









Sentinel原生使用
我们先从sentinel的原生api调用开始讲起,慢慢地再深入到与springcloud的整合使用
引入sentinel原生的依赖包
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.8.0</version>
</dependency>在接口中调用sentinel的api
@RestController
public class TestController {
@PostConstruct
public void init() {
// 定义好限流规则
List<FlowRule> flowRuleList = new ArrayList<>();
FlowRule flowRule = new FlowRule();
flowRule.setGrade(RuleConstant.FLOW_GRADE_QPS);
flowRule.setResource("test");
flowRule.setCount(1);
flowRuleList.add(flowRule);
FlowRuleManager.loadRules(flowRuleList);
}
@GetMapping("/test")
public String test() {
ContextUtil.enter("application");
Entry entry = null;
try {
entry = SphU.entry("test");
// 业务逻辑...
} catch (BlockException e) { // 捕获限流等异常
e.printStackTrace();
}finally {
if (entry != null) {
entry.exit();
}
}
return "test";
}
}在执行我们的业务逻辑之前,调用SphU.entry(“resourceName”)这句代码就可以起到限流的作用,这里面能够起到限流的原理我们这里先不去细讲,我们需要注意的是可以看到一句代码
ContextUtil.enter("application");这句代码是干嘛的呢?这就牵扯到sentinel中的context上下文以及后面由node组成的调用树了
ProcessorSlot调用链的形成
sentinel中能够提供限流,熔断降低等保护资源的功能,基础的核心靠的就是里面形成的调用树,那么这个调用树在sentinel中是怎么形成的呢?具体我们一步步地深入到源码中去探索
ContextUtil中的静态代码块
看enter方法之前先来看下ContextUtil的static静态代码块
static {
// Cache the entrance node for default context.
initDefaultContext();
}
private static void initDefaultContext() {
String defaultContextName = Constants.CONTEXT_DEFAULT_NAME;
EntranceNode node = new EntranceNode(new StringResourceWrapper(defaultContextName, EntryType.IN), null);
Constants.ROOT.addChild(node);
contextNameNodeMap.put(defaultContextName, node);
}可以看到上面初始化了一个EntranceNode,并且还new了一个资源对象,这个资源对象的名称就是sentinel_default_context,并且把这个资源对象作为参数传给了EntranceNode,然后这个EntranceNode作为了一个子节点加入到全局的root这个node中,也就是说一开始就有一颗初始化的调用树生成了,如下图:
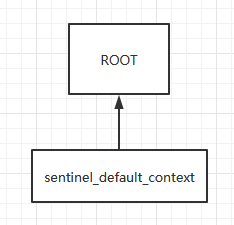
最后把contextName,也就是sentinel_default_context作为key,EntranceNode作为value放到一个全局的map中
com.alibaba.csp.sentinel.context.ContextUtil#enter(java.lang.String, java.lang.String)
接着来看调用的enter方法
public static Context enter(String name) {
return enter(name, "");
}
// name: contextName
// origin: dashboard添加流控规则的“了针对来源”
public static Context enter(String name, String origin) {
if (Constants.CONTEXT_DEFAULT_NAME.equals(name)) {
throw new ContextNameDefineException(
"The " + Constants.CONTEXT_DEFAULT_NAME + " can't be permit to defined!");
}
return trueEnter(name, origin);
}
protected static Context trueEnter(String name, String origin) {
// 尝试着从ThreadLocal中获取Context
Context context = contextHolder.get();
// 若ThreadLocal中没有context,则尝试着从缓存map中获取
if (context == null) {
// 缓存map的key为context名称,value为EntranceNode
Map<String, DefaultNode> localCacheNameMap = contextNameNodeMap;
// 获取EntranceNode——双重检测锁DCL——为了防止并发创建
DefaultNode node = localCacheNameMap.get(name);
if (node == null) {
// 若缓存map的size 大于 context数量的最大阈值,则直接返回NULL_CONTEXT
if (localCacheNameMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
LOCK.lock();
try {
node = contextNameNodeMap.get(name);
if (node == null) {
if (contextNameNodeMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
// 创建一个EntranceNode
node = new EntranceNode(new StringResourceWrapper(name, EntryType.IN), null);
