







目录
1、背景
- 单库单表数据量大,不足以支撑业务发展
- 数据量增大影响读写性能
单表行数超过500万行,或单表容量超过2GB,推荐分库分表。
- 数据库连接有限制,访问连接数过多,会导致连接失败
可以通过数据库连接池优化连接数问题,更好的方式是分库,避免数据库称为业务瓶颈。
2、拆分方式
垂直拆分和水平拆分
- 分库分表方案:只分库、只分表、分库又分表。
- 垂直拆分:由于表数量多导致的单个库大。将表拆分到多个库中。(解决表过多或表字段过多的问题)
- 水平拆分:由于表记录多导致的单个库大。将表记录拆分到多个表中。(解决表中数据过多的问题)
2.1、垂直拆分
将表按库进行分离,或者修改表结构按照访问的差异将某些列拆分出去。应用时有垂直分库和垂直分表两种方式,一般谈到的垂直拆分主要指的是垂直分库。
- 垂直分库:将不同业务逻辑的表放到不同的数据库里。
- 垂直分表:将一张表中不常用的字段拆分到另一张表中,从而保证第一张表中的字段较少,避免出现数据库跨页存储的问题,从而提升查询效率。
垂直拆分优点:
- 拆分后业务清晰,拆分规则明确;
- 易于数据的维护和扩展;
- 可以使得行数据变小,一个数据块 (Block) 就能存放更多的数据,在查询时就会减少 I/O 次数;
- 可以达到最大化利用 Cache 的目的,具体在垂直拆分的时候可以将不常变的字段放一起,将经常改变的放一起;
- 便于实现冷热分离的数据表设计模式。
垂直拆分缺点:
- 主键出现冗余,需要管理冗余列;
- 会引起表连接 JOIN 操作,可以通过在业务服务器上进行 join 来减少数据库压力,提高了系统的复杂度;
- 依然存在单表数据量过大的问题;
- 事务处理复杂。
2.2、水平拆分
通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个表仅包含数据的一部分。
将一张含有很多记录数的表水平切分,不同的记录可以分开保存,拆分成几张结构相同的表。如果一张表中的记录数过多,那么会对数据库的读写性能产生较大的影响,虽然此时仍然能够正确地读写,但读写的速度已经到了业务无法忍受的地步,此时就需要使用水平分表来解决这个问题。
水平拆分优点:
- 拆分规则设计好,join 操作基本可以数据库做;
- 不存在单库大数据,高并发的性能瓶颈;
- 切分的表的结构相同,应用层改造较少,只需要增加路由规则即可;
- 提高了系统的稳定性和负载能力。
水平拆分缺点:
- 拆分规则难以抽象;
- 跨库Join性能较差;
- 分片事务的一致性难以解决;
- 数据扩容的难度和维护量极大
3、主键生成策略
分布式唯一ID,可参考分布式唯一id生成策略_零点冰.的博客-CSDN博客
3.1、UUID
通用唯一识别码,长度是16个字节,被表示为32个十六进制数字,以“ - ”分隔的五组来显示,格式为8-4-4-4-12,共36个字符。
UUID在生成时使用到了以太网卡地址、纳秒级时间、芯片ID码和随机数等信息,目的是让分布式系统中的所有元素都能有唯一的识别信息。
使用UUID做主键,可以在本地生成,没有网络消耗,所以生成性能高。
但是UUID比较长,没有规律性,耗费存储空间,在辅助索引回表查询时有所体现。
