






文章目录
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法 I D 3 ID3 ID3、 C 4.5 C4.5 C4.5, 和 C 5.0 C5.0 C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
1.ID3算法
1.1 决策树ID3算法的信息论基础
机器学习算法其实很古老,一个码农经常会不停的敲if, else if, else,其实就已经在用到决策树的思想了。只是你有没有想过,有这么多条件,用哪个条件特征先做if,哪个条件特征后做if比较优呢?怎么准确的定量选择这个标准就是决策树机器学习算法的关键了。1970年代,一个叫昆兰的大牛找到了用信息论中的熵来度量决策树的决策选择过程,方法一出,它的简洁和高效就引起了轰动,昆兰把这个算法叫做 I D 3 ID3 ID3。下面来看看 I D 3 ID3 ID3算法是怎么选择特征的。
首先,我们需要熟悉信息论中熵的概念。熵度量了事物的不确定性,越不确定的事物,它的熵就越大。具体的,随机变量X的熵的表达式如下:
H ( X ) = − ∑ i = 1 n p i l o g p i H(X) = -\sum\limits_{i=1}^{n}p_i logp_i H(X)=−i=1∑npilogpi
其中n代表X的n种不同的离散取值。而 p i p_i pi代表了X取值为i的概率,log为以2或者e为底的对数。举个例子,比如X有2个可能的取值,而这两个取值各为1/2时X的熵最大,此时X具有最大的不确定性。值为 H ( X ) = − ( 1 2 l o g 1 2 + 1 2 l o g 1 2 ) = l o g 2 H(X) = -(\frac{1}{2}log\frac{1}{2} + \frac{1}{2}log\frac{1}{2}) = log2 H(X)=−(21log21+21log21)=log2。如果一个值概率大于1/2,另一个值概率小于1/2,则不确定性减少,对应的熵也会减少。比如一个概率1/3,一个概率2/3,则对应熵为 H ( X ) = − ( 1 3 l o g 1 3 + 2 3 l o g 2 3 ) = l o g 3 − 2 3 l o g 2 < l o g 2 ) H(X) = -(\frac{1}{3}log\frac{1}{3} + \frac{2}{3}log\frac{2}{3}) = log3 - \frac{2}{3}log2 < log2) H(X)=−(31log31+32log32)=log3−32log2<log2)
熟悉了一个变量X的熵,很容易推广到多个个变量的联合熵,这里给出两个变量X和Y的联合熵表达式:
H ( X , Y ) = − ∑ i = 1 n p ( x i , y i ) l o g p ( x i , y i ) H(X,Y) = -\sum\limits_{i=1}^{n}p(x_i,y_i)logp(x_i,y_i) H(X,Y)=−i=1∑np(xi,yi)logp(xi,yi)
有了联合熵,又可以得到条件熵的表达式H(X|Y),条件熵类似于条件概率,它度量了我们的X在知道Y以后剩下的不确定性。表达式如下:
H ( X ∣ Y ) = − ∑ i = 1 n p ( x i , y i ) l o g p ( x i ∣ y i ) = ∑ j = 1 n p ( y j ) H ( X ∣ y j ) H(X|Y) = -\sum\limits_{i=1}^{n}p(x_i,y_i)logp(x_i|y_i) = \sum\limits_{j=1}^{n}p(y_j)H(X|y_j) H(X∣Y)=−i=1∑np(xi,yi)logp(xi∣yi)=j=1∑np(yj)H(X∣yj)
好吧,绕了一大圈,终于可以重新回到ID3算法了。我们刚才提到H(X)度量了X的不确定性,条件熵H(X|Y)度量了我们在知道Y以后X剩下的不确定性,那么 H ( X ) − H ( X ∣ Y ) H(X)-H(X|Y) H(X)−H(X∣Y)呢?从上面的描述大家可以看出,它度量了X在知道Y以后不确定性减少程度,这个度量我们在信息论中称为互信息,,记为 I ( X , Y ) I(X,Y) I(X,Y)。在决策树 I D 3 ID3 ID3 算法中叫做信息增益。 I D 3 ID3 ID3 算法就是用信息增益来判断当前节点应该用什么特征来构建决策树。信息增益大,则越适合用来分类。
上面一堆概念,大家估计比较晕,用下面这个图很容易明白他们的关系。左边的椭圆代表 H ( X ) H(X) H(X),右边的椭圆代表 H ( Y ) H(Y) H(Y),中间重合的部分就是我们的互信息或者信息增益 I ( X , Y ) I(X,Y) I(X,Y) , 左边的椭圆去掉重合部分就是 H ( X ∣ Y ) H(X|Y) H(X∣Y) ,右边的椭圆去掉重合部分就是 H ( Y ∣ X ) H(Y|X) H(Y∣X)。两个椭圆的并就是 H ( X , Y ) H(X,Y) H(X,Y)。

1.2 决策树ID3算法的思路
上面提到ID3算法就是用信息增益大小来判断当前节点应该用什么特征来构建决策树,用计算出的信息增益最大的特征来建立决策树的当前节点。这里我们举一个信息增益计算的具体的例子。比如我们有15个样本D,输出为0或者1。其中有9个输出为0, 6个输出为1。 样本中有个特征A,取值为A1,A2和A3。在取值为A1的样本的输出中,有3个输出为1, 2个输出为0,取值为A2的样本输出中,2个输出为1,3个输出为0, 在取值为A3的样本中,4个输出为1,1个输出为0.