// Add entrance node.将新建的node添加到ROOT
Constants.ROOT.addChild(node);
// 将新建node写入到缓存map
// 为了防止“迭代稳定性问题”——iterate stable——对于共享集合的写操作
Map<String, DefaultNode> newMap = new HashMap<>(contextNameNodeMap.size() + 1);
newMap.putAll(contextNameNodeMap);
newMap.put(name, node);
contextNameNodeMap = newMap;
}
}
} finally {
LOCK.unlock();
}
}
}
// 将context的name与entranceNode封装为context
context = new Context(node, name);
// 初始化context的来源
context.setOrigin(origin);
// 将context写入到ThreadLocal
contextHolder.set(context);
}
return context;
}从上面的流程中可以看出来,首先会先从ThreadLocal中去找是否存在当前线程的Context,如果不存在的话,就创建一个Context,接着再根据传进来的contextName去全局map中找是否有对应的EntranceNode,如果不存在就创建一个新的EntranceNode(并且会创建以contextname为名称的资源对象放到EntranceNode里面),否则存在的话直接返回,并且把这个EntranceNode作为参数放到Context中,最后把context放到ThreadLocal中。
也就是说上面这段代码所形成的调用树就是EntranceNode的个数是跟随着ContextName的个数走的并且EntranceNode的名称也是跟ContextName一样,例如我们的代码如下:
ContextUtil.enter("application1");
ContextUtil.enter("application2");当我们分别调用上面两句代码的时候,此时sentinel中的调用树就会变成如下图所示:

而假如此时sentinel的调用树就是如上图所示的时候,我们用线程t1继续调用ContextUtil.enter("application1")这句代码的时候,此时就可以找到名称为application1的这个EntranceNode对象实例,并且t1线程会创建一个新的Context对象并把application1这个EntranceNode对象放到新创建的Context对象中,同理如果用t2线程调用也是上述的过程。总结来说就是只要是在这个调用树里面有了这个contextname的EntranceNode,那么之后只要调用ContextUtil.enter("contextname")这句代码操作的EntranceNode的实例对象都是调用树中的那个EntranceNode对象。
com.alibaba.csp.sentinel.SphU#entry(java.lang.String)
public static Entry entry(String name) throws BlockException {
return Env.sph.entry(name, EntryType.OUT, 1, OBJECTS0);
}
public Entry entry(String name, EntryType type, int count, Object... args) throws BlockException {
StringResourceWrapper resource = new StringResourceWrapper(name, type);
return entry(resource, count, args);
}
public Entry entry(ResourceWrapper resourceWrapper, int count, Object... args) throws BlockException {
return entryWithPriority(resourceWrapper, count, false, args);
}
private Entry entryWithPriority(ResourceWrapper resourceWrapper, int count, boolean prioritized, Object... args)
throws BlockException {
// 从ThreadLocal中获取context
// 即一个请求会占用一个线程,一个线程会绑定一个context
Context context = ContextUtil.getContext();
// 若context是NullContext类型,则表示当前系统中的context数量已经超出的阈值
// 即访问请求的数量已经超出了阈值。此时直接返回一个无需做规则检测的资源操作对象
if (context instanceof NullContext) {
// The {@link NullContext} indicates that the amount of context has exceeded the threshold,
// so here init the entry only. No rule checking will be done.
return new CtEntry(resourceWrapper, null, context);
}
// 若当前线程中没有绑定context,则创建一个context并将其放入到ThreadLocal
if (context == null) {
// Using default context.
context = InternalContextUtil.internalEnter(Constants.CONTEXT_DEFAULT_NAME);
}
// 若全局开关是关闭的,则直接返回一个无需做规则检测的资源操作对象
// Global switch is close, no rule checking will do.
if (!Constants.ON) {
return new CtEntry(resourceWrapper, null, context);
}
// 查找SlotChain
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
/*
* Means amount of resources (slot chain) exceeds {@link Constants.MAX_SLOT_CHAIN_SIZE},
* so no rule checking will be done.
