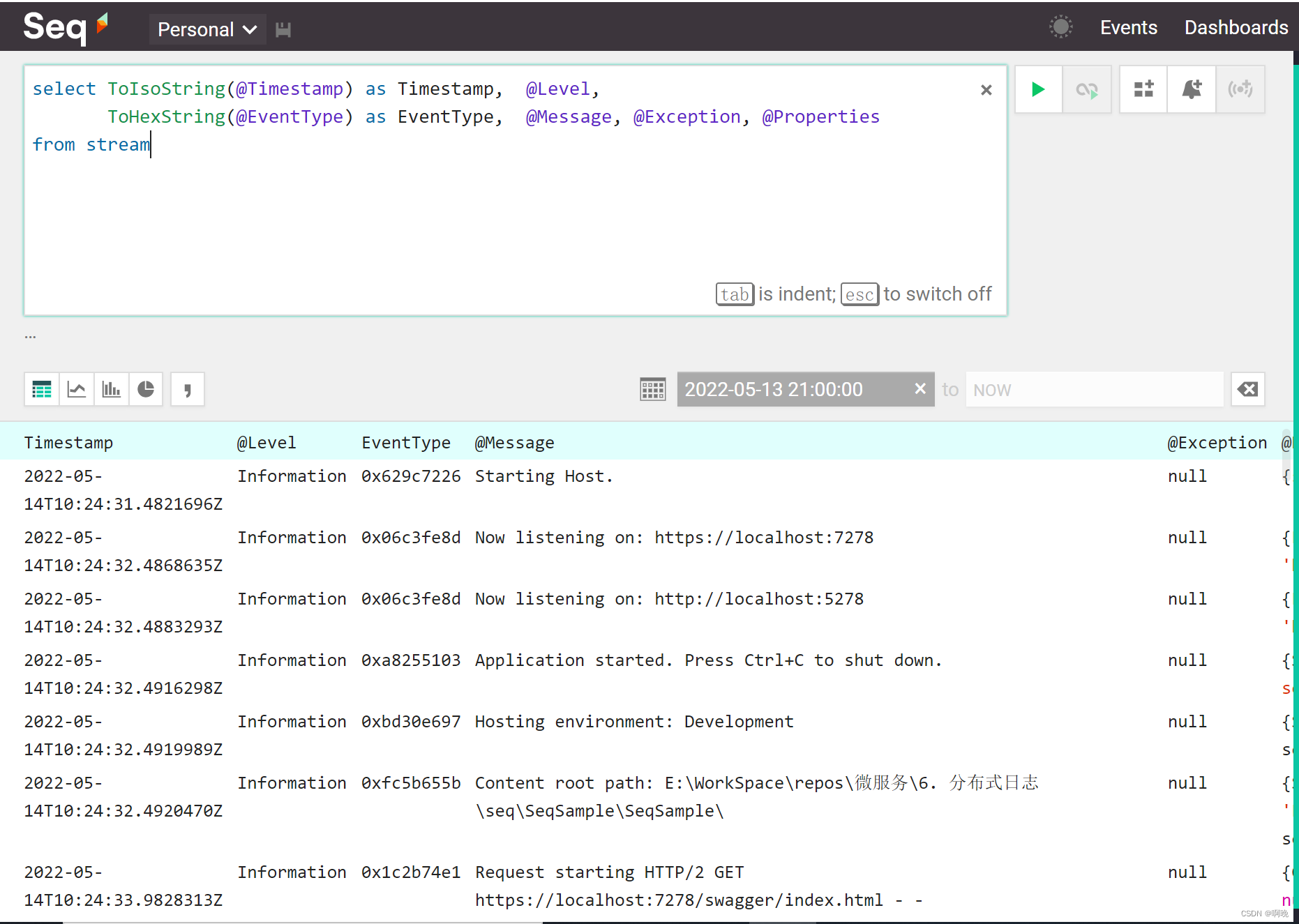
4. 4. sql查询
通过stream像数据库一样通过sql脚本进行查询
聚合:

聚合结果还能切换成图形
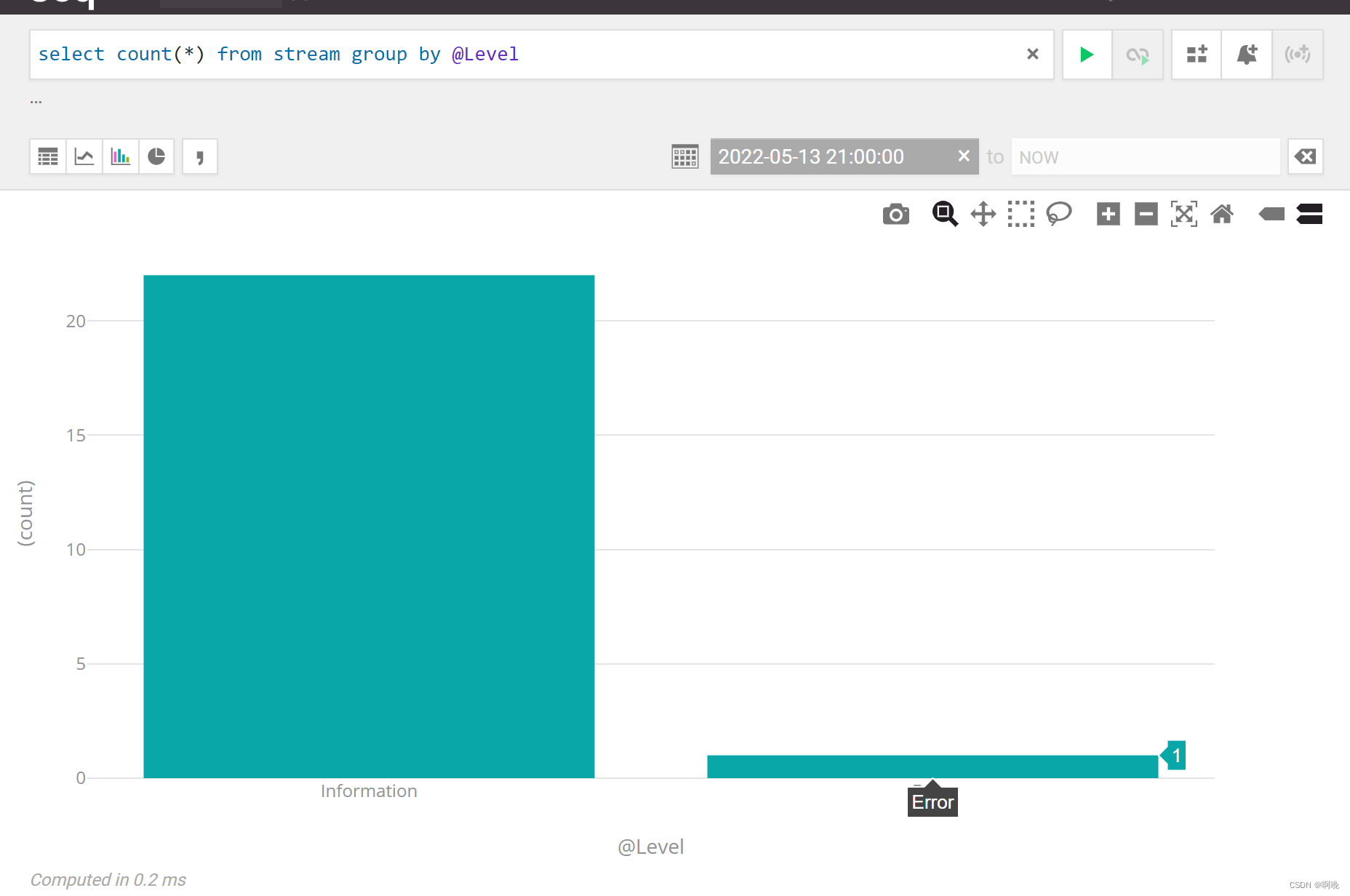
值得一提的是运算符,seq基本支持sql查询中的各种逻辑运算符,包括 =、<>、 >=、<=、like、in、and、or、not等。
此外,还可以通过工作台查看一些日志的统计报表
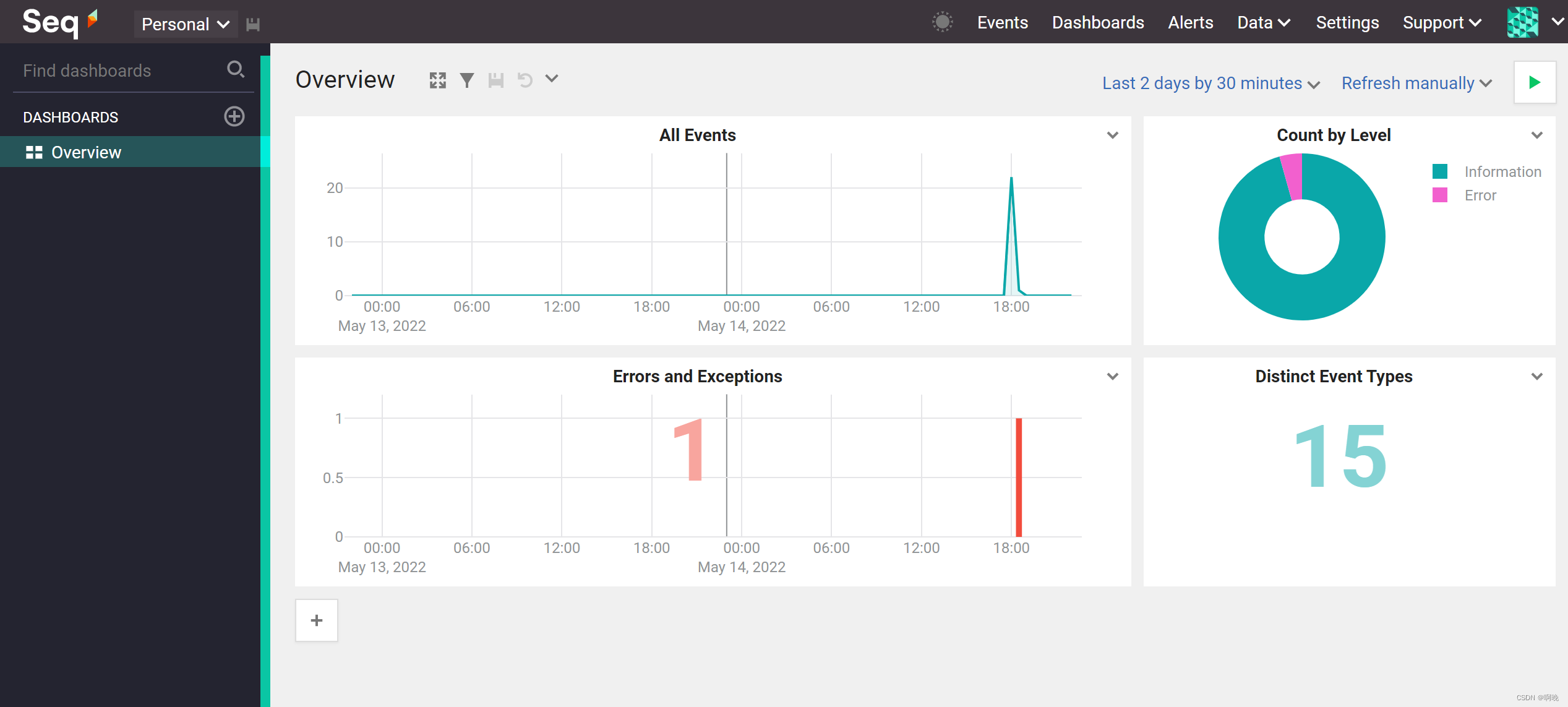
5. 日志管理
我们运行的各个系统、各个服务都会不停的生产日志,不断得完日志收集系统中汇集,如果这些日志一直不删除,将导致日志文件越来越多,不断占用服务器的磁盘空间,直至服务器磁盘爆满。