样本D的熵为: H ( D ) = − ( 9 15 l o g 2 9 15 + 6 15 l o g 2 6 15 ) = 0.971 H(D) = -(\frac{9}{15}log_2\frac{9}{15} + \frac{6}{15}log_2\frac{6}{15}) = 0.971 H(D)=−(159log2159+156log2156)=0.971
样本D在特征下的条件熵为: H ( D ∣ A ) = 5 15 H ( D 1 ) + 5 15 H ( D 2 ) + 5 15 H ( D 3 ) H(D|A) = \frac{5}{15}H(D1) + \frac{5}{15}H(D2) + \frac{5}{15}H(D3) H(D∣A)=155H(D1)+155H(D2)+155H(D3)
= − 5 15 ( 3 5 l o g 2 3 5 + 2 5 l o g 2 2 5 ) − 5 15 ( 2 5 l o g 2 2 5 + 3 5 l o g 2 3 5 ) − 5 15 ( 4 5 l o g 2 4 5 + 1 5 l o g 2 1 5 ) = 0.888 = -\frac{5}{15}(\frac{3}{5}log_2\frac{3}{5} + \frac{2}{5}log_2\frac{2}{5}) - \frac{5}{15}(\frac{2}{5}log_2\frac{2}{5} + \frac{3}{5}log_2\frac{3}{5}) -\frac{5}{15}(\frac{4}{5}log_2\frac{4}{5} + \frac{1}{5}log_2\frac{1}{5}) = 0.888 =−155(53log253+52log252)−155(52log252+53log253)−155(54log254+51log251)=0.888
对应的信息增益为 I ( D , A ) = H ( D ) − H ( D ∣ A ) = 0.083 I(D,A) = H(D) - H(D|A) = 0.083 I(D,A)=H(D)−H(D∣A)=0.083
下面我们看看具体算法过程大概是怎么样的。
输入的是 m m m个样本,样本输出集合为 D D D,每个样本有 n n n个离散特征,特征集合即为 A A A,输出为决策树 T T T。
算法的过程为:
- 初始化信息增益的阈值 ϵ ϵ ϵ
- 判断样本是否为同一类输出 D i Di Di,如果是则返回单节点树 T T T。标记类别为 D i D_i Di
- 判断特征是否为空,如果是则返回单节点树T,标记类别为样本中输出类别D实例数最多的类别。
- 计算 A A A中的各个特征(一共 n n n个)对输出 D D D的信息增益,选择信息增益最大的特征 A g Ag Ag
- 如果Ag的信息增益小于阈值 ϵ ϵ ϵ,则返回单节点树 T T T,标记类别为样本中输出类别 D D D实例数最多的类别。
- 否则,按特征 A g Ag Ag的不同取值Agi将对应的样本输出 D D D分成不同的类别 D i Di Di。每个类别产生一个子节点。对应特征值为 A g i Ag_i Agi。返回增加了节点的数T。
- 对于所有的子节点,令 D = D i , A = A − A g D=Di,A=A−{Ag} D=Di,A=A−Ag递归调用2-6步,得到子树 T i T_i Ti并返回。
1.3 决策树ID3算法的不足
I D 3 ID3 ID3算法虽然提出了新思路,但是还是有很多值得改进的地方。
- I D 3 ID3 ID3没有考虑连续特征,比如长度,密度都是连续值,无法在 I D 3 ID3 ID3运用。这大大限制了 I D 3 ID3 ID3的用途。
- I D 3 ID3 ID3采用信息增益大的特征优先建立决策树的节点。很快就被人发现,在相同条件下,取值比较多的特征比取值少的特征信息增益大。比如一个变量有2个值,各为1/2,另一个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值的比取2个值的信息增益大。如果校正这个问题呢?
- I D 3 ID3 ID3算法对于缺失值的情况没有做考虑
- 没有考虑过拟合的问题
I D 3 ID3 ID3算法的作者昆兰基于上述不足,对 I D 3 ID3 ID3算法做了改进,这就是 C 4.5 C4.5 C4.5算法。
2. C4.5算法
2.1 决策树C4.5算法的改进
ID3算法有四个主要的不足,一是不能处理连续特征,第二个就是用信息增益作为标准容易偏向于取值较多的特征,最后两个是缺失值处理的问和过拟合问题。 C 4.5 C4.5 C4.5算法中改进了上述4个问题。
对于第一个问题,不能处理连续特征, C 4.5 C4.5 C4.5的思路是将连续的特征离散化。比如 m m m个样本的连续特征 A A A有 m m m个,从小到大排列为 a 1 , a 2 , . . . , a m a1,a2,...,am a1,a2,...,am,则 C 4.5 C4.5 C4.5取相邻两样本值的中位数,一共取得 m − 1 m-1 m−1个划分点,其中第 i i i个划分点 T i T_i Ti表示为: T i = a i + a i + 1 2 T_i = \frac{a_i+a_{i+1}}{2} Ti=2ai+ai+1。对于这 m − 1 m-1 m−1个点,分别计算以该点作为二元分类点时的信息增益。选择信息增益最大的点作为该连续特征的二元离散分类点。比如取到的增益最大的点为 a t at at,则小于 a t at at的值为类别1,大于at的值为类别2,这样我们就做到了连续特征的离散化。要注意的是,与离散属性不同的是,如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程。