*/
// 若没有找到chain,则意味着chain数量超出了阈值,则直接返回一个无需做规则检测的资源操作对象
if (chain == null) {
return new CtEntry(resourceWrapper, null, context);
}
// 创建一个资源操作对象
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
// 对资源进行操作
chain.entry(context, resourceWrapper, null, count, prioritized, args);
} catch (BlockException e1) {
e.exit(count, args);
throw e1;
} catch (Throwable e1) {
// This should not happen, unless there are errors existing in Sentinel internal.
RecordLog.info("Sentinel unexpected exception", e1);
}
return e;
}在上面的代码中我们关注三点:
- context = InternalContextUtil.internalEnter(Constants.CONTEXT_DEFAULT_NAME);
在第一点中主要就是从ThreadLocal中拿出该线程对应的context对象,如果该线程没有context对象,那么就创建一个contextname等于sentinel_context_default的context对象,并且根据我们上面的结论可以得知此时的调用树里面也会创建了一个名称为sentinel_context_default的EntranceNode。值得注意的是当sentinel与spring整合之后,如果使用@SentinelResource注解去声明一个资源的这种方式,那么sentinel是不会显式地调用ContextUtil.enter("contextname");这句代码的,也就是说使用这种方式会创建默认名称为sentinel_context_default的context(其实也不用创建,因为ContextUtil的静态代码块在初始化的时候已经创建了)
- ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
第二点的话作用就是创建一个由ProcessorSlot组成的链表调用链(责任链模式)并根据资源对象加入到缓存map中
- chain.entry(context, resourceWrapper, null, count, prioritized, args);
第三点执行创建好的链表调用链
创建context的逻辑我们一开始已经说了,那么就看下第二点关于ProcessorSlot调用链是怎么形成的
ProcessorSlot<Object> lookProcessChain(ResourceWrapper resourceWrapper) {
// 从缓存map中获取当前资源的SlotChain
// 缓存map的key为资源,value为其相关的SlotChain
// 由于key是ResourceWrapper,所以,对于相同名称的资源来说,都是使用的同一个ProcessorSlotChain,也就是说处理同一个resource的时候,会进入到同一个slot实例中。
ProcessorSlotChain chain = chainMap.get(resourceWrapper);
// DCL
// 若缓存中没有相关的SlotChain,则创建一个并放入到缓存
if (chain == null) {
synchronized (LOCK) {
chain = chainMap.get(resourceWrapper);
if (chain == null) {
// Entry size limit.
// 缓存map的size >= chain数量最大阈值,则直接返回null,不再创建新的chain
if (chainMap.size() >= Constants.MAX_SLOT_CHAIN_SIZE) {
return null;
}
// 创建新的chain
chain = SlotChainProvider.newSlotChain();
// 防止迭代稳定性问题
Map<ResourceWrapper, ProcessorSlotChain> newMap = new HashMap<ResourceWrapper, ProcessorSlotChain>(
chainMap.size() + 1);
newMap.putAll(chainMap);
newMap.put(resourceWrapper, chain);
chainMap = newMap;
}
}
}
return chain;
}首先会从一个map中根据ResourceWrapper资源对象去找对应的ProcessorSlot调用链,那么这里就有个点需要注意的了,我们从SphU.entry(resourceName)这个方法中可以看到每次调用这个方法里面都会创建一个StringResourceWrapper资源对象,一直作为参数传到lookProcessChain方法,那么SphU.entry(resourceName)如果调用多次的话就会创建多个StringResourceWrapper对象,而根据HashMap的原理,HashMap去put一对键值对需要去判断这个key是否存在,判断的依据就是根据这个key的hashCode方法和equals方法决定这个key是否存在,而sentinel在访问同一个资源的时候都会去创建一个资源对象,难道StringResourceWrapper中重写了hashCode方法和equals方法吗?
/**
* Only {@link #getName()} is considered.
* 重写hashcode以及下面的equals方面表明对于相同名称的ResourceWrapper对象都是同一个对象
*/
@Override
public int hashCode() {
return getName().hashCode();
}
/**
* Only {@link #getName()} is considered.
