






检索增强生成(Retrieval-Augmented Generation, RAG) 是一种结合了信息检索和大模型(LLM)的技术,用于构建更强大和准确的问答或生成系统。RAG通过将大模型与外部知识库相结合,可以动态检索相关信息并利用生成模型对查询进行更准确的回答。
RAG在对抗大模型幻觉、高效管理用户本地文件以及数据安全保护等方面具有独到的优势,因而目前基于大模型应用专门做RAG赛道的企业不在少数。
构建一个RAG的核心流程包括索引(indexing)和检索生成(Retrieval and generation)两大块。索引部分主要是数据工程,涉及到各类文档数据的导入(load)、解析(extract)、分割(split)、嵌入(embed)和存储(store)等,检索生成部分主要是基于大模型对用户查询进行检索和生成最终回复。RAG流程如图1所示。
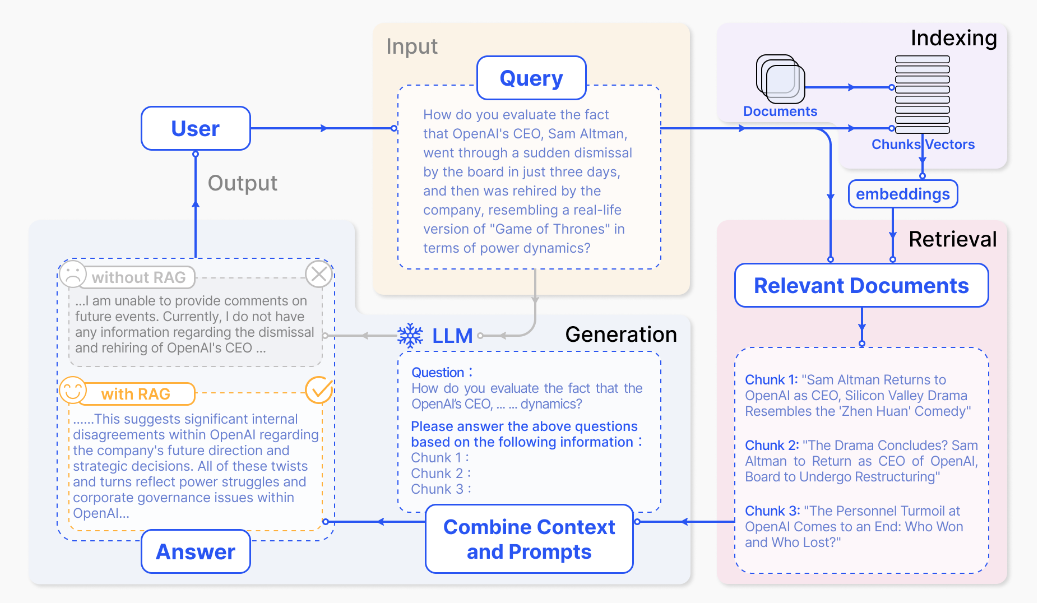
图1 RAG流程
随着大模型几轮浪潮下来,RAG技术本身也经历了多个版本的迭代,主要包括原始RAG版本(Naive RAG)、高级RAG(Advanced RAG)和模块化RAG(Modular RAG)。高级RAG在原始RAG基础上添加了预检索(pre-retrieval)和后检索(post-retrieval)部分,而模块化RAG则是通过模块化设计,可以更容易地集成不同类型的检索器、生成器、知识源、以及融合机制,从而实现更高的灵活性和性能。三种不同的RAG如图2所示。
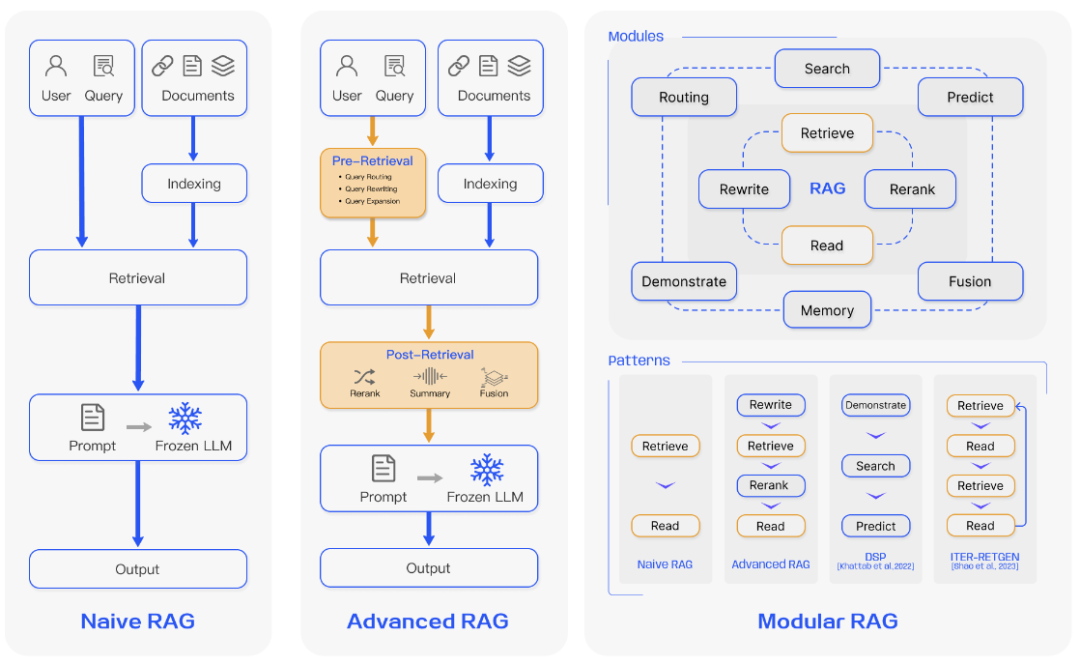
图2 三种RAG
RAG虽然实现逻辑简单,但从工程上来看却是一个非常的系统性工程。在生产环境下,想要实现一套稳定、可靠、精准的RAG系统是一件难度非常大的任务。但从学习者的角度来看,我们可以基于成熟的大模型应用模块快速搭建一个RAG demo。本文笔者以LangChain框架为例,快速搭建一个基于甲状腺癌的医疗RAG demo。
模型方面,笔者直接使用OpenAI的gpt-4o-mini,文本嵌入模型用的是text-embedding-3-large,向量数据库用的是In-Memory,当然也可以用Milvus、FAISS、chroma等向量数据库。
第一步,先做一些预备工作,指定好LLM、嵌入模型和向量数据库。