对于第二个问题,信息增益作为标准容易偏向于取值较多的特征的问题。我们引入一个信息增益比的变量 I R ( X , Y ) IR(X,Y) IR(X,Y),它是信息增益和特征熵的比值。表达式如下:
I R ( D , A ) = I ( A , D ) H A ( D ) I_R(D,A) = \frac{I(A,D)}{H_A(D)} IR(D,A)=HA(D)I(A,D)
其中D为样本特征输出的集合,A为样本特征,对于特征熵 H A ( D ) H_A(D) HA(D), 表达式如下:
H A ( D ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ l o g 2 ∣ D i ∣ ∣ D ∣ H_A(D) = -\sum\limits_{i=1}^{n}\frac{|D_i|}{|D|}log_2\frac{|D_i|}{|D|} HA(D)=−i=1∑n∣D∣∣Di∣log2∣D∣∣Di∣
其中n为特征A的类别数, D i Di Di为特征A的第i个取值对应的样本个数。 D D D为样本个数。
特征数越多的特征对应的特征熵越大,它作为分母,可以校正信息增益容易偏向于取值较多的特征的问题。
对于第三个缺失值处理的问题,主要需要解决的是两个问题,一是在样本某些特征缺失的情况下选择划分的属性,二是选定了划分属性,对于在该属性上缺失特征的样本的处理。
- 对于第一个子问题,对于某一个有缺失特征值的特征 A A A。 C 4.5 C4.5 C4.5的思路是将数据分成两部分,对每个样本设置一个权重(初始可以都为1),然后划分数据,一部分是有特征值 A A A的数据 D 1 D1 D1,另一部分是没有特征 A A A的数据 D 2 D2 D2. 然后对于没有缺失特征A的数据集 D 1 D1 D1来和对应的A特征的各个特征值一起计算加权重后的信息增益比,最后乘上一个系数,这个系数是无特征 A A A缺失的样本加权后所占加权总样本的比例。
- 对于第二个子问题,可以将缺失特征的样本同时划分入所有的子节点,不过将该样本的权重按各个子节点样本的数量比例来分配。比如缺失特征 A A A的样本 a a a之前权重为1,特征 A A A有3个特征值 A 1 , A 2 , A 3 A1,A2,A3 A1,A2,A3。 3个特征值对应的无缺失A特征的样本个数为2,3,4.则a同时划分入 A 1 , A 2 , A 3 A1,A2,A3 A1,A2,A3。对应权重调节为2/9,3/9, 4/9。
对于第4个问题, C 4.5 C4.5 C4.5引入了正则化系数进行初步的剪枝。
2.2 决策树C4.5算法的不足与思考
C 4.5 C4.5 C4.5虽然改进或者改善了 I D 3 ID3 ID3算法的几个主要的问题,仍然有优化的空间。
- 由于决策树算法非常容易过拟合,因此对于生成的决策树必须要进行剪枝。剪枝的算法有非常多, C 4.5 C4.5 C4.5的剪枝方法有优化的空间。思路主要是两种,一种是预剪枝,即在生成决策树的时候就决定是否剪枝。另一个是后剪枝,即先生成决策树,再通过交叉验证来剪枝。后面在下篇讲 C A R T CART CART树的时候我们会专门讲决策树的减枝思路,主要采用的是后剪枝加上交叉验证选择最合适的决策树。
- C 4.5 C4.5 C4.5生成的是多叉树,即一个父节点可以有多个节点。很多时候,在计算机中二叉树模型会比多叉树运算效率高。如果采用二叉树,可以提高效率。
- C 4.5 C4.5 C4.5只能用于分类,如果能将决策树用于回归的话可以扩大它的使用范围。
- C 4.5 C4.5 C4.5由于使用了熵模型,里面有大量的耗时的对数运算,如果是连续值还有大量的排序运算。如果能够加以模型简化可以减少运算强度但又不牺牲太多准确性的话,那就更好了。
3. CART分类树算法
3.1 CART分类树算法的最优特征选择方法
在 I D 3 ID3 ID3算法中我们使用了信息增益来选择特征,信息增益大的优先选择。在 C 4.5 C4.5 C4.5算法中,采用了信息增益比来选择特征,以减少信息增益容易选择特征值多的特征的问题。但是无论是 I D 3 ID3 ID3还是 C 4.5 C4.5 C4.5,都是基于信息论的熵模型的,这里面会涉及大量的对数运算。 C A R T CART CART分类树算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。这和信息增益(比)是相反的。
具体的,在分类问题中,假设有 K K K个类别,第k个类别的概率为 p k p_k pk, 则基尼系数的表达式为:
G i n i ( p ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 Gini(p) = \sum\limits_{k=1}^{K}p_k(1-p_k) = 1- \sum\limits_{k=1}^{K}p_k^2 Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
如果是二类分类问题,计算就更加简单了,如果属于第一个样本输出的概率是p,则基尼系数的表达式为:
G i n i ( p ) = 2 p / ( 1 − p ) Gini(p)=2p/(1−p) Gini(p)=2p/(1−p)
对于个给定的样本D,假设有K个类别, 第 k k k个类别的数量为 C k C_k Ck,则样本 D D D的基尼系数表达式为:
G i n i ( D ) = 1 − ∑ k = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 Gini(D) = 1-\sum\limits_{k=1}^{K}(\frac{|C_k|}{|D|})^2 Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
