









我们知道,kafka中每个topic被划分为多个partition,每个partition又有多个副本,那么这些分区副本是怎么均匀的分布在整个kafka集群的broker节点上的?partition副本的leader是通过什么算法选举出来的?partition副本的follower是怎么复制备份leader的数据的?本文我们就来说一说和 kafka 高可用相关的一些策略。
01
名词解释
要想说明白kafka的HA机制,我们必须先搞明白几个缩写名词,
1、AR、ISR、OSR
AR:Assigned Replicas,某分区的所有副本(这里所说的副本包括leader和follower)统称为 AR。
ISR:In Sync Replicas,所有与leader副本保持"一定程度同步"的副本(包括leader副本在内)组成 ISR 。生产者发送消息时,只有leader与客户端发生交互,follower只是同步备份leader的数据,以保障高可用,所以生产者的消息会先发送到leader,然后follower才能从leader中拉取消息进行同步,同步期间,follower的数据相对leader而言会有一定程度的滞后,前面所说的"一定程度同步"就是指可忍受的滞后范围,这个范围可以通过server.properties中的参数进行配置。
OSR :Out-of-Sync Replied,在上面的描述中,相对leader滞后过多的follower将组成OSR 。
由此可见,AR = ISR + OSR,理想情况下,所有的follower副本都应该与leader 保持一定程度的同步,即AR=ISR,OSR集合为空
2、ISR 的伸缩性
leader负责跟踪维护 ISR 集合中所有follower副本的滞后状态,当follower副本"落后太多" 或 "follower超过一定时间没有向leader发送同步请求"时,leader副本会把它从 ISR 集合中剔除。如果 OSR 集合中有follower副本"追上"了leader副本,那么leader副本会把它从 OSR 集合转移至 ISR 集合。
上面描述的"落后太多"是指follower复制的消息落后于leader的条数超过预定值,这个预定值可在server.properties中通过replica.lag.max.messages配置,其默认值是4000。"超过一定时间没有向leader发送同步请求",这个"一定时间"可以在server.properties中通过replica.lag.time.max.ms来配置,其默认值是10000,默认情况下,当leader发生故障时,只有 ISR 集合中的follower副本才有资格被选举为新的leader,而在 OSR 集合中的副本则没有任何机会(不过这个可以通过配置来改变)。
3、HW
HW (High Watermark)俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能消费HW之前的消息。