而手动去删除文件太麻烦,所以需要一些自动删除的方式。
5.1 保留策略
Seq提供了保留策略,可以编辑一定的策略,定时根据策略删除相应的日志文件。使用保留策略需要以下几步:
-
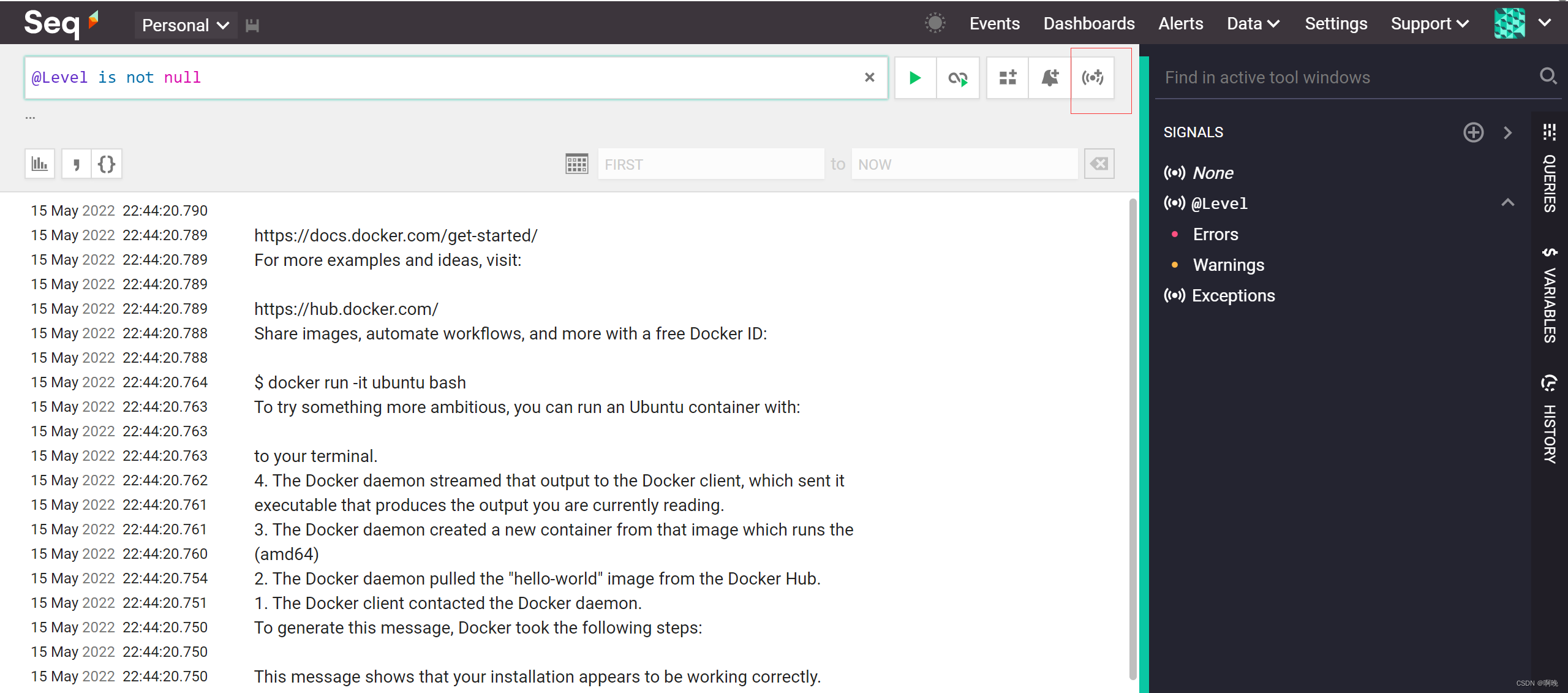
新增信号
所谓信号,其实就是日志筛选器。