特别的,对于样本 D D D,如果根据特征 A A A的某个值 a a a,把 D D D分成 D 1 D1 D1和 D 2 D2 D2两部分,则在特征 A A A的条件下, D D D的基尼系数表达式为:
G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini(D,A) = \frac{|D_1|}{|D|}Gini(D_1) + \frac{|D_2|}{|D|}Gini(D_2) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
可以比较下基尼系数表达式和熵模型的表达式,二次运算是不是比对数简单很多?尤其是二类分类的计算,更加简单。但是简单归简单,和熵模型的度量方式比,基尼系数对应的误差有多大呢?对于二类分类,基尼系数和熵之半的曲线如下:
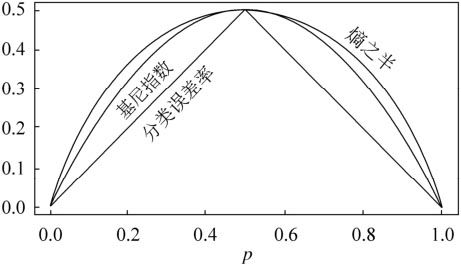
从上图可以看出,基尼系数和熵之半的曲线非常接近,仅仅在45度角附近误差稍大。因此,基尼系数可以做为熵模型的一个近似替代。而 C A R T CART CART分类树算法就是使用的基尼系数来选择决策树的特征。同时,为了进一步简化, C A R T CART CART分类树算法每次仅仅对某个特征的值进行二分,而不是多分,这样 C A R T CART CART分类树算法建立起来的是二叉树,而不是多叉树。
3.2 CART分类树算法对于连续特征和离散特征处理的改进
对于 C A R T CART CART分类树连续值的处理问题,其思想和 C 4.5 C4.5 C4.5是相同的,都是将连续的特征离散化。唯一的区别在于在选择划分点时的度量方式不同, C 4.5 C4.5 C4.5使用的是信息增益,则 C A R T CART CART分类树使用的是基尼系数。
具体的思路如下,比如m个样本的连续特征 A A A有 m m m个,从小到大排列为 a 1 , a 2 , . . . , a m a1,a2,...,am a1,a2,...,am,则 C A R T CART CART算法取相邻两样本值的中位数,一共取得 m − 1 m-1 m−1个划分点,其中第 i i i 个划分点 T i T_i Ti 表示为: T i = a i + a i + 1 2 T_i = \frac{a_i+a_{i+1}}{2} Ti=2ai+ai+1。对于这 m − 1 m-1 m−1 个点,分别计算以该点作为二元分类点时的基尼系数。选择基尼系数最小的点作为该连续特征的二元离散分类点。比如取到的基尼系数最小的点为 a t at at ,则小于 a t at at 的值为类别1,大于at的值为类别2,这样我们就做到了连续特征的离散化。要注意的是,与离散属性不同的是,如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程。
对于 C A R T CART CART分类树离散值的处理问题,采用的思路是不停的二分离散特征。
回忆下 I D 3 ID3 ID3或者 C 4.5 C4.5 C4.5,如果某个特征A被选取建立决策树节点,如果它有 A 1 , A 2 , A 3 A1,A2,A3 A1,A2,A3三种类别,我们会在决策树上一下建立一个三叉的节点。这样导致决策树是多叉树。但是 C A R T CART CART分类树使用的方法不同,他采用的是不停的二分,还是这个例子,CART分类树会考虑把 A A A分成 { A 1 } \{A1\} {A1}和 { A 2 , A 3 } \{A2,A3\} {A2,A3}, { A 2 } \{A2\} {A2}和 { A 1 , A 3 } \{A1,A3\} {A1,A3}, { A 3 } \{A3\} {A3}和 { A 1 , A 2 } \{A1,A2\} {A1,A2}三种情况,找到基尼系数最小的组合,比如 { A 2 } \{A2\} {A2}和 { A 1 , A 3 } \{A1,A3\} {A1,A3},然后建立二叉树节点,一个节点是 A 2 A2 A2对应的样本,另一个节点是 { A 1 , A 3 } \{A1,A3\} {A1,A3}对应的节点。从描述可以看出,如果离散特征 A A A有 n n n个取值,则可能的组合有 n ( n − 1 ) / 2 n(n-1)/2 n(n−1)/2种。同时,由于这次没有把特征A的取值完全分开,后面我们还有机会在子节点继续选择到特征 A A A 来划分 A 1 A1 A1 和 A 3 A3 A3 。这和 I D 3 ID3 ID3 或者 C 4.5 C4.5 C4.5 不同,在 I D 3 ID3 ID3 或者 C 4.5 C4.5 C4.5 的一棵子树中,离散特征只会参与一次节点的建立。
3.3 CART分类树建立算法的具体流程
下面是 C A R T CART CART分类树建立算法的具体流程:
算法输入是训练集
D
D
D,基尼系数的阈值,样本个数阈值。
输出是决策树T。
我们的算法从根节点开始,用训练集递归的建立
C
A
R
T
CART
CART树。
- 对于当前节点的数据集为 D D D,如果样本个数小于阈值或者没有特征,则返回决策子树,当前节点停止递归。
- 计算样本集D的基尼系数,如果基尼系数小于阈值,则返回决策树子树,当前节点停止递归。
- 计算当前节点现有的各个特征的各个特征值对数据集 D D D的基尼系数,对于离散值和连续值的处理方法和基尼系数的计算见第二节。缺失值的处理方法和上篇的C4.5算法里描述的相同。
- 在计算出来的各个特征的各个特征值对数据集 D D D的基尼系数中,选择基尼系数最小的特征 A A A和对应的特征值 a a a。根据这个最优特征和最优特征值,把数据集划分成两部分 D 1 D1 D1和 D 2 D2 D2,同时建立当前节点的左右节点,做节点的数据集 D D D为 D 1 D1 D1,右节点的数据集 D D D为 D 2 D2 D2.