*/
@Override
public boolean equals(Object obj) {
if (obj instanceof ResourceWrapper) {
ResourceWrapper rw = (ResourceWrapper)obj;
return rw.getName().equals(getName());
}
return false;
}果然在StringResourceWrapper的父类ResourceWrapper中重写了hashCode方法和equals方法,重写的逻辑就是根据传入的resourceName去判断该是否两个对象相同,所以上面chainMap.get(resourceWrapper);中如果传入的资源对象的资源名称都是一样的,那么就可以拿到同样的ProcessorSlot调用链,也就是说相同名称的资源共享同一个ProcessorSlot调用链。所以当访问一个资源的时候就会从chainMap中根据资源对象找到一个ProcessorSlot调用链并返回,如果这个资源是第一次访问,就需要去创建一个ProcessorSlot调用链,创建完成就放到chainMap中,那么是如何创建这个processorSlot的呢?如下:
public final class SlotChainProvider {
private static volatile SlotChainBuilder slotChainBuilder = null;
public static ProcessorSlotChain newSlotChain() {
// 若builder不为null,则直接使用builder构建一个chain,否则先创建一个builder
if (slotChainBuilder != null) {
return slotChainBuilder.build();
}
// Resolve the slot chain builder SPI.
// 通过SPI方式创建一个builder
slotChainBuilder = SpiLoader.of(SlotChainBuilder.class).loadFirstInstanceOrDefault();
// 若通过SPI方式未能创建builder,则手工new一个DefaultSlotChainBuilder
if (slotChainBuilder == null) {
// Should not go through here.
RecordLog.warn("[SlotChainProvider] Wrong state when resolving slot chain builder, using default");
slotChainBuilder = new DefaultSlotChainBuilder();
} else {
RecordLog.info("[SlotChainProvider] Global slot chain builder resolved: {}",
slotChainBuilder.getClass().getCanonicalName());
}
// 构建一个chain
return slotChainBuilder.build();
}
private SlotChainProvider() {}
}可以看到sentinel通过SlotChainProvider这个类去创建一个ProcessorSlot调用链,而这个类里面实际上又是通过委托slotChainBuilder这个构造器去创建ProcessorSlot的,这个构造器是通过SPI机制加载出来的,具体实现类是DefaultSlotChainBuilder,看下这个构造器是如何创建ProcessorSlot调用链的
@Spi(isDefault = true)
public class DefaultSlotChainBuilder implements SlotChainBuilder {
@Override
public ProcessorSlotChain build() {
ProcessorSlotChain chain = new DefaultProcessorSlotChain();
// 通过SPI方式构建Slot
List<ProcessorSlot> sortedSlotList = SpiLoader.of(ProcessorSlot.class).loadInstanceListSorted();
for (ProcessorSlot slot : sortedSlotList) {
if (!(slot instanceof AbstractLinkedProcessorSlot)) {
RecordLog.warn("The ProcessorSlot(" + slot.getClass().getCanonicalName() + ") is not an instance of AbstractLinkedProcessorSlot, can't be added into ProcessorSlotChain");
continue;
}
chain.addLast((AbstractLinkedProcessorSlot<?>) slot);
}
return chain;
}
}首先它先是new了一个DefaultProcessorSlotChain对象,然后又是通过SPI去加载类路径下所有的processorSlot实现类,然后把这些实现类依次add到DefaultProcessorSlotChain中从而形成了一条链表数据结构的调用链,而DefaultProcessorSlot里面维护了两个指针,一个是first指针,一个是end指针,代码如下:
// 这是一个单向链表,默认包含一个节点,且有两个指针first与end同时指向这个节点
public class DefaultProcessorSlotChain extends ProcessorSlotChain {
AbstractLinkedProcessorSlot<?> first = new AbstractLinkedProcessorSlot<Object>() {
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, Object t, int count, boolean prioritized, Object... args)
throws Throwable {
super.fireEntry(context, resourceWrapper, t, count, prioritized, args);
}
@Override
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {
super.fireExit(context, resourceWrapper, count, args);
}
};
AbstractLinkedProcessorSlot<?> end = first;
@Override
public void addFirst(AbstractLinkedProcessorSlot<?> protocolProcessor) {
protocolProcessor.setNext(first.getNext());
first.setNext(protocolProcessor);
if (end == first) {
end = protocolProcessor;
}
}
@Override
public void addLast(AbstractLinkedProcessorSlot<?> protocolProcessor) {
end.setNext(protocolProcessor);
end = protocolProcessor;
}
/**
* Same as {@link #addLast(AbstractLinkedProcessorSlot)}.