在日志筛选框输入筛选规则,然后点击筛选框最右边的按钮,即可编辑信号。需要注意,个人信号将无法在保留策略设置屏幕中进行选择,所以创建保留策略需要用到的信号时应该选择 Shared。同时为防止其他用户无意中修改用于保留策略的信号,可以从信号编辑器的下拉菜单中进行选择Protected。
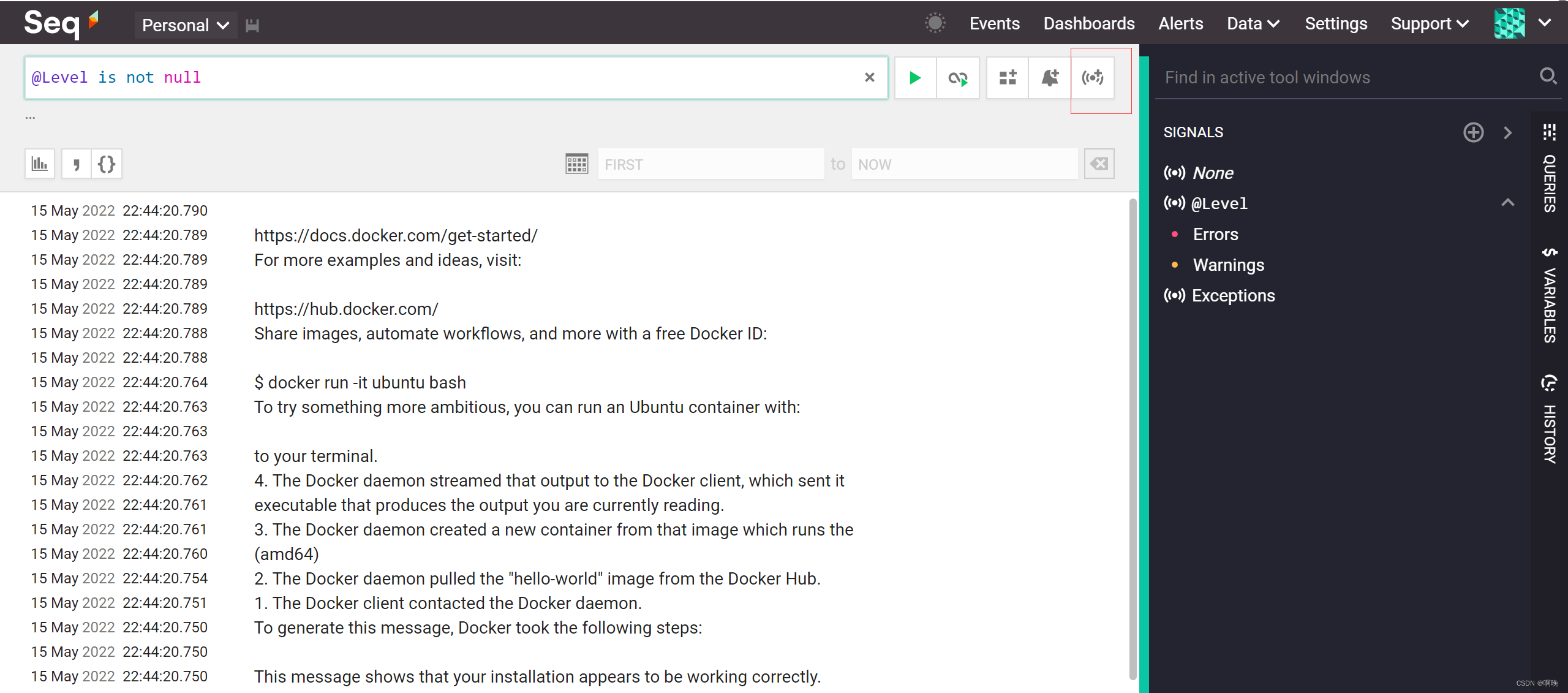