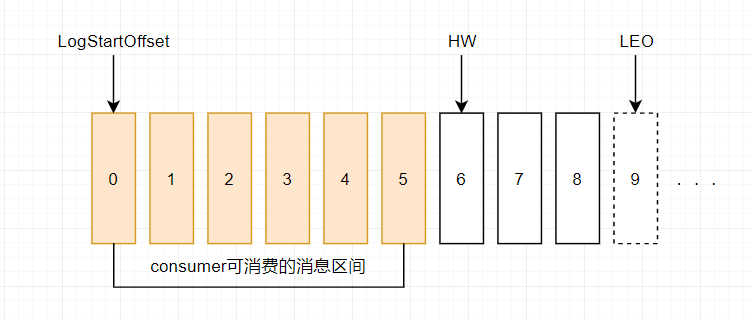
下图表示一个日志文件,这个日志文件中有9条消息,第一条消息的offset为0,最后一条消息的offset为8,虚线表示的offset为9的消息,代表下一条待写入的消息。日志文件的 HW 为6,表示消费者只能拉取offset在 0 到 5 之间的消息,offset为6的消息对消费者而言是不可见的。
4、LEO
LEO (Log End Offset),标识当前日志文件中下一条待写入的消息的offset。上图中offset为9的位置即为当前日志文件的 LEO,分区 ISR 集合中的每个副本都会维护自身的 LEO ,而 ISR 集合中最小的 LEO 即为分区的 HW(你品,你细品...),对消费者而言只能消费 HW 之前的消息。
5、 ISR 集合和 HW、LEO的关系
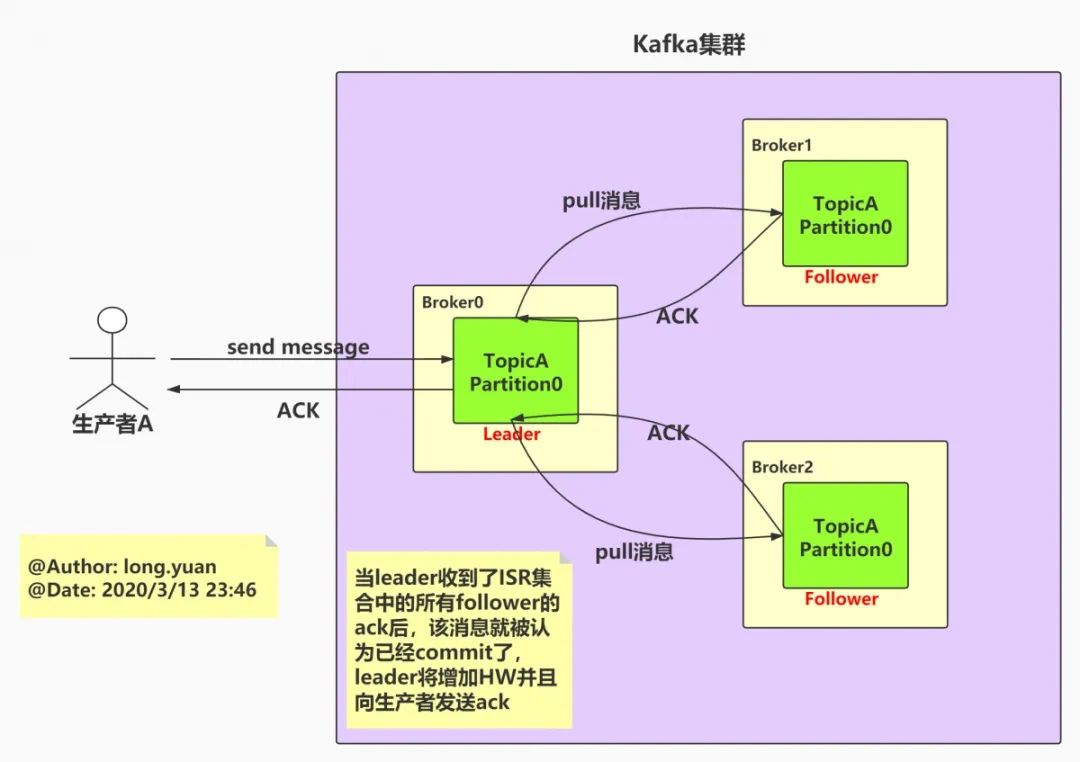
producer在发布消息到partition时,只会与该partition的leader发生交互将消息发送给leader,leader会将该消息写入其本地log,每个follower都从leader上pull数据做同步备份,follower在pull到该消息并写入其log后,会向leader发送ack,一旦leader收到了ISR中的所有follower的ack(只关注ISR中的所有follower,不考虑OSR,一定程度上提升了吞吐),该消息就被认为已经commit了,leader将增加HW,然后向producer发送ack。
也就是说,在ISR中所有的follower还没有完成数据备份之前,leader不会增加HW,也就是这条消息暂时还不能被消费者消费,只有当ISR中所有的follower都备份完成后,leader才会将HW后移。
ISR集合中LEO最小的副本,即同步数据同步的最慢的一个,这个最慢副本的LEO即leader的HW,消费者只能消费HW之前的消息。
02
kafka HA
Tips:我们说的副本包括leader和follower,都叫副本,不要认为叫副本说的就是follower。
kafka在0.8以前的版本中是没有分区副本的概念的,一旦某一个broker宕机,这个broker上的所有分区都将不可用。在0.8版本以后,引入了分区副本的概念,同一个partition可以有多个副本,在多个副本中会选出一个做leader,其余的作为follower,只有leader对外提供读写服务,follower只负责从leader上同步拉取数据,已保障高可用。
1、partition副本的分配策略
每个topic有多个partition,每个partition有多个副本,这些partition副本分布在不同的broker上,以保障高可用,那么这些partition副本是怎么均匀的分布到集群中的每个broker上的呢?