*
* @param next processor to be added.
*/
@Override
public void setNext(AbstractLinkedProcessorSlot<?> next) {
addLast(next);
}
@Override
public AbstractLinkedProcessorSlot<?> getNext() {
return first.getNext();
}
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, Object t, int count, boolean prioritized, Object... args)
throws Throwable {
// 转向下一个节点
first.transformEntry(context, resourceWrapper, t, count, prioritized, args);
}
@Override
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {
first.exit(context, resourceWrapper, count, args);
}
}所以总的来说DefaultProcessorSlotChain就是一个集合,这个集合里面放的就是一个个的slot对象,这些slot对象通过链表的数据结构去互相联系,下面我们来看下一共有哪些slot。对于sentinel来说,它所拥有的功能点都是由一个个的slot来完成的,每一个slot对应一种功能的实现,下面看下sentinel官方给的一张图
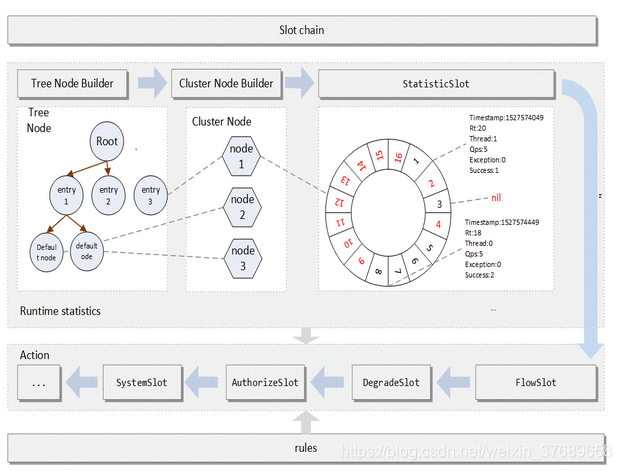
其中StatisticSlot之后的slot都是我们可以制定规则的slot,那么NodeSelectorSlot,ClusterBuilderNode以及StatisticSlot这三个slot并不是与规则相关的,那么它们是干嘛的呢?
关于构建node调用树的slot
(1)NodeSelectorSlot
该slot是整个slot链表的第一个slot,它的作用就是负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级
/**
* 由于生成slot调用链的是根据resource区分生成的,所以只要是访问的相同的resource,那么都会使用同一个slot实例进行这个resource请求的拦截处理
* 例如调用了resource1和resource2,那么两者执行的NodeSelectorSlot是不同的两个实例对象
*/
@Spi(isSingleton = false, order = Constants.ORDER_NODE_SELECTOR_SLOT)
public class NodeSelectorSlot extends AbstractLinkedProcessorSlot<Object> {
/**
* 缓存了同一个资源在哪些上下文中被访问过
* key=>上下文名称
* value=>DefaultNode(资源节点)
*/
private volatile Map<String, DefaultNode> map = new HashMap<String, DefaultNode>(10);
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, Object obj, int count, boolean prioritized, Object... args)
throws Throwable {
// 根据上下文名称从缓存中获取DefaultNode
DefaultNode node = map.get(context.getName());
// 条件成立:说明当前访问的资源还没在这个上下文中被访问过
if (node == null) {
// DCL
synchronized (this) {
node = map.get(context.getName());
if (node == null) {
// 创建一个资源节点,并放入map中
node = new DefaultNode(resourceWrapper, null);
HashMap<String, DefaultNode> cacheMap = new HashMap<String, DefaultNode>(map.size());
cacheMap.putAll(map);
cacheMap.put(context.getName(), node);
map = cacheMap;
// 这句代码的作用是构建调用树(将代表当前访问资源的DefaultNode添加到调用树中)
