









1.平衡二叉树
有序二叉树可能存在的问题
给一个数列{1,2,3,4,5,6},要求创建一颗二叉排序树(BST)并分析问题所在
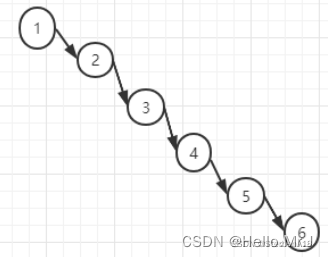
- 左边子树全为空,更像是一个链表
- 插入速度没有影响
- 查询速度明显降低,不能发挥二叉树的优势,同时需要每次访问左子树,导致查询速度甚至小于单链表
解决方法:平衡二叉树
平衡二叉树的介绍
平衡二叉树具有以下特点:
- 它是一颗空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两颗子树都是一颗平衡二叉树。
- 平衡因子: 左子树的高度 - 右子树的高度
我们将平衡因子的绝对值小于1的的有序二叉树称为平衡二叉树
构建平衡二叉树的思路
四种旋转类型的旋转
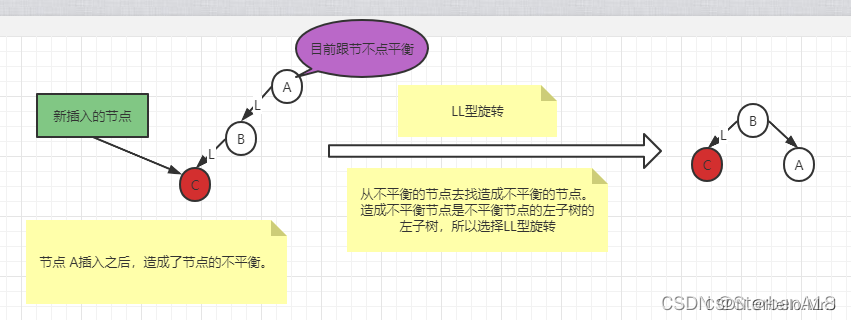
1.LL型旋转-----(中为支,高右转)
1.将A的左孩子B提升为新的根节点
2.将原来的根节点A降为B的右孩子
3.将各子树按大小关系连接
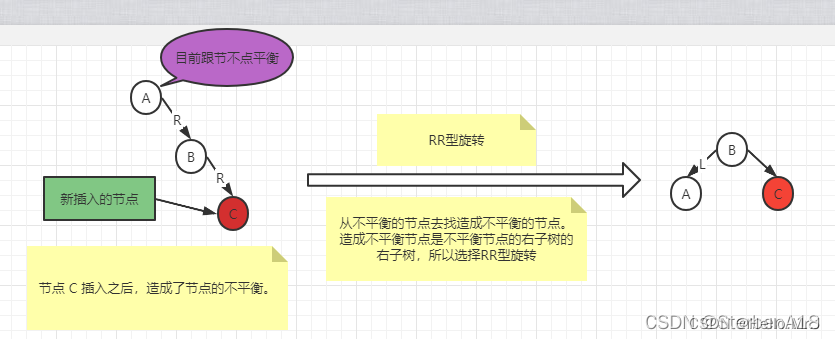
2.RR型旋转-----(中为支,高左旋)
1.将A的右孩子B升为新的根节点
2.将原来的根节点降为左孩子
3.将各子树按大小关系连接
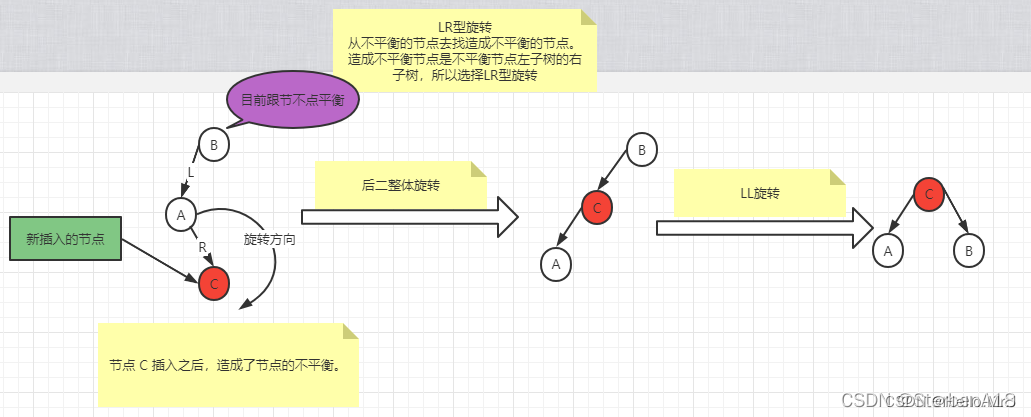
3.LR型旋转-----(下二整体先旋转,后与LL同)
1.将B的左孩子C提升为新的根节点
2.将原来的跟节点A降为C的右孩子