- 对左右的子节点递归的调用1-4步,生成决策树。
对于生成的决策树做预测的时候,假如测试集里的样本 A A A落到了某个叶子节点,而节点里有多个训练样本。则对于 A A A的类别预测采用的是这个叶子节点里概率最大的类别。
3.4 CART回归树建立算法
C A R T CART CART回归树和 C A R T CART CART分类树的建立算法大部分是类似的,所以这里我们只讨论 C A R T CART CART回归树和 C A R T CART CART分类树的建立算法不同的地方。
首先,我们要明白,什么是回归树,什么是分类树。两者的区别在于样本输出,如果样本输出是离散值,那么这是一颗分类树。如果果样本输出是连续值,那么那么这是一颗回归树。
除了概念的不同, C A R T CART CART回归树和 C A R T CART CART分类树的建立和预测的区别主要有下面两点:
- 连续值的处理方法不同
- 决策树建立后做预测的方式不同。
对于连续值的处理,我们知道 C A R T CART CART分类树采用的是用基尼系数的大小来度量特征的各个划分点的优劣情况。这比较适合分类模型,但是对于回归模型,我们使用了常见的均方差的度量方式, C A R T CART CART回归树的度量目标是,对于任意划分特征 A A A,对应的任意划分点 s s s两边划分成的数据集 D 1 D1 D1和 D 2 D2 D2,求出使 D 1 D1 D1和 D 2 D2 D2各自集合的均方差最小,同时 D 1 D1 D1和 D 2 D2 D2的均方差之和最小所对应的特征和特征值划分点。表达式为:
m i n [ m i n ∑ x i ∈ D 1 ( A , s ) ( y i − c 1 ) 2 + m i n ∑ x i ∈ D 2 ( A , s ) ( y i − c 2 ) 2 ] min\Bigg[min\sum\limits_{x_i \in D_1(A,s)}(y_i - c_1)^2 + min\sum\limits_{x_i \in D_2(A,s)}(y_i - c_2)^2\Bigg] min[minxi∈D1(A,s)∑(yi−c1)2+minxi∈D2(A,s)∑(yi−c2)2]
其中, c 1 c1 c1为 D 1 D1 D1数据集的样本输出均值, c 2 c2 c2为 D 2 D2 D2数据集的样本输出均值。
对于决策树建立后做预测的方式,上面讲到了 C A R T CART CART分类树采用叶子节点里概率最大的类别作为当前节点的预测类别。而回归树输出不是类别,它采用的是用最终叶子的均值或者中位数来预测输出结果。
除了上面提到了以外, C A R T CART CART回归树和 C A R T CART CART分类树的建立算法和预测没有什么区别。
3.5 CART树算法的剪枝
C A R T CART CART回归树和 C A R T CART CART分类树的剪枝策略除了在度量损失的时候一个使用均方差,一个使用基尼系数,算法基本完全一样,这里我们一起来讲。
由于决策时算法很容易对训练集过拟合,而导致泛化能力差,为了解决这个问题,我们需要对 C A R T CART CART树进行剪枝,即类似于线性回归的正则化,来增加决策树的返回能力。但是,有很多的剪枝方法,我们应该这么选择呢? C A R T CART CART采用的办法是后剪枝法,即先生成决策树,然后产生所有可能的剪枝后的 C A R T CART CART树,然后使用交叉验证来检验各种剪枝的效果,选择泛化能力最好的剪枝策略。
也就是说, C A R T CART CART树的剪枝算法可以概括为两步,第一步是从原始决策树生成各种剪枝效果的决策树,第二部是用交叉验证来检验剪枝后的预测能力,选择泛化预测能力最好的剪枝后的数作为最终的CART树。
首先我们看看剪枝的损失函数度量,在剪枝的过程中,对于任意的一刻子树T,其损失函数为:
C α ( T t ) = C ( T t ) + α ∣ T t ∣ C_{\alpha}(T_t) = C(T_t) + \alpha |T_t| Cα(Tt)=C(Tt)+α∣Tt∣
其中, α α α为正则化参数,这和线性回归的正则化一样。 C ( T t ) C(Tt) C(Tt)为训练数据的预测误差,分类树是用基尼系数度量,回归树是均方差度量。 ∣ T t |Tt ∣Tt|$是子树T的叶子节点的数量。
当 α = 0 α=0 α=0时,即没有正则化,原始的生成的 C A R T CART CART树即为最优子树。当 α = ∞ α=∞ α=∞时,即正则化强度达到最大,此时由原始的生成的CART树的根节点组成的单节点树为最优子树。当然,这是两种极端情况。一般来说, α α α越大,则剪枝剪的越厉害,生成的最优子树相比原生决策树就越偏小。对于固定的 α α α,一定存在使损失函数 C α ( T ) Cα(T) Cα(T)最小的唯一子树。
看过剪枝的损失函数度量后,我们再来看看剪枝的思路,对于位于节点t的任意一颗子树Tt,如果没有剪枝,它的损失是
C
α
(
T
t
)
=
C
(
T
t
)
+
α
∣
T
t
∣
C_{\alpha}(T_t) = C(T_t) + \alpha |T_t|
Cα(Tt)=C(Tt)+α∣Tt∣
如果将其剪掉,仅仅保留根节点,则损失是
C
α
(
T
)
=
C
(
T
)
+
α
C_{\alpha}(T) = C(T) + \alpha
Cα(T)=C(T)+α
当α=0或者α很小时,
C
α
(
T
t
)
<
C
α
(
T
)
C_{\alpha}(T_t) < C_{\alpha}(T)
Cα(Tt)<Cα(T)
当α增大到一定的程度时,
C
α
(
T
)
=
C
(
T
)
+
α
C_{\alpha}(T) = C(T) + \alpha
Cα(T)=C(T)+α
当α继续增大时不等式反向,也就是说,如果满足下式:
α
=
C
(
T
)
−
C
(
T
t
)
∣
T
t
∣
−
1
\alpha = \frac{C(T)-C(T_t)}{|T_t|-1}
α=∣Tt∣−1C(T)−C(Tt)
T t Tt Tt和 T T T有相同的损失函数,但是T节点更少,因此可以对子树 T t Tt Tt进行剪枝,也就是将它的子节点全部剪掉,变为一个叶子节点 T T T。
最后我们看看 C A R T CART CART树的交叉验证策略。上面我们讲到,可以计算出每个子树是否剪枝的阈值 α α α,如果我们把所有的节点是否剪枝的值 α α α都计算出来,然后分别针对不同的 α α α所对应的剪枝后的最优子树做交叉验证。这样就可以选择一个最好的 α α α,有了这个 α α α,我们就可以用对应的最优子树作为最终结果。
好了,有了上面的思路,我们现在来看看 C A R T CART CART树的剪枝算法。
输入是 C A R T CART CART树建立算法得到的原始决策树 T T T。
输出是最优决策子树 T α Tα Tα。
算法过程如下:
- 初始化 α m i n = ∞ \alpha_{min}= \infty αmin=∞, 最优子树集合 ω = T ω={T} ω=T。
- 从叶子节点开始自下而上计算各内部节点t的训练误差损失函数 C α ( T t ) Cα(Tt) Cα(Tt)(回归树为均方差,分类树为基尼系数), 叶子节点数|Tt|,以及正则化阈值 α = m i n { C ( T ) − C ( T t ) ∣ T t ∣ − 1 , α m i n } \alpha= min\{\frac{C(T)-C(T_t)}{|T_t|-1}, \alpha_{min}\} α=min{∣Tt∣−1C(T)−C(Tt),αmin}, 更新 α m i n = α \alpha_{min}= \alpha αmin=α
- 得到所有节点的α值的集合M。
- 从M中选择最大的值αk,自上而下的访问子树t的内部节点,如果 C ( T ) − C ( T t ) ∣ T t ∣ − 1 ≤ α k \frac{C(T)-C(T_t)}{|T_t|-1} \leq \alpha_k ∣Tt∣−1C(T)−C(Tt)≤αk时,进行剪枝。并决定叶节点t的值。如果是分类树,则是概率最高的类别,如果是回归树,则是所有样本输出的均值。这样得到αk对应的最优子树Tk
- 最优子树集合 ω = ω ∪ T k M = M − { α k } \omega=\omega \cup T_kM= M -\{\alpha_k\} ω=ω∪TkM=M−{αk}。
- 如果M不为空,则回到步骤4。否则就已经得到了所有的可选最优子树集合 ω ω ω.