在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,影响性能。
3.2、COMB
保留UUID的前10个字节,用后6个字节表示GUID生成的时间(DateTime),这样我们将时间信息与UUID组合起来,在保留UUID的唯一性的同时增加了有序性,以此来提高索引效率。解决UUID无序的问题,性能优于UUID。
3.3、雪花算法
使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号,最后还有一个符号位,永远是0。
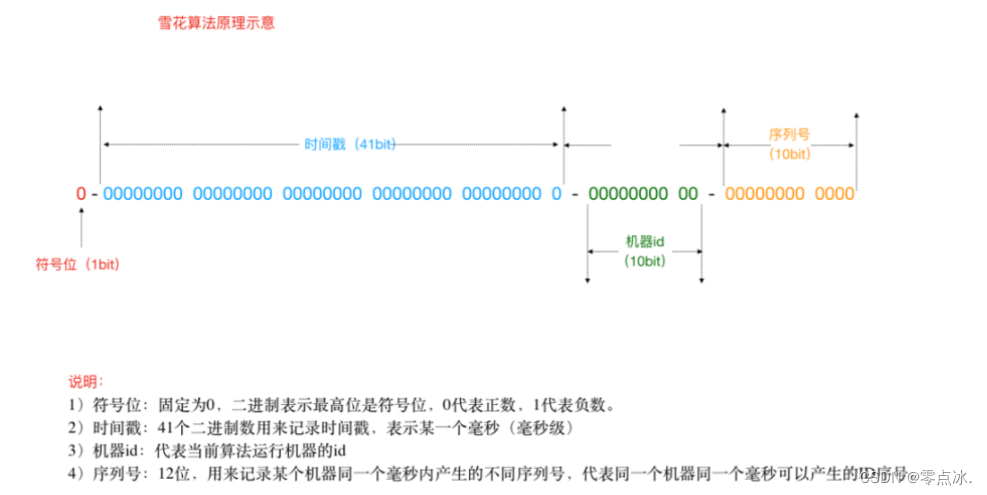
- SnowFlake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID重复,并且效率较高。
- 缺点是强依赖机器时钟,如果多台机器环境时钟没同步,或时钟回拨,会导致发号重复或者服务会处于不可用状态。
3.4、数据库ID表
单独的创建一个MySQL数据库,在这个数据库中创建一张表,这张表的ID设置为自动递增,其他地方需要全局唯一ID的时候,就先向这个这张表中模拟插入一条记录,此时ID就会自动递增
3.5、Redis生成ID
主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
4、分片策略
规则,分片结果就是分库分表。
分片(Sharding)就是用来确定数据在多台存储设备上分布的技术。
- 分片:表示分配过程,是一个逻辑上概念,表示如何实现;
- 分库分表:表示分配结果,是一个物理上概念,表示最终实现的结果。
数据库扩展方案:
- 横向扩展:一个库变多个库,加机器数量;
- 纵向扩展:一个库还是一个库,优化机器性能,加高配CPU或内存。
分片键:用于划分和定位表的字段。
分片策略:分片规则。
4.1、基于范围分片
根据特定字段的范围进行拆分,比如用户ID、订单时间、产品价格等。例如:
{[1 - 100] => Cluster A, [101 - 199] => Cluster B}
优点:新的数据可以落在新的存储节点上,如果集群扩容,数据无需迁移。
缺点:数据热点分布不均,数据冷热不均匀,导致节点负荷不均。
4.2、哈希取模分片
整型的Key可直接对设备数量取模,其他类型的字段可以先计算Key的哈希值,然后再对设备数量取模。假设有n台设备,编号为0 ~ n-1,通过Hash(Key) % n就可以确定数据所在的设备编号。该模式也称为离散分片。
优点:实现简单,数据分配比较均匀,不容易出现冷热不均,负荷不均的情况。
缺点:扩容时会产生大量的数据迁移,比如从n台设备扩容到n+1,绝大部分数据需要重新分配和迁移。
4.3、一致性hash分片
采用Hash取模的方式进行拆分,后期集群扩容需要迁移旧的数据。使用一致性Hash算法能够很大程度的避免这个问题。
一致性Hash是将数据按照特征值映射到一个首尾相接的Hash环上,同时也将节点(按照IP地址或者机器名Hash)映射到这个环上。对于数据,从数据在环上的位置开始,顺时针找到的第一个节点即为数据的存储节点。Hash环示意图与数据的分布如下:
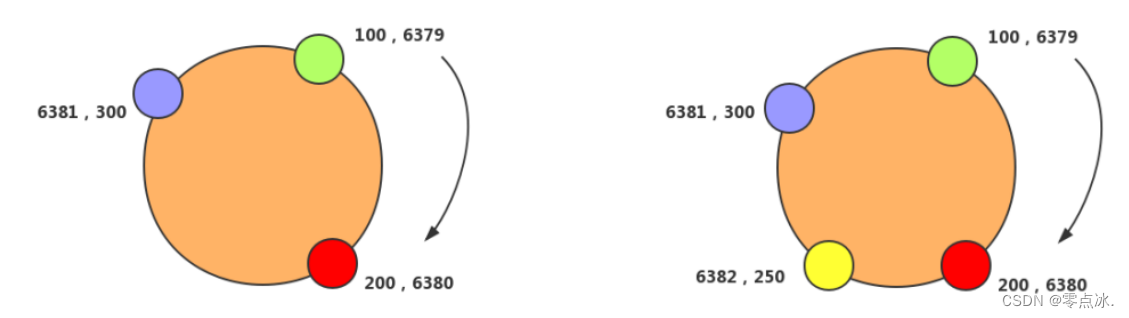
一致性Hash在增加或者删除节点的时候,受到影响的数据是比较有限的,只会影响到Hash环相邻的节点,不会发生大规模的数据迁移。
5、扩容策略
- 数据迁移问题
- 分片规则改变
- 数据同步、时间点、数据一致性
5.1、停机扩容
- 新增n个数据库,然后写一个数据迁移程序,将原有x个库的数据导入到最新的y个库中。比如分片规则由%x变为%y;
- 数据迁移完成,修改数据库服务配置,原来x个库的配置升级为y个库的配置;
- 重启服务,连接新库重新对外提供服务;
回滚方案:万一数据迁移失败,需要将配置和数据回滚,改天再挂公告。
优点:简单
缺点:
- 停止服务,缺乏高可用
- 程序员压力山大,需要在指定时间完成
- 如果有问题没有及时测试出来启动了服务,运行后发现问题,数据会丢失一部分,难以回滚。
适用场景:
- 小型网站
- 大部分游戏
- 对高可用要求不高的服务
5.2、平滑扩容
平滑扩容就是将数据库数量扩容成原来的2倍。
- 新增2个数据库
- 配置双主进行数据同步(先测试、后上线)
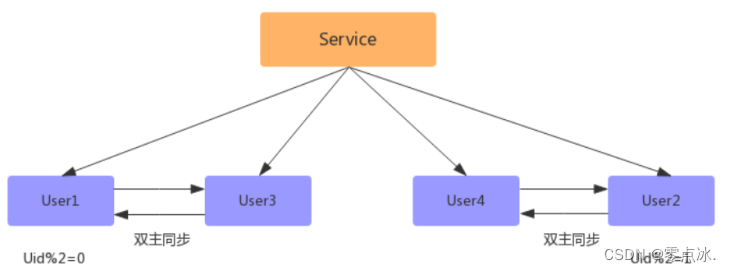
- 数据同步完成之后,配置双主双写(同步因为有延迟,如果时时刻刻都有写和更新操作,会存在不准确问题)
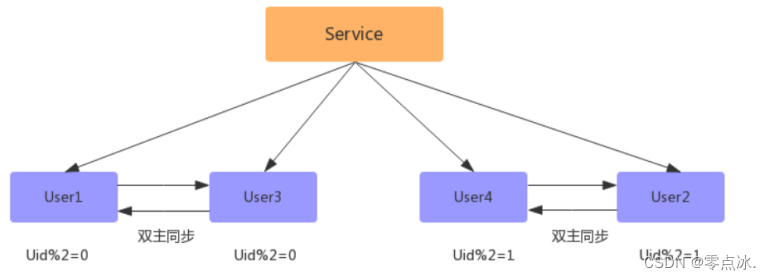
- 数据同步完成后,删除双主同步,修改数据库配置,并重启;
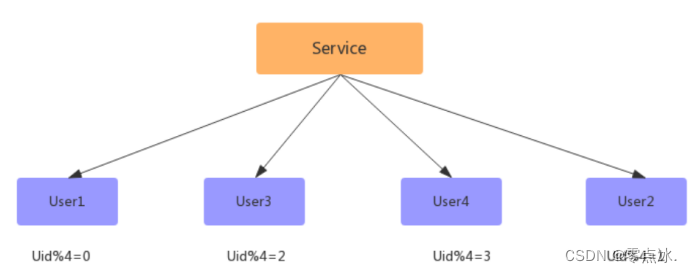
此时已经扩容完成,但此时的数据并没有减少,新增的数据库跟旧的数据库一样多的数据,此时还需要写一个程序,清空数据库中多余的数据,如:
User1去除 uid % 4 = 2的数据;
User3去除 uid % 4 = 0的数据;
User2去除 uid % 4 = 3的数据;
User4去除 uid % 4 = 1的数据;
平滑扩容方案能够实现n库扩2n库的平滑扩容,增加数据库服务能力,降低单库一半的数据量。其核心原理是:成倍扩容,避免数据迁移。
优点:
- 扩容期间,服务正常进行,保证高可用
- 相对停机扩容,时间长,项目组压力没那么大,出错率低
- 扩容期间遇到问题,随时解决,不怕影响线上服务
- 可以将每个数据库数据量减少一半
缺点:
- 程序复杂、配置双主同步、双主双写、检测数据同步等
- 后期数据库扩容,比如成千上万,代价比较高
适用场景:
- 大型网站
- 对高可用要求高的服务
6、分库分表引入的问题
- 分布式事务问题
对业务进行分库,同一个操作可能分散到多个数据库中,设计跨库执行SQL语句,就会有分布式事务问题。
- 跨库关联查询
跨库和跨表的关联查询操作更复杂,性能会受到影响。
- 跨库跨表的合并与排序
查询指定列表、或者需要对数据列表进行排序,则需要在内存中进行处理,整体性能差。
以上内容为个人学习理解,如有问题,欢迎在评论区指出。
部分内容截取自网络,如有侵权,联系作者删除。















 4835
4835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