// 添加方式就是获取到调用树的最后一个节点,然后把新建的DefaultNode关联到这个节点上
// 这个场景就是:在同一个context中嵌套调用两个不同的资源,比如resource1中嵌套调用了resource2,调用树就应该是root->entranceNode->resource1->resource2
((DefaultNode) context.getLastNode()).addChild(node);
}
}
}
// 把上下文的当前节点设置为这个正在访问的资源节点
context.setCurNode(node);
// 触发下一个节点
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
@Override
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {
fireExit(context, resourceWrapper, count, args);
}
}
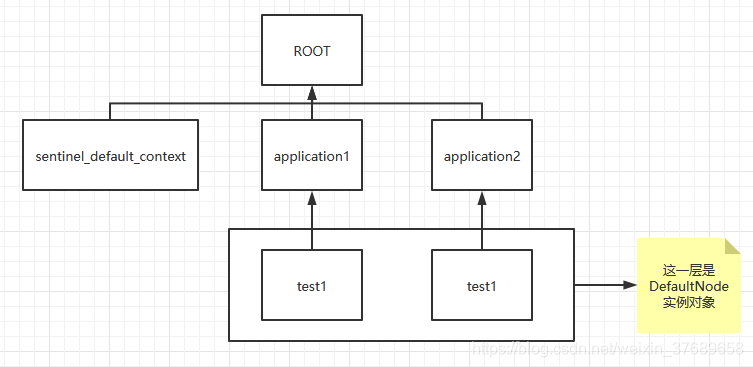
可以发现这个slot中有一个缓存map,首先我们要清楚,对于同一个资源,它所对应的ProcessorSlot都是相同的,不管这个资源是在哪一个context中被访问,从上面的代码逻辑可以发现这个缓存map是以contextname去作为key去区分value的,所以该map中缓存的是某一个资源在不同的context下面所对应的DefaultNode,也就是说如果我们在不同的context下面访问同一个资源,那么此时就会创建多个DefaultNode实例,而这多个DefaultNode实例所对应的也是同一个资源,但是它所代表的这个资源的维度是以context为维度的,是代表一个context下面的一个资源,尽管是访问的同一个资源,但是这个资源并不是在同一个context下面被访问的话,那么就会创建多个DefaultNode对象去代表这个资源,对应的代码及其调用树的图如下:
@GetMapping("/test1")
public String test1() {
ContextUtil.enter("application1");
Entry entry = null;
try {
entry = SphU.entry("test1");
// 业务逻辑...
} catch (BlockException e) { // 捕获限流等异常
e.printStackTrace();
}finally {
if (entry != null) {
entry.exit();
}
}
return "test1";
}
@GetMapping("/test2")
public String test2() {
ContextUtil.enter("application2");
Entry entry = null;
try {
entry = SphU.entry("test1");
// 业务逻辑...
} catch (BlockException e) { // 捕获限流等异常
e.printStackTrace();
}finally {
if (entry != null) {
entry.exit();
}
}
return "test2";
}
(2)ClusterBuilderSlot
该slot用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据
@Spi(isSingleton = false, order = Constants.ORDER_CLUSTER_BUILDER_SLOT)
public class ClusterBuilderSlot extends AbstractLinkedProcessorSlot<DefaultNode> {
private static volatile Map<ResourceWrapper, ClusterNode> clusterNodeMap = new HashMap<>();
private static final Object lock = new Object();
private volatile ClusterNode clusterNode = null;
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args)
throws Throwable {
// ClusterNode对应一个资源,不管这个资源是在哪个context中
if (clusterNode == null) {
synchronized (lock) {
if (clusterNode == null) {
// Create the cluster node.