### setup chatmodel
from langchain_openai import ChatOpenAI
os.environ["OPENAI_API_KEY"] = "你的GPT api"
llm = ChatOpenAI(model="gpt-4o-mini")
# setup embedding model
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# setup vector store
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)第二步,准备好外部文档并导入。笔者准备的是2022年版本的甲状腺癌诊疗规范文件,该规范文件是甲状腺癌和甲状腺结节的诊疗指南。

然后我们通过LangChain的PyPDFLoader导入该PDF文件,并进行分块(chunks)、嵌入和存储到向量库。
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 加载PDF文件
loader = PyPDFLoader("thyroid_cancer.pdf" )
# 提取所有文本
documents = loader.load()
# 使用RecursiveCharacterTextSplitter进行分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个chunk的最大字符数
chunk_overlap=50 # chunk之间的重叠字符数
)
# 分割后的文本chunks
chunks = text_splitter.split_documents(documents)
# 查看分割结果
for i, chunk in enumerate(chunks[:3]): # 仅展示前3个chunk
print(f"Chunk {i+1}:\n{chunk.page_content}\n")
# Index chunks
_ = vector_store.add_documents(documents=chunks)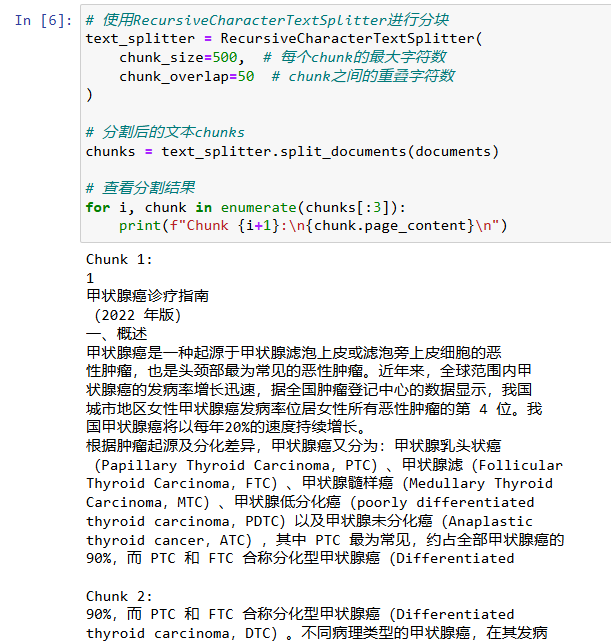
上述部分就是RAG构建流程中的Indexing部分。然后我们再来构建检索和生成模块。
from langchain import hub