※ kafka分配partition副本的算法如下,
① 将所有的broker(假设总共n个broker)和 待分配的partition排序;
② 将第i个partition分配到第(i mod n)个broker上;
③ 第i个partition的第j个副本分配到第((i+j) mod n)个broker上;
2、kafka的消息传递备份策略
生产者将消息发送给分区的leader,leader会将该消息写入其本地log,然后每个follower都会从leader pull数据,follower pull到该消息并将其写入log后,会向leader发送ack,当leader收到了ISR集合中所有follower的ack后,就认为这条消息已经commit了,leader将增加HW并且向生产者返回ack。在整个流程中,follower也可以批量的从leader复制数据,以提升复制性能。
producer在发送消息的时候,可指定参数acks,表示"在生产者认为发送请求完成之前,有多少分区副本必须接收到数据",有三个可选值,0、1、all(或-1),默认为1,
-
acks=0,表示producer只管发,只要发出去就认为发发送请求完成了,不管leader有没有收到,更不管follower有没有备份完成。
-
acks=1,表示只要leader收到消息,并将其写入自己log后,就会返回给producer ack,不考虑follower有没有备份完成。
-
acks=all(或-1),表示不仅要leader收到消息写入本地log,还要等所有ISR集合中的follower都备份完成后,producer才认为发送成功。
 实际上,为了提高性能,follower在pull到消息将其保存到内存中而尚未写入磁盘时,就会向leader发送ack,所以也就不能完全保证异常发生后该条消息一定能被Consumer消费。
实际上,为了提高性能,follower在pull到消息将其保存到内存中而尚未写入磁盘时,就会向leader发送ack,所以也就不能完全保证异常发生后该条消息一定能被Consumer消费。
3、kafka中的Leader选举
面试官在考查你kafka知识的时候如果问你:kafka中的选举是怎么回事?而不说具体哪种选举,那这个面试官可能对kafka也是一知半解,这个时候就是"弄死"他的时候了,当然如果你没有一定的知识储备,那么就是你被"弄死"的时候。
因为kafka中涉及到选举的地方有多处,最常提及的也有:①cotroller选举 、 ②分区leader选举 和 ③consumer group leader的选举。我们在前面说过同一个partition有多个副本,其中一个副本作为leader,其余的作为follower。这里我们再说一个角色:controller!kafka集群中多个broker,有一个会被选举为controller,注意区分两者,一个是broker的leader,我们称为controller,一个是分区副本的leader,我们称为leader。
① controller的选举【broker的leader】
controller的选举是通过broker在zookeeper的"/controller"节点下创建临时节点来实现的,并在该节点中写入当前broker的信息 {“version”:1,”brokerid”:1,”timestamp”:”1512018424988”} ,利用zookeeper的强一致性特性,一个节点只能被一个客户端创建成功,创建成功的broker即为controller,即"先到先得"。
当controller宕机或者和zookeeper失去连接时,zookeeper检测不到心跳,zookeeper上的临时节点会被删除,而其它broker会监听临时节点的变化,当节点被删除时,其它broker会收到通知,重新发起controller选举。