3.将各子树按大小关系连接
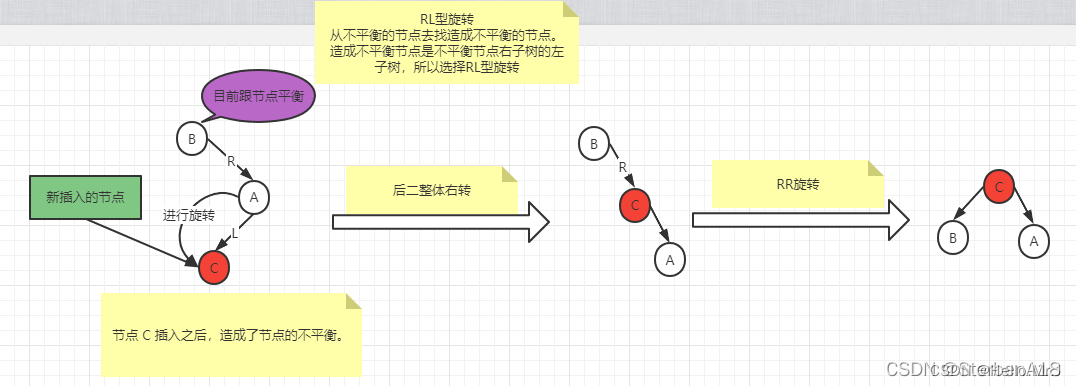
4.RL型旋转-----(下二整体先右转,后与RR同)
1.将B的左子树C提升为新的根节点
2.将原来的根节点A降为C的左孩子
3.将各子树按大小关系连接
平衡的调整步骤
- 如果插入一个新节点,造成了不平衡,则需要调整
- 判断旋转类型
- 调整
2.B树
认识2-3查找树
二叉排序树简单的实现在多数情况能够达到预期的查找效率,但是每个节点只能存储一个元素和只能有两个孩子,使得在大量数据下会造成二叉排序树的深度特别大,那么在进行查找时多次的访问会造成查找效率的下降,同时,在对二叉查找树进行插入时,可能会破坏二叉查找树的平衡。为了降低对于树的访问次数,实现树的平衡,我们需要新的数据结构来处理这样的问题。
2-3查找树的定义
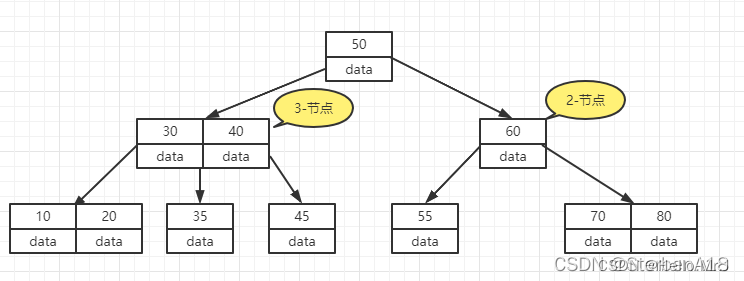
2-节点: 包含一个键(及其对应的值)和两条链,左连接指向2-3树中都小于该节点,右链接所指向的值都大于该节点。
3-节点: 包含两个键(及其对应的值)和三条链,左链接指向2-3树中的键都小于该节点,中链接指向的2-3树中的键都位于该节点的两个键之间,右连接指向的2-3树中的键都大于该节点。
B树的特点
B树中允许一个节点包含多个Key,可以是3个、4个、5个甚至是更多,并不确定,需要看具体实现。现在我们选择一个参数M来构建一个B树,我们可以将其称为M阶的B树。那么这棵树会有以下特点:
- 每个节点最多有M-1个Key,并且以升序排列
- 每个节点最多能有M个子节点
- 根节点至少有两个子节点
