







 博客介绍了轨迹数据转化为OD数据后,如何通过格网化方法进行处理。首先生成格网对应字典,接着确定OD位置的格网号。然后,按照格网统计数据,分享了对数据整合和处理在研究中的重要性的感悟。强调了技术基础对实现研究想法的必要性,认为技术与想法同样重要。
博客介绍了轨迹数据转化为OD数据后,如何通过格网化方法进行处理。首先生成格网对应字典,接着确定OD位置的格网号。然后,按照格网统计数据,分享了对数据整合和处理在研究中的重要性的感悟。强调了技术基础对实现研究想法的必要性,认为技术与想法同样重要。
前提是已经将轨迹数据处理为了OD数据。
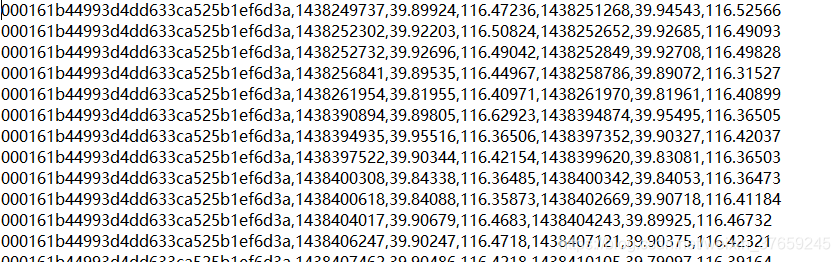
如图,第1列是出租车ID,第2~4列分别是上车位置的时间戳、经纬度;第5到7列是下车位置的时间戳、经纬度。
一、生成格网对应的字典文件
根据数据以及格网大小,使用python手动划分格网,并生成字典文件。
第一列数字代表了格网左上角点的位置,第二列代表了格网号。
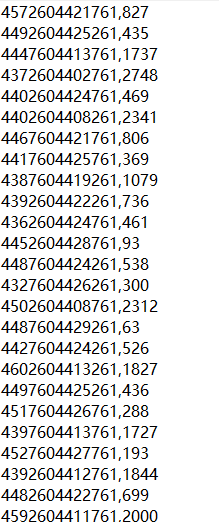
还有一个方法:用arcgis划分格网,然后导出属性表文件(含编号与位置坐标)。但是我发现好像只可以得到格网中心位置点的坐标。因此,要么后续的判别方法根据中心点来判断,要么再对坐标文件处理,将每一个中心点坐标调整为左上角坐标。
二、得到每一个OD位置对应的格网号
# coding: utf-8
import time
import shapefile
from shapely.geometry import Point
from shapely.geometry import Polygon
import pyproj
import csv
def time_stamp(time_s):
time_trans = time.localtime(int(time_s))
return time_trans.tm_mon, time_trans.tm_mday, time_trans.tm_hour
## 定义投影函数
def proj_trans(lon, lat):
p1 = pyproj.Proj(init="epsg:4326")
p2 = pyproj.Proj(init="epsg:32650")
x1, y1 = p1(lon, lat)
x2, y2 = pyproj.transform(p1, p2, x1, y1, radians=True)
return x2, y2
# 1:格网字典生成
with open("C:/Users/lp/GPS-yechao//grid_dict.txt", "r") as f:
grid = dict()
for line in f.readlines():
grid_info = line.rstrip("\n").split(",")
grid[grid_info[0 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