信号创建完成之后,就需要创建保留策略了,点击“setting”,再选择RETENTION菜单,点击“ADD POLICY”按钮。
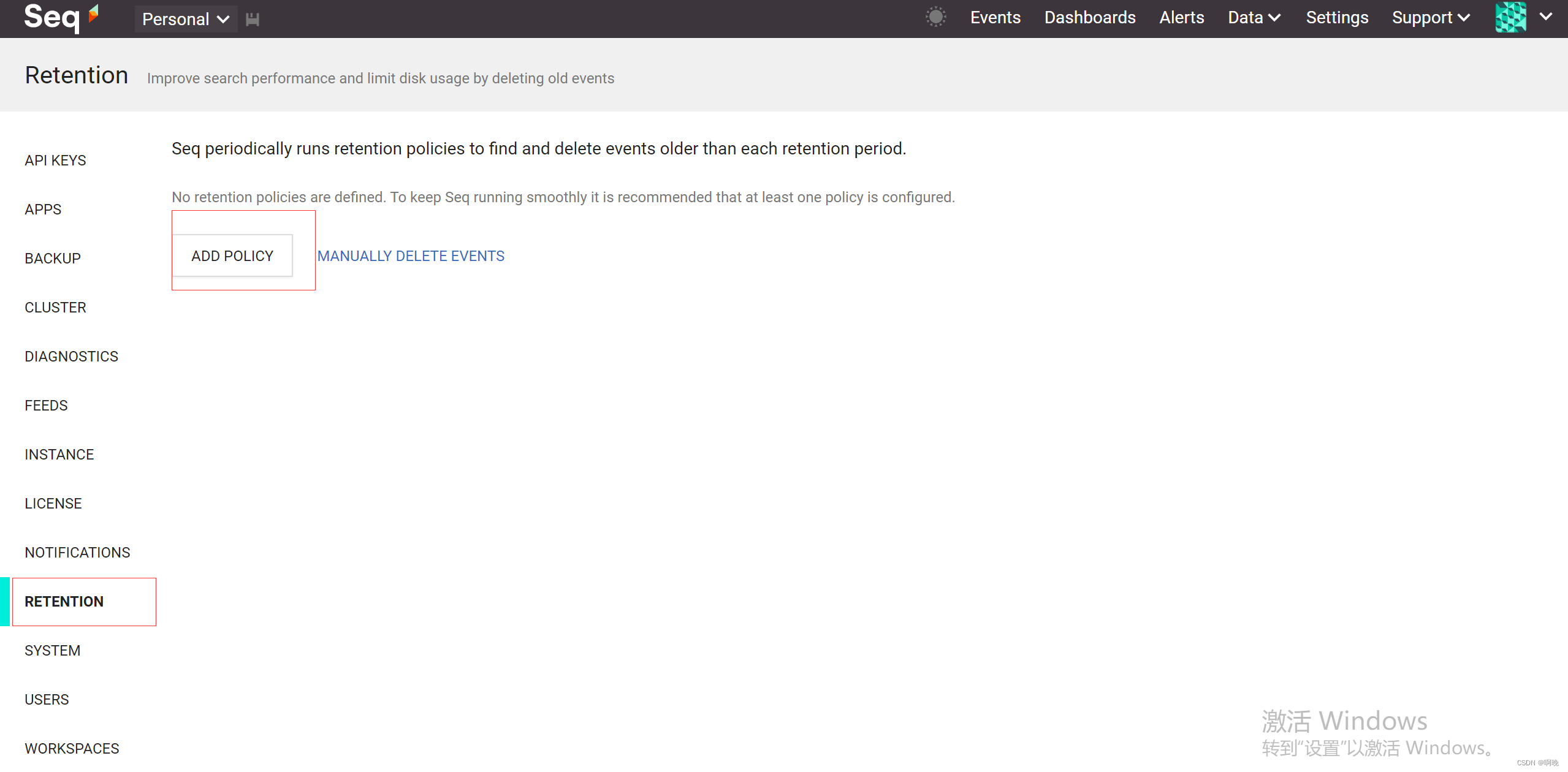
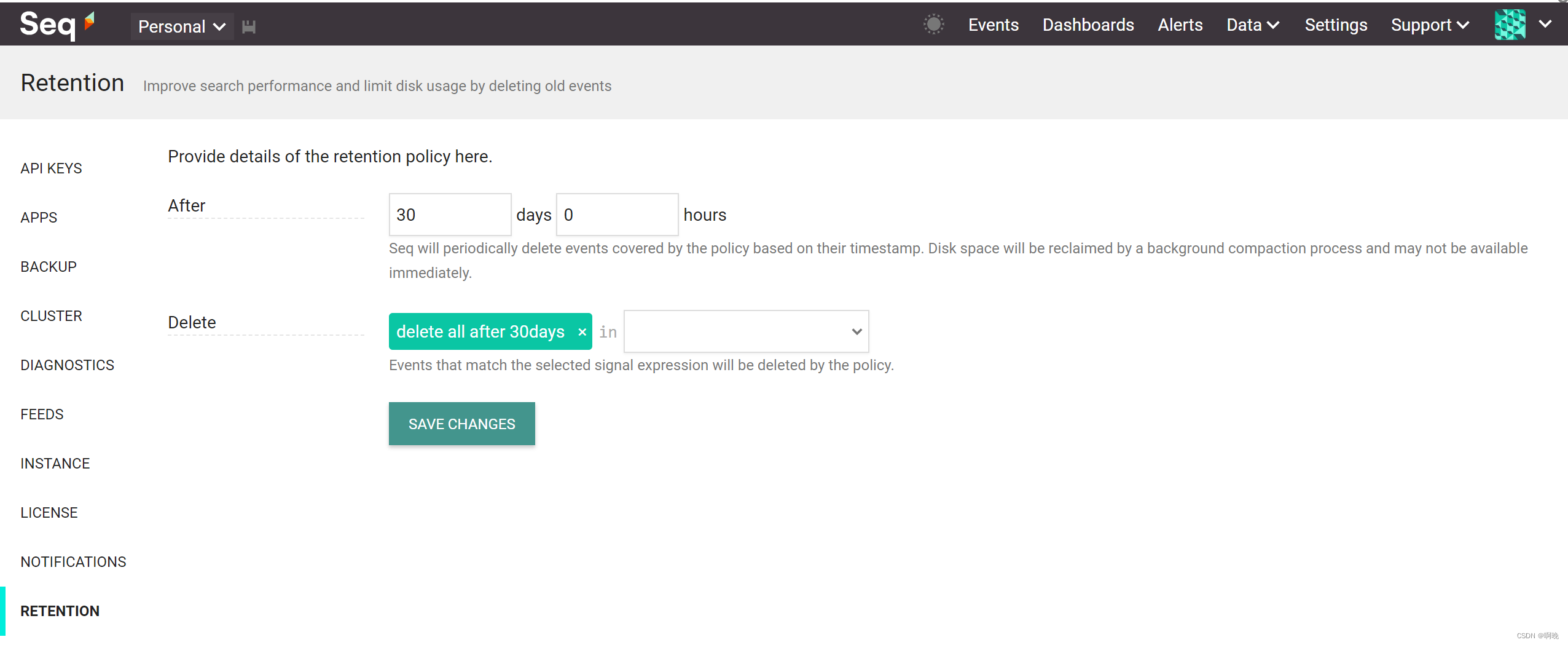
点击保存之后策略生效,不过策略不是立即执行的,所以不能立刻看到效果。 -