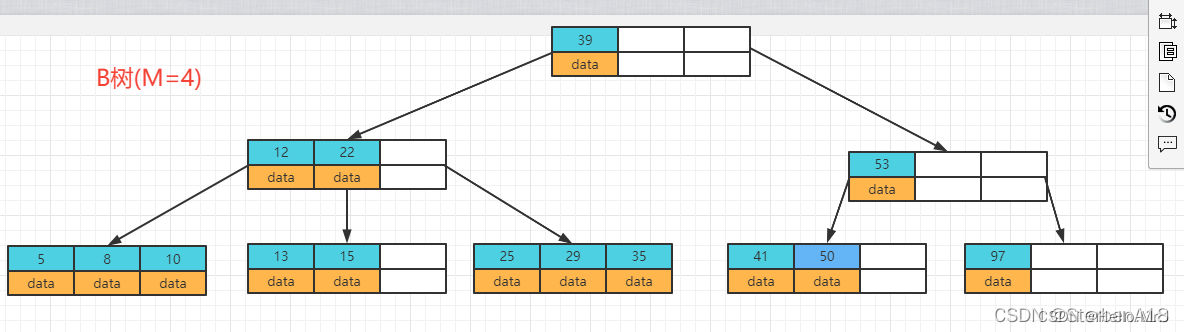
在实际应用中B树的阶数一般比较大(通常大于100),所以,即使存储大量的数据,B树的高度仍然比较小,这样在某些引用场景下,就能体现出他的优势
3.B+树
B+树的结构特点
- 非叶子节点仅具有索引作用,也就是说,非叶子节点只能存储Key,不能存储value
- 树的所有叶节点构成一个有序链表,可以按照key排序的次序依次遍历全部数据。
B+树存储数据
若参数M选择为5,那么每个节点最多包含4个键值对,我们以5阶B+树为例,看看B+树的数据存储
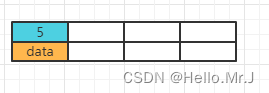
(a) 在空树当中插入5
(b)继续插入8,10,15

(c)继续插入16
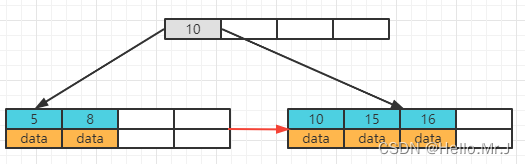
(d)继续插入17
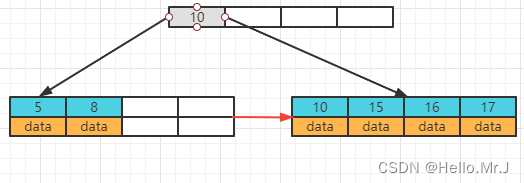
(e)继续插入18
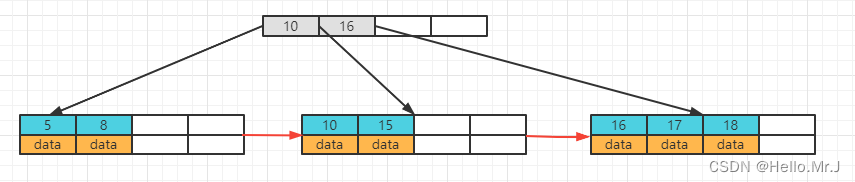
(f)继续插入6,9,1920,21,22

(e)继续插入7
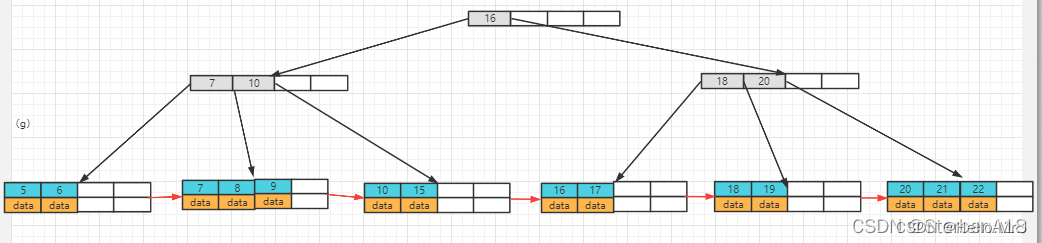
B+树和B树的对比
B+ 树的优点在于:
- 由于B+树在非叶子结点上不包含真正的数据,只当做索引使用,因此在内存相同的情况下,能够存放更多的key。
- B+树的叶子结点都是相连的,因此对整棵树的遍历只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。