clusterNode = new ClusterNode(resourceWrapper.getName(), resourceWrapper.getResourceType());
HashMap<ResourceWrapper, ClusterNode> newMap = new HashMap<>(Math.max(clusterNodeMap.size(), 16));
newMap.putAll(clusterNodeMap);
newMap.put(node.getId(), clusterNode);
clusterNodeMap = newMap;
}
}
}
// 把ClusterNode设置给不同context下的同一个resource(DefaultNode)
// 也就是说不同context下的同一个resource(DefaultNode)里面的ClusterNode都是同一个对象
// 当这些DefaultNode都调用一些统计数据的api时,会同时调用ClusterNode的统计数据的api,所以ClusterNode就能够统计所有context下同一个resource的数据了
node.setClusterNode(clusterNode);
// 如果origin不是默认值
if (!"".equals(context.getOrigin())) {
Node originNode = node.getClusterNode().getOrCreateOriginNode(context.getOrigin());
// 把该origin对应的StatisticNode设置给当前的调用链路对象entry
context.getCurEntry().setOriginNode(originNode);
}
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
@Override
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {
fireExit(context, resourceWrapper, count, args);
}
public static ClusterNode getClusterNode(String id, EntryType type) {
return clusterNodeMap.get(new StringResourceWrapper(id, type));
}
public static ClusterNode getClusterNode(String id) {
if (id == null) {
return null;
}
ClusterNode clusterNode = null;
for (EntryType nodeType : EntryType.values()) {
clusterNode = clusterNodeMap.get(new StringResourceWrapper(id, nodeType));
if (clusterNode != null) {
break;
}
}
return clusterNode;
}
public static Map<ResourceWrapper, ClusterNode> getClusterNodeMap() {
return clusterNodeMap;
}
public static void resetClusterNodes() {
for (ClusterNode node : clusterNodeMap.values()) {
node.reset();
}
}
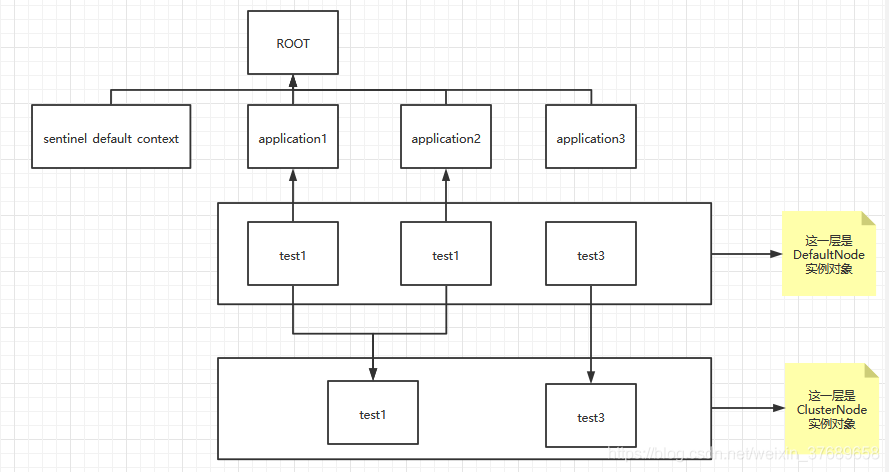
}简单来说这个slot所做的就是去给DefaultNode去绑定一个ClusterNode,ClusterNode的作用就是用来统计在不同context中访问同一个资源的时候这个资源的统计数据。对应的代码及其调用树的图如下:
@GetMapping("/test1")
public String test1() {
ContextUtil.enter("application1");
Entry entry = null;
try {
entry = SphU.entry("test");
// 业务逻辑...
} catch (BlockException e) { // 捕获限流等异常
e.printStackTrace();
}finally {
if (entry != null) {
entry.exit();
}
}
return "test1";
}
@GetMapping("/test2")
public String test2() {
ContextUtil.enter("application2");
Entry entry = null;
try {
entry = SphU.entry("test2");
// 业务逻辑...
} catch (BlockException e) { // 捕获限流等异常
e.printStackTrace();
}finally {
if (entry != null) {
entry.exit();
}
}
return "test2";
}
@GetMapping("/test3")
public String test3() {
ContextUtil.enter("application3");
Entry entry = null;
try {
entry = SphU.entry("test3");
// 业务逻辑...