- 采用交叉验证在 ω ω ω选择最优子树 T α T_α Tα
4. 决策树算法小结
C A R T CART CART算法相比 C 4.5 C4.5 C4.5算法的分类方法,采用了简化的二叉树模型,同时特征选择采用了近似的基尼系数来简化计算。当然 C A R T CART CART树最大的好处是还可以做回归模型,这个 C 4.5 C4.5 C4.5没有。下表给出了 I D 3 ID3 ID3, C 4.5 C4.5 C4.5和 C A R T CART CART的一个比较总结。
| 算法 | 支持模型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处理 | 剪枝 |
|---|---|---|---|---|---|---|
| ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 |
| C4.5 | 分类 | 多叉树 | 信息增益比 | 支持 | 支持 | 支持 |
| CART | 分类,回归 | 二叉树 | 基尼系数,均方差 | 支持 | 支持 | 支持 |
这里我们不再纠结于
I
D
3
ID3
ID3,
C
4.5
C4.5
C4.5 和
C
A
R
T
CART
CART ,我们来看看决策树算法作为一个大类别的分类回归算法的优缺点。这部分总结于scikit-learn的英文文档。
决策树算法的优点:
- 简单直观,生成的决策树很直观。
- 基本不需要预处理,不需要提前归一化,处理缺失值。
- 使用决策树预测的代价是 O ( l o g 2 m ) O(log2m) O(log2m)。 m为样本数。
- 既可以处理离散值也可以处理连续值。很多算法只是专注于离散值或者连续值。
- 可以处理多维度输出的分类问题。
- 相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的解释
- 可以交叉验证的剪枝来选择模型,从而提高泛化能力。
- 对于异常点的容错能力好,健壮性高。
决策树算法的缺点:
- 决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。
- 决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。
- 寻找最优的决策树是一个NP难的问题,我们一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。
- 有些比较复杂的关系,决策树很难学习,比如异或。这个就没有办法了,一般这种关系可以换神经网络分类方法来解决。
- 如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
5. scikit-learn决策树算法类库介绍
scikit-learn决策树算法类库内部实现是使用了调优过的
C
A
R
T
CART
CART树算法,既可以做分类,又可以做回归。分类决策树的类对应的是DecisionTreeClassifier,而回归决策树的类对应的是DecisionTreeRegressor。两者的参数定义几乎完全相同,但是意义不全相同。下面就对DecisionTreeClassifier和DecisionTreeRegressor的重要参数做一个总结,重点比较两者参数使用的不同点和调参的注意点。
DecisionTreeClassifier和DecisionTreeClassifier重要参数调参注意点
为了便于比较,这里我们用表格的形式对DecisionTreeClassifier和DecisionTreeRegressor重要参数要点做一个比较。
| 参数 | DecisionTreeClassifier | DecisionTreeRegressor |
|---|---|---|
特征选择标准criterion | 可以使用"gini"或者"entropy",前者代表基尼系数,后者代表信息增益。一般说使用默认的基尼系数"gini"就可以了,即
C
A
R
T
CART
CART算法。除非你更喜欢类似
I
D
3
ID3
ID3,
C
4.5
C4.5
C4.5的最优特征选择方法。 | 可以使用"mse"或者"mae",前者是均方差,后者是和均值之差的绝对值之和。推荐使用默认的"mse"。一般来说"mse"比"mae"更加精确。除非你想比较二个参数的效果的不同之处。 |
