









1、HBase能做什么
a、海量数据的存储 b、准实时查询
2、HBase业务场景
a、交通 b、金融 c、电商 d、移动 等
3、HBase特点
a、容量大 b、面向列 c、多版本
d、稀疏性 e、扩展性 f、高可靠性 g、高性能(LSM数据结构)
4、如何选择合适的版本
考虑因素:稳定性
a、官网版本 b、CDH版本
5、HBase在Hadoop生态系统的定位:
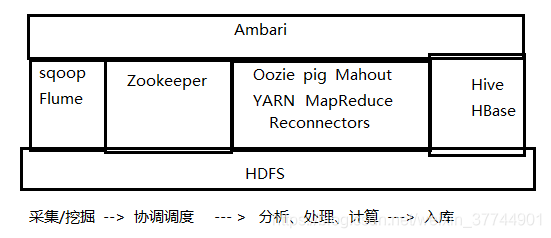
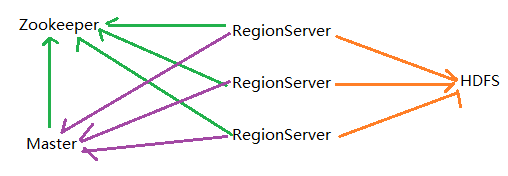
6、HBase体系架构:
两个主要进程 : Master RegisonServer
依赖两个外部服务 : Zookeeper HDFS
7、HBase设计模型
a、列簇 b、Rowkey
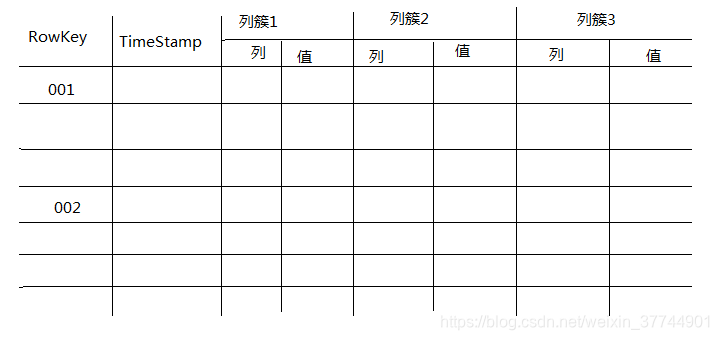
列簇不应该超过5个
每个列簇的列没有限制
列只有植入数据后才存在
列在列簇中是有序的
HBase与关系型数据库的对比:
列动态增加
数据自动切分
高并发读写
不支持条件查询(关系型数据库支持)
8、HBase分布式配置
a、修改HBase.env.sh HBASE_MANAGERS_ZK=false
b、修改hbase-site.xml
c、配置regionServer
HBase的启动命令:
hbase-daemon.sh hbase-daemons.sh
start-hbase.sh stop-hbase.sh
HBase命令:
Create Enable Describe is_disable is_enabled Disable
Drop List Count Put Delete Scan get truncate














 5347
5347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