B树的优点在于:
- 由于B树的每一个节点都包含key和value,因此我们根据key查找value时,只需要找到key所在的位置,就能找到value,但B+树只有叶子结点存储数据,索引每一次查找,都必须一次一次,一直找到树的最大深度处,也就是叶子结点的深度,才能找到value
B+树在数据库中的应用
在数据库的操作中,查询操作可以说是最频繁的一种操作,因此在设计数据库时,必须要考虑到查询的效率问题,在很多数据库中,都是用到了B+树来提高查询的效率;
在操作数据库时,我们为了提高查询效率,可以基于某张表的某个字段建立索引,就可以提高查询效率,那其实这个索引就是B+树这种数据结构实现的。
未建立主键索引查询
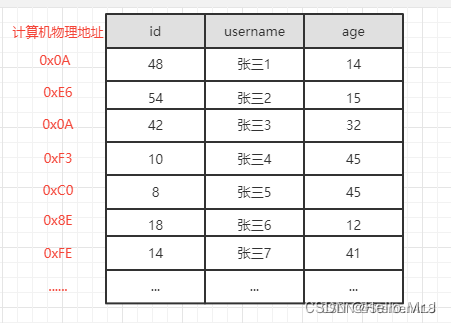
执行 select * from user where id=18 ,需要从第一条数据开始,一直查询到第6条,发现id=18,此时才能查询出目标结果,共需要比较6次;
建立主键索引查询
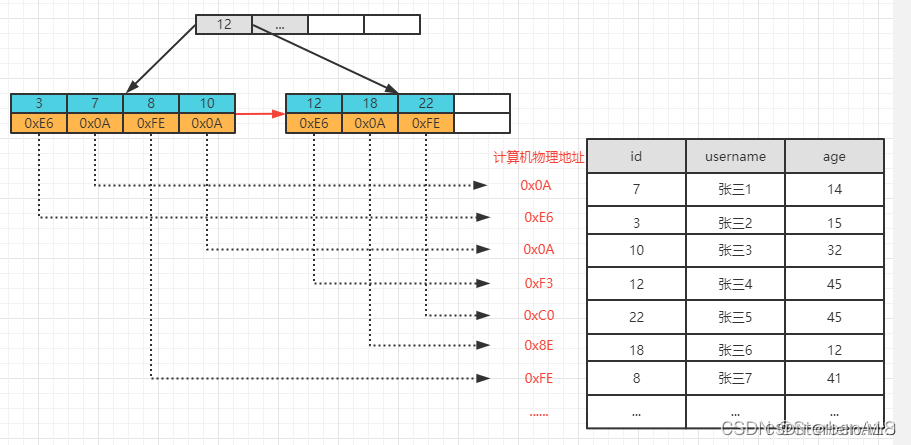
区间查询: 执行 select * from user where id>=10 and id<=18 ,如果有了索引,由于B+树的叶子结点形成了一个有序链表,所以我们只需要找到id为12的叶子结点,按照遍历链表的方式顺序往后查即可,效率非常高。
















 3874
3874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