特征划分点选择标准splitter | 可以使用"best"或者"random"。前者在特征的所有划分点中找出最优的划分点。后者是随机的在部分划分点中找局部最优的划分点。默认的"best"适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐"random" | |
划分时考虑的最大特征数max_features | 可以使用很多种类型的值,默认是"None",意味着划分时考虑所有的特征数;如果是"log2"意味着划分时最多考虑
l
o
g
2
N
l
o
g
2
N
log2Nlog2N
log2Nlog2N个特征;如果是"sqrt"或者"auto"``意味着划分时最多考虑$N−√N$个特征。如果是整数,代表考虑的特征绝对数。如果是浮点数,代表考虑特征百分比,即考虑(百分比xN)取整后的特征数。其中$N$为样本总特征数。一般来说,如果样本特征数不多,比如小于50,我们用默认的"None"```就可以了,如果特征数非常多,我们可以灵活使用刚才描述的其他取值来控制划分时考虑的最大特征数,以控制决策树的生成时间。 | |
决策树最大深max_depth | 决策树的最大深度,默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。 | |
内部节点再划分所需最小样本数min_samples_split | 这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。我之前的一个项目例子,有大概10万样本,建立决策树时,我选择了min_samples_split=10。可以作为参考。 | |
叶子节点最少样本数min_samples_leaf | 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。之前的10万样本项目使用min_samples_leaf的值为5,仅供参考。 | |
叶子节点最小的样本权重和min_weight_fraction\_leaf | 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。 | |
最大叶子节点数max_leaf_nodes | 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。 | |
类别权重class_weight | 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,或者用“balanced”,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。当然,如果你的样本类别分布没有明显的偏倚,则可以不管这个参数,选择默认的"None" | 不适用于回归树 |
节点划分最小不纯度min_impurity_split | 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。 | |
数据是否预排序presort | 这个值是布尔值,默认是False不排序。一般来说,如果样本量少或者限制了一个深度很小的决策树,设置为True可以让划分点选择更加快,决策树建立的更加快。如果样本量太大的话,反而没有什么好处。问题是样本量少的时候,我速度本来就不慢。所以这个值一般懒得理它就可以了。 |
除了这些参数要注意以外,其他在调参时的注意点有:
- 当样本少数量但是样本特征非常多的时候,决策树很容易过拟合,一般来说,样本数比特征数多一些会比较容易建立健壮的模型
- 如果样本数量少但是样本特征非常多,在拟合决策树模型前,推荐先做维度规约,比如主成分分析(PCA),特征选择(Losso)或者独立成分分析(ICA)。这样特征的维度会大大减小。再来拟合决策树模型效果会好。
- 推荐多用决策树的可视化(下节会讲),同时先限制决策树的深度(比如最多3层),这样可以先观察下生成的决策树里数据的初步拟合情况,然后再决定是否要增加深度。
- 在训练模型先,注意观察样本的类别情况(主要指分类树),如果类别分布非常不均匀,就要考虑用class_weight来限制模型过于偏向样本多的类别。
- 决策树的数组使用的是numpy的float32类型,如果训练数据不是这样的格式,算法会先做copy再运行。
- 如果输入的样本矩阵是稀疏的,推荐在拟合前调用
csc_matrix稀疏化,在预测前调用csr_matrix稀疏化。
6. scikit-learn决策树结果的可视化