} catch (BlockException e) { // 捕获限流等异常
e.printStackTrace();
}finally {
if (entry != null) {
entry.exit();
}
}
return "test3";
}
(3)StatisticSlot
用于记录、统计不同纬度的 runtime 指标监控信息
@Spi(order = Constants.ORDER_STATISTIC_SLOT)
public class StatisticSlot extends AbstractLinkedProcessorSlot<DefaultNode> {
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
try {
// Do some checking.
// 调用SlotChain中后续的所有Slot,完成所有规则检测
// 其在执行过程中可能会抛出异常,例如,规则检测未通过,抛出BlockException
fireEntry(context, resourceWrapper, node, count, prioritized, args);
// Request passed, add thread count and pass count.
// 代码能走到这里,说明前面所有规则检测全部通过,此时就可以将该请求统计到相应数据中了
// 增加线程数据
node.increaseThreadNum();
// 增加通过的请求数量
node.addPassRequest(count);
if (context.getCurEntry().getOriginNode() != null) {
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
context.getCurEntry().getOriginNode().addPassRequest(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
Constants.ENTRY_NODE.addPassRequest(count);
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (PriorityWaitException ex) {
node.increaseThreadNum();
if (context.getCurEntry().getOriginNode() != null) {
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (BlockException e) {
// Blocked, set block exception to current entry.
context.getCurEntry().setBlockError(e);
// Add block count.
node.increaseBlockQps(count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseBlockQps(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseBlockQps(count);
}
// Handle block event with registered entry callback handlers.
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onBlocked(e, context, resourceWrapper, node, count, args);
}
throw e;
} catch (Throwable e) {
// Unexpected internal error, set error to current entry.
context.getCurEntry().setError(e);
throw e;
}
}
@Override
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {
Node node = context.getCurNode();
if (context.getCurEntry().getBlockError() == null) {
// Calculate response time (use completeStatTime as the time of completion).
long completeStatTime = TimeUtil.currentTimeMillis();
context.getCurEntry().setCompleteTimestamp(completeStatTime);
long rt = completeStatTime - context.getCurEntry().getCreateTimestamp();
Throwable error = context.getCurEntry().getError();
// Record response time and success count.
recordCompleteFor(node, count, rt, error);
recordCompleteFor(context.getCurEntry().getOriginNode(), count, rt, error);
if (resourceWrapper.getEntryType() == EntryType.IN) {
recordCompleteFor(Constants.ENTRY_NODE, count, rt, error);
}
}
// Handle exit event with registered exit callback handlers.
Collection<ProcessorSlotExitCallback> exitCallbacks = StatisticSlotCallbackRegistry.getExitCallbacks();
for (ProcessorSlotExitCallback handler : exitCallbacks) {
handler.onExit(context, resourceWrapper, count, args);
}
fireExit(context, resourceWrapper, count);
}
private void recordCompleteFor(Node node, int batchCount, long rt, Throwable error) {
if (node == null) {
return;
}
node.addRtAndSuccess(rt, batchCount);
node.decreaseThreadNum();
if (error != null && !(error instanceof BlockException)) {
node.increaseExceptionQps(batchCount);
}
}
}可以看到在StatisticSlot的entry方法去执行它的逻辑的时候,它一开始就调用了fireEntry去直接调用下一个slot的逻辑去了,而它的工作主要是处理后面的规则slot执行完成或者执行抛出异常的时候的结果,当后面的规则slot都执行完了之后,就表明这个资源能够符合当前的一些限流流控降级等规则,那么此时就会通过当前调用树路径的DefaultNode去进行统计数据了,比如增加当前资源的qps,线程通过数等等,而当后面的规则slot执行抛出了异常,表示该资源不符合限流流控降级等规则的,那么此时就会进行StatisticSlot的catch代码块去对异常进行对应的处理操作,比如增加当前资源的被阻塞的qps等等
总结
sentinel在node调用树的基础去通过一系列的规则slot去达到限流流控降级功能的实现,并且这些规则slot是通过链表的数据结构去进行级联调用的,它们都分别对应着一个功能点,而在slot调用链中可以分为两种类型的slot,一种就是用于构建node调用树的slot,一种就是用于根据不同的规则去对资源限定访问的slot
















 1964
1964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