手动删除
对于一些情况,我们可能需要立刻删除一些日志,这些需要手动进行操作。通过保留策略页面,点击删除事件按钮,页面会跳转到事件查询页面,不过会多出来两个按钮,我们可以通过输入框筛选要删除的日志,然后点击删除按钮进行删除。
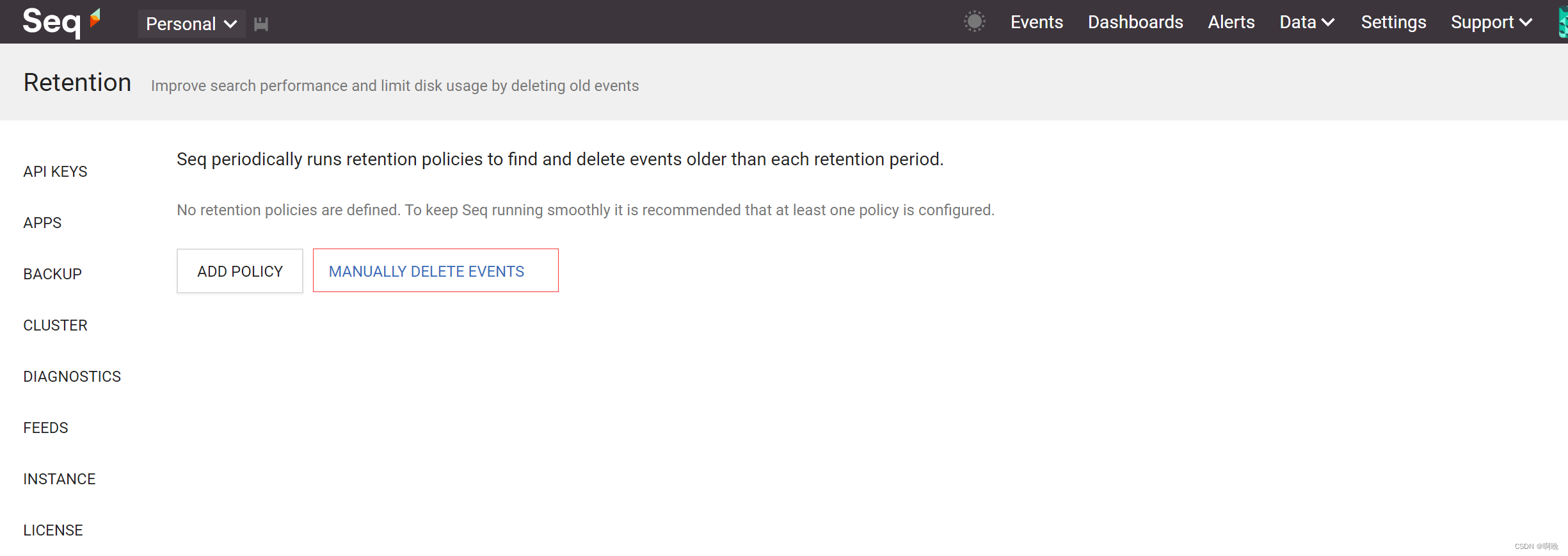
需要注意的是,手动删除会占用大量资源,应避免在系统负载过重时进行手动删除。 -