决策树可视化化可以方便我们直观的观察模型,以及发现模型中的问题。这里介绍下scikit-learn中决策树的可视化方法。
6.1 决策树可视化环境搭建
scikit-learn中决策树的可视化一般需要安装graphviz。主要包括graphviz的安装和python的graphviz插件的安装。
- 第一步是安装graphviz。下载地址在:http://www.graphviz.org/ 。如果你是linux,可以用apt-get或者yum的方法安装。如果是windows,就在官网下载msi文件安装。无论是linux还是windows,装完后都要设置环境变量,将graphviz的bin目录加到PATH。
- 第二步是安装python插件graphviz: pip install graphviz
- 第三步是安装python插件pydotplus。这个没有什么好说的: pip installpydotplus
6.2 决策树可视化的三种方法
这里我们有一个例子讲解决策树可视化。
首先载入类库:
from sklearn.datasets import load_iris
from sklearn import tree
import sys
import os
接着载入sciki-learn的自带数据,有决策树拟合,得到模型:
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target)
现在可以将模型存入dot文件iris.dot。
with open("iris.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file=f)
这时候我们有3种可视化方法,第一种是用graphviz的dot命令生成决策树的可视化文件,敲完这个命令后当前目录就可以看到决策树的可视化文件iris.pdf.打开可以看到决策树的模型图。
#
注意,这个命令在命令行执行
dot -Tpdf iris.dot -o iris.pdf
第二种方法是用pydotplus生成iris.pdf。这样就不用再命令行去专门生成pdf文件了。
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")
第三种办法是个人比较推荐的做法,因为这样可以直接把图产生在ipython的notebook。代码如下:
from IPython.display import Image
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
在ipython的notebook生成的图如下:
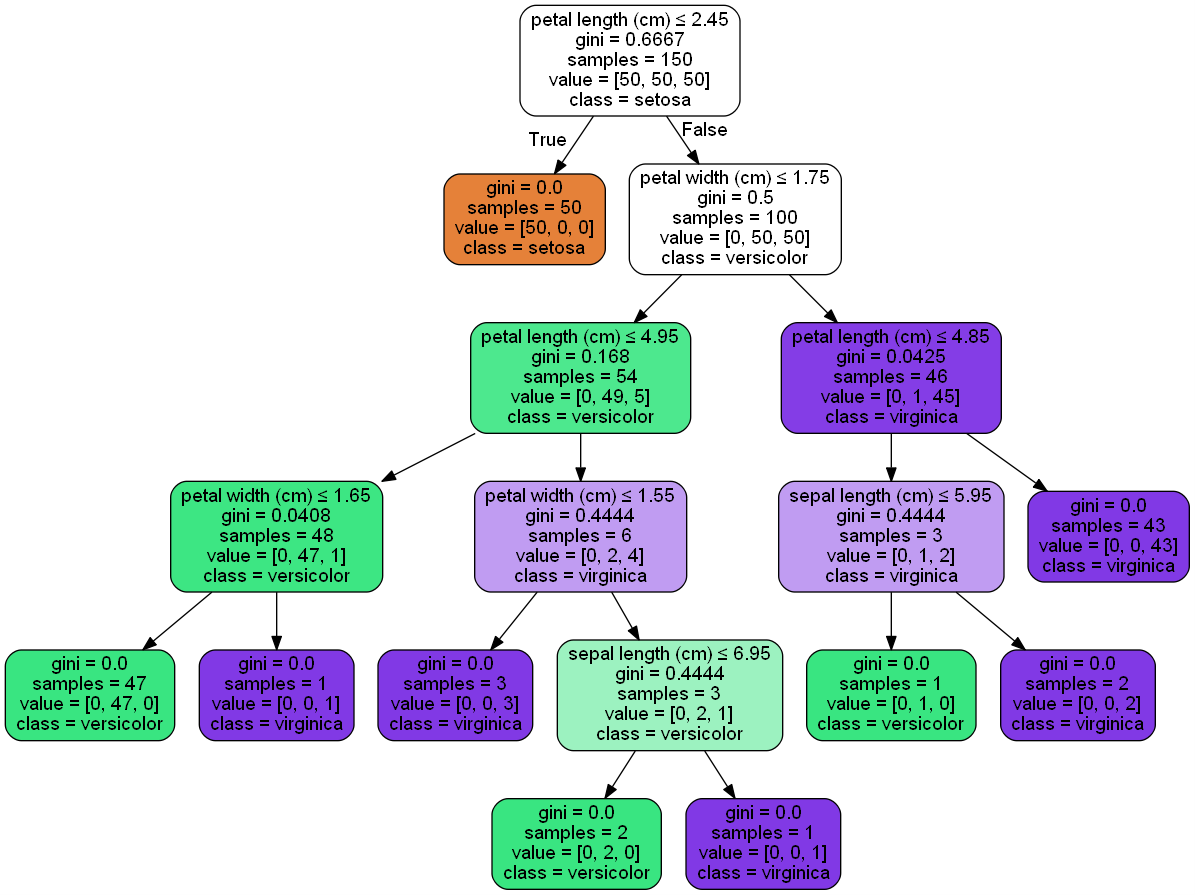
6.5 DecisionTreeClassifier实例
这里给一个限制决策树层数为4的DecisionTreeClassifier例子。
from itertools import product
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
# 仍然使用自带的iris数据
iris = datasets.load_iris()
X = iris.data[:, [0, 2]]
y = iris.target
# 训练模型,限制树的最大深度4
clf = DecisionTreeClassifier(max_depth=4)
#拟合模型
clf.fit(X, y)
# 画图
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.8)
plt.show()
得到的图如下:
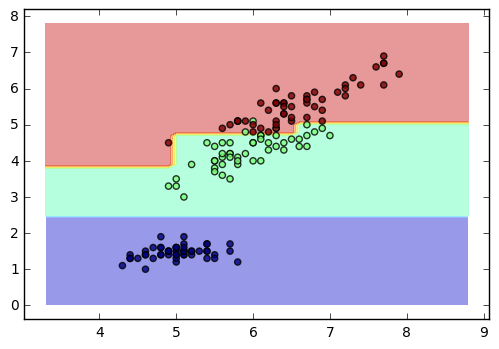
接着我们可视化我们的决策树,使用了推荐的第三种方法。代码如下:
from IPython.display import Image
from sklearn import tree
import pydotplus
dot_data = tree.export_graphviz(clf, ut_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
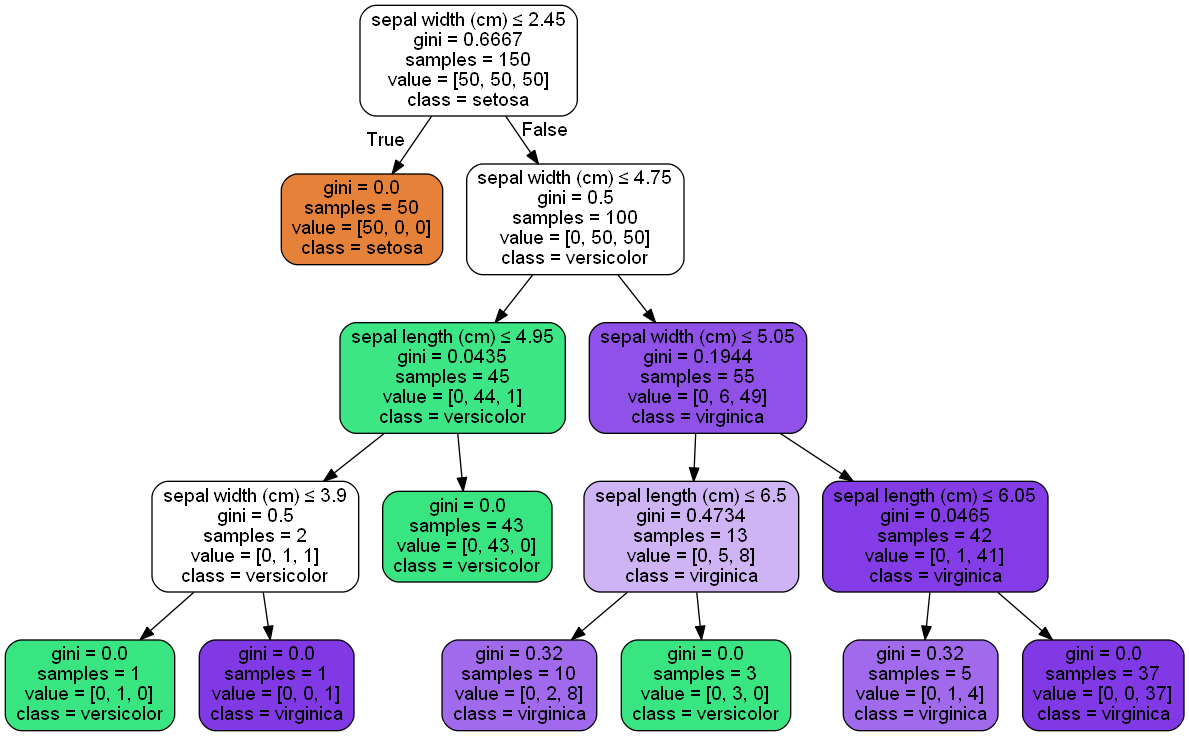
生成的决策树图如下:














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