② leader的选举【分区副本的leader】
分区leader的选举由 controller 负责管理和实施,当leader发生故障时,controller会将leader的改变直接通过RPC的方式通知需要为此作出响应的broker,需要为此作出响应的broker即该分区的ISR集合中follower所在的broker,kafka在zookeeper中动态维护了一个ISR,只有ISR里的follower才有被选为Leader的可能。
具体过程是这样的:按照AR集合中副本的顺序 查找到 第一个 存活的、并且属于ISR集合的 副本作为新的leader。一个分区的AR集合在创建分区副本的时候就被指定,只要不发生重分配的情况,AR集合内部副本的顺序是保持不变的,而分区的ISR集合上面说过因为同步滞后等原因可能会改变,所以注意这里是根据AR的顺序而不是ISR的顺序找。
※ 对于上面描述的过程我们假设一种极端的情况,如果partition的所有副本都不可用时,怎么办?这种情况下kafka提供了两种可行的方案:
1、选择 ISR中 第一个活过来的副本作为Leader;
2、选择第一个活过来的副本(不一定是ISR中的)作为Leader;
这就需要在可用性和数据一致性当中做出选择,如果一定要等待ISR中的副本活过来,那不可用的时间可能会相对较长。选择第一个活过来的副本作为Leader,如果这个副本不在ISR中,那数据的一致性则难以保证。kafka支持用户通过配置选择,以根据业务场景在可用性和数据一致性之间做出权衡。
③消费组leader的选举
组协调器会为消费组(consumer group)内的所有消费者选举出一个leader,这个选举的算法也很简单,第一个加入consumer group的consumer即为leader,如果某一时刻leader消费者退出了消费组,那么会重新 随机 选举一个新的leader。
03
kafka架构中zookeeper的结构
1、查看方式
我们知道,kafka是基于zookeeper协调管理的,那么zookeeper中究竟存储了哪些信息?另外在后面分析 broker宕机 和 controller宕机 时,我们也需要先了解zookeeper的目录结构,所以我们先学习一下怎么查看zookeeper的目录结构?
① 首先启动zookeeper客户端连接zk服务
# cd /usr/local/zookeeper-cluster/zk1/bin# ./zkCli.sh
② 查看zk根节点的子目录
[zk: localhost:2181(CONNECTED) 0] ls /[cluster, controller_epoch, controller, brokers, zookeeper, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config]
③ 可以看到zk根节点下有很多子目录,以brokers为例,查看brokers的层级结构
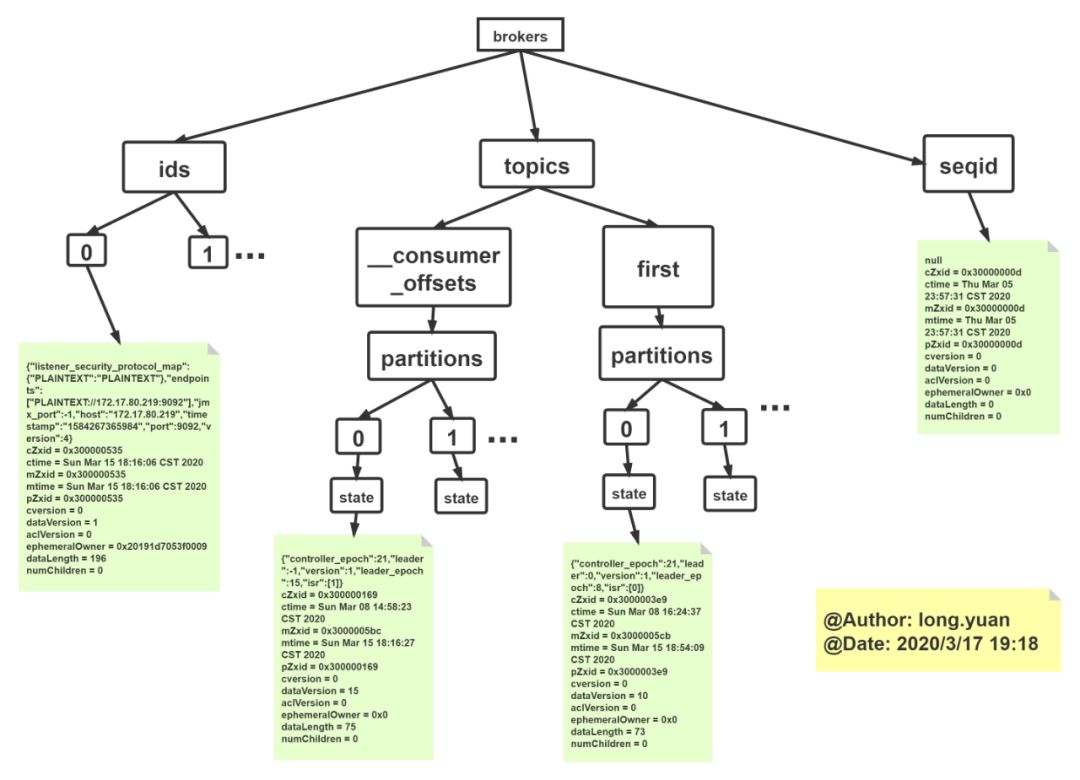
[zk: localhost:2181(CONNECTED) 1] ls /brokers[ids, topics, seqid][zk: localhost:2181(CONNECTED) 2] ls /brokers/ids[0][zk: localhost:2181(CONNECTED) 3] get /brokers/ids/0{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://172.17.80.219:9092"],"jmx_port":-1,"host":"172.17.80.219","timestamp":"1584267365984","port":9092,"version":4}cZxid = 0x300000535ctime = Sun Mar 15 18:16:06 CST 2020mZxid = 0x300000535mtime = Sun Mar 15 18:16:06 CST 2020pZxid = 0x300000535cversion = 0dataVersion = 1aclVersion = 0ephemeralOwner = 0x20191d7053f0009dataLength = 196numChildren = 0[zk: localhost:2181(CONNECTED) 4][zk: localhost:2181(CONNECTED) 4][zk: localhost:2181(CONNECTED) 4][zk: localhost:2181(CONNECTED) 4] ls /brokers/topics[__consumer_offsets, first][zk: localhost:2181(CONNECTED) 5] ls /brokers/topics/first[partitions][zk: localhost:2181(CONNECTED) 6] ls /brokers/topics/first/partitions[0, 1][zk: localhost:2181(CONNECTED) 7] ls /brokers/topics/first/partitions/0[state][zk: localhost:2181(CONNECTED) 8] get /brokers/topics/first/partitions/0/state{"controller_epoch":21,"leader":0,"version":1,"leader_epoch":8,"isr":[0]}cZxid = 0x3000003e9ctime = Sun Mar 08 16:24:37 CST 2020mZxid = 0x3000005cbmtime = Sun Mar 15 18:54:09 CST 2020pZxid = 0x3000003e9cversion = 0dataVersion = 10aclVersion = 0ephemeralOwner = 0x0dataLength = 73numChildren = 0[zk: localhost:2181(CONNECTED) 9]
可以看到,brokers下包括[ids, topics, seqid],ids里面存储了存活的broker的信息,topics里面存储了kafka集群中topic的信息。同样的方法,可以查看其余节点的结构,这里不再演示。
2、节点信息(这里只列出和HA相关的部分节点)
① controller
controller节点下存放的是kafka集群中controller的信息(controller即kafka集群中所有broker的leader)。
② controller_epoch
controller_epoch用于记录controller发生变更的次数(controller宕机后会重新选举controller,这时候controller_epoch的值会+1),即记录当前的控制器是第几代控制器,用于防止broker脑裂。
③ brokes
brokers下的ids存储了存活的broker信息,topics存储了kafka集群中topic的信息,其中有一个特殊的topic:_consumer_offsets,新版本的kafka将消费者的offset就存储在__consumer_offsets下。
04
broker failover
我们了解了kafka集群中zookpeeper的结构,本文的主题是kafka的高可用分析,所以我们还是结合zookpper的结构,来分析一下,当kafka集群中的一个broker节点宕机时(非controller节点),会发生什么?