查看日志存储情况
在“Data > Ingestion”菜单下,可以看到日志写入的情况,看到各个App Key 的情况。
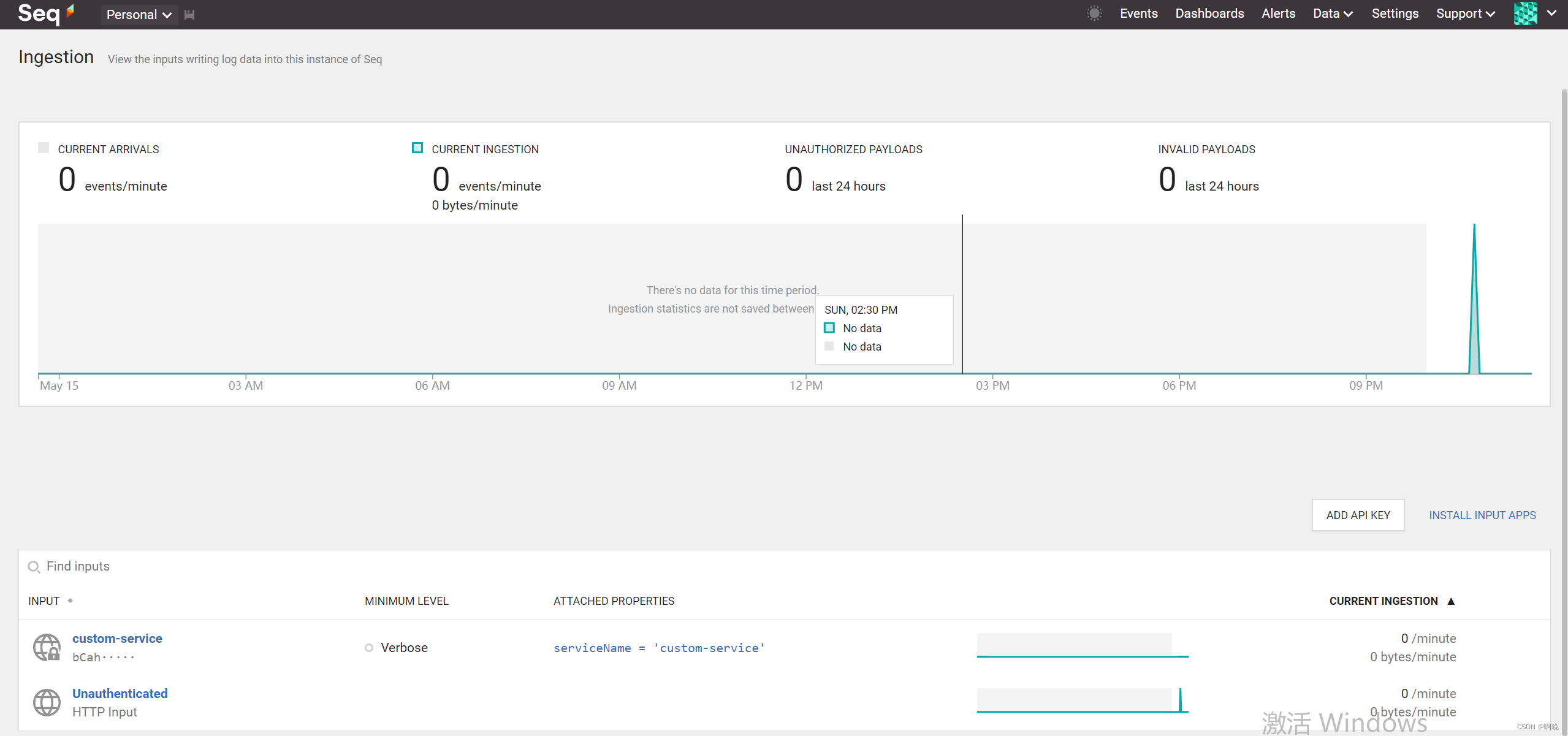
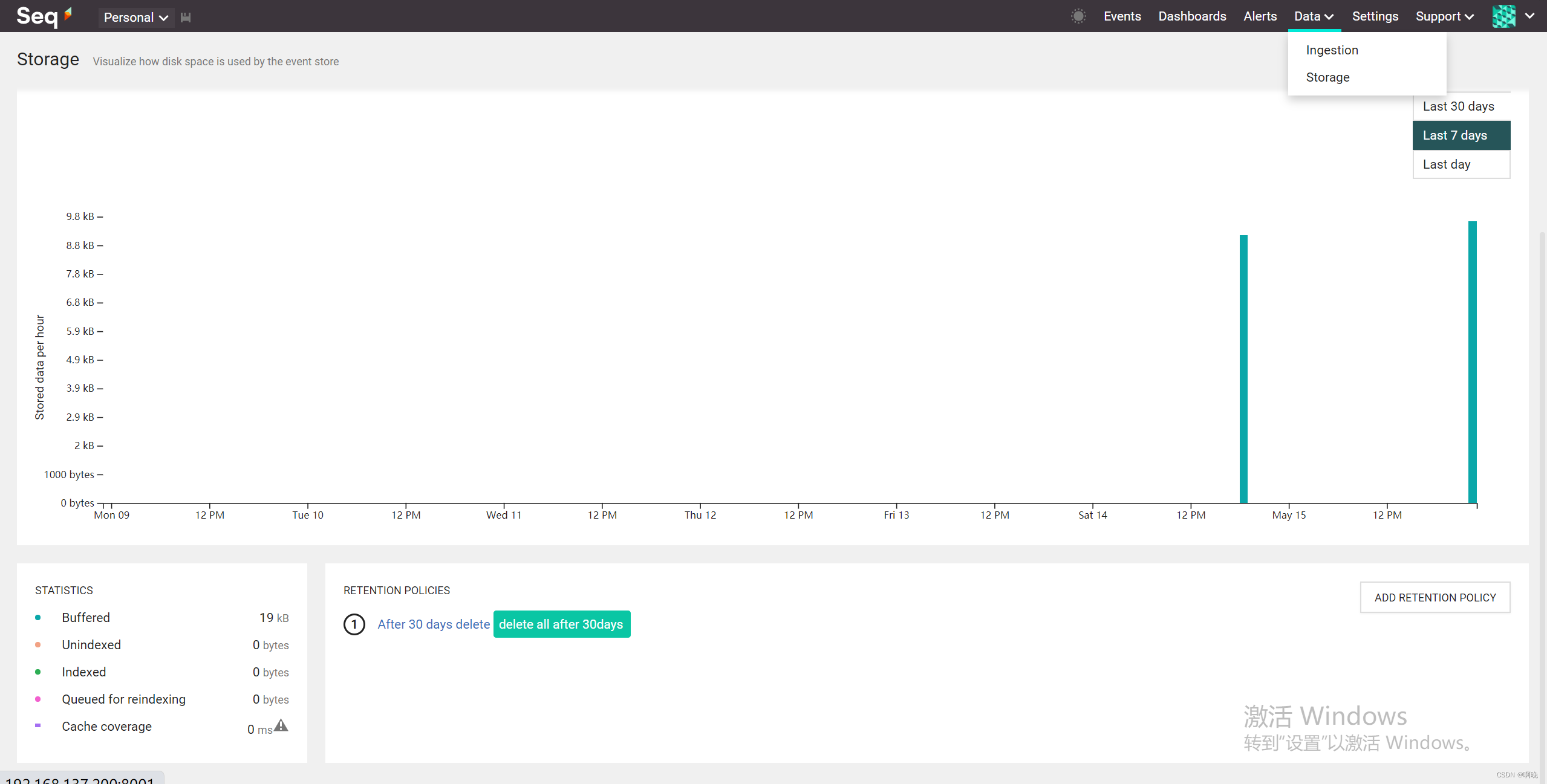
在“Data > Storage”菜单下,可以查看Seq日志存储情况,可以看到各个时间的日志写入情况,也可以看到保留策略的执行情况。
微服务系列文章:
上一篇:分布式日志—Seq(一)
下一篇:容器技术—docker基础















 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