from typing_extensions import List, TypedDict
from langchain_core.documents import Document
# 使用LangChain prompt hub的prompt范式
prompt = hub.pull("rlm/rag-prompt")
# 为RAG应用定义state
class State(TypedDict):
question: str
context: List[Document]
answer: str
# 定义检索过程
def retrieve(state: State):
# 基于语义相似性搜索
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
# 定义生成过程
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}最后使用LangGraph将检索和生成步骤整合到一个应用程序中。
from langgraph.graph import START, StateGraph
# Compile application and test
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()这样,一个简单的RAG demo应用就搭建好了。我们来测试一下效果:
response = graph.invoke({"question": "甲状腺癌体征有哪些?"})
print(response["answer"])
最后,我们在LangSmith上也可以追踪每一个查询的实际运行情况:
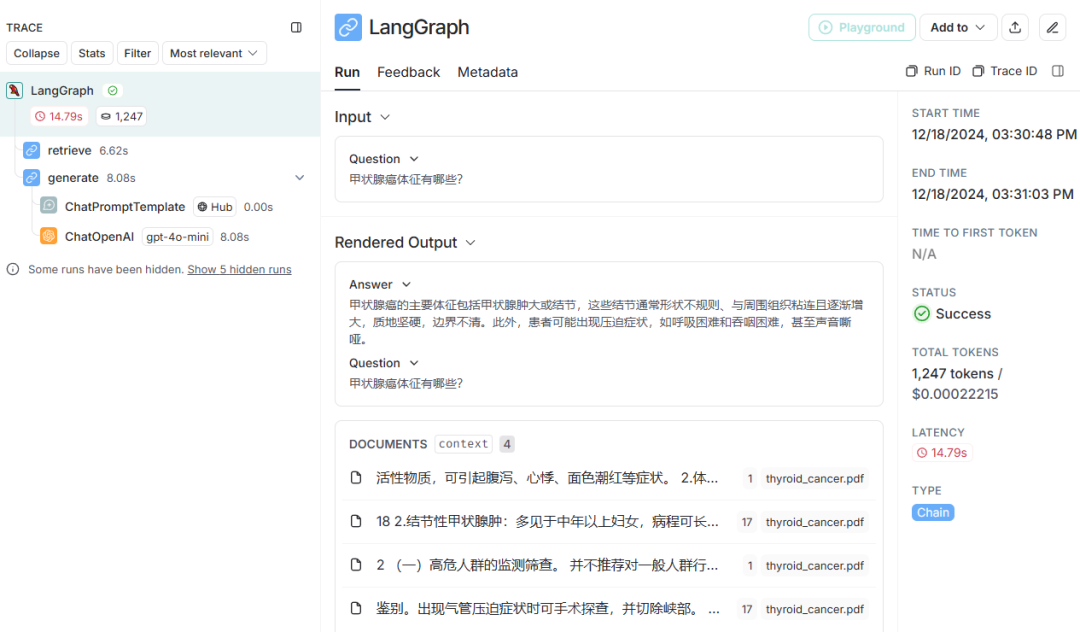
文本完结。
参考资料:
1. https://python.langchain.com/docs/tutorials/rag/
2. Gao Y, Xiong Y, Gao X, et al. Retrieval-augmented generation for large language models: A survey[J]. arXiv preprint arXiv:2312.10997, 2023.
3. 甲状腺癌诊疗指南(2022版)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