在讲之前,我们再来回顾一下brokers的结构,
※ 当非controller的broker宕机时,会执行如下操作,
1、controller会在zookeeper的 " /brokers/ids/" 节点注册一个watcher(监视器),当有broker宕机时,zookeeper会触发监视器(fire watch)通知controller。
2、controller 从 "/brokers/ids" 节点读取到所有可用的broker。
3、controller会声明一个set_p集合,该集合包含了宕机broker上所有的partition。
4、针对set_p中的每一个partition,
① 从 "/state"节点 读取该partition当前的ISR;
② 决定该partition的新leader:如果该分区的 ISR中有存活的副本,则选择其中一个作为新leader;如果该partition的ISR副本全部挂了,则选择该partition的 AR集合 中任一幸存的副本作为leader;如果该partition的所有副本都挂,则将分区的leader设为-1;
③ 将新 leader、ISR、controller_epoch 和 leader_epoch 等信息写入 state 节点;
5、通过RPC向set_p相关的broker发送LeaderAndISR Request命令。
05
controller failover
当 controller 宕机时会触发 controller failover。每个 broker 都会在 zookeeper 的 "/controller" 节点注册 watcher(监听器),当 controller 宕机时 zookeeper 中的临时节点消失,所有存活的 broker 收到 fire 的通知,每个 broker 都尝试创建新的临时节点,只有一个会创建成功并当选为 controller。
当新的 controller 当选时,会回调KafkaController的onControllerFailover()方法,在这个方法中完成controller的初始化,controller 在初始化时,首先会利用 ZK 的 watch 机制注册很多不同类型的监听器,主要有以下几种:
-
监听 /admin/reassign_partitions 节点,用于分区副本迁移的监听;
-
监听 /isr_change_notification 节点,用于 Partition Isr 变动的监听;
-
监听 /admin/preferred_replica_election 节点,用于 Partition 最优 leader 选举的监听;
-
监听 /brokers/topics 节点,用于 topic 新建的监听;
-
监听 /brokers/topics/TOPIC_NAME 节点,用于 Topic Partition 扩容的监听;
-
监听 /admin/delete_topics 节点,用于 topic 删除的监听;
-
监听 /brokers/ids 节点,用于 Broker 上下线的监听;
除了注册多种监听器外,controller初始化时还做以下操作,
-
initializeControllerContext()
初始化controller上下文,设置当前所有broker、topic、partition的leader、ISR等;
-
replicaStateMachine.startup()
-
partitionStateMachine.startup()
启动状态机;
-
brokerState.newState(RunningAsController)
将 brokerState 状态设置为 RunningAsController;
-
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq)
把partition leadership信息发到所有brokers;
-
autoRebalanceScheduler.startup()
如果打开了autoLeaderRebalance,则启动"partition-rebalance-thread"线程;
-
deleteTopicManager.start()
如果delete.topic.enable=true,且 /admin/delete_topics 节点下有值,则删除相应的topic;
最后,把onControllerFailover()方法的源码贴一下,上面说的这些操作就是在这个方法中完成的,感兴趣的可以再去看下kafka源码,
def onControllerFailover() {if (isRunning) {info("Broker %d starting become controller state transition".format(config.brokerId))//read controller epoch from zkreadControllerEpochFromZookeeper()// increment the controller epochincrementControllerEpoch(zkUtils.zkClient)// before reading source of truth from zookeeper, register the listeners to get broker/topic callbacksregisterReassignedPartitionsListener()registerIsrChangeNotificationListener()registerPreferredReplicaElectionListener()partitionStateMachine.registerListeners()replicaStateMachine.registerListeners()initializeControllerContext()replicaStateMachine.startup()partitionStateMachine.startup()// register the partition change listeners for all existing topics on failovercontrollerContext.allTopics.foreach(topic => partitionStateMachine.registerPartitionChangeListener(topic))info("Broker %d is ready to serve as the new controller with epoch %d".format(config.brokerId, epoch))brokerState.newState(RunningAsController)maybeTriggerPartitionReassignment()maybeTriggerPreferredReplicaElection()/* send partition leadership info to all live brokers */sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq)if (config.autoLeaderRebalanceEnable) {info("starting the partition rebalance scheduler")autoRebalanceScheduler.startup()autoRebalanceScheduler.schedule("partition-rebalance-thread", checkAndTriggerPartitionRebalance,5, config.leaderImbalanceCheckIntervalSeconds.toLong, TimeUnit.SECONDS)}deleteTopicManager.start()}elseinfo("Controller has been shut down, aborting startup/failover")}














 2543
2543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









