







1、数据下载
从kaggle下载相关数据:kaggle地址
整个数据集包括3个部分:训练集文件夹、测试集文件夹、训练集对应的 label 的csv文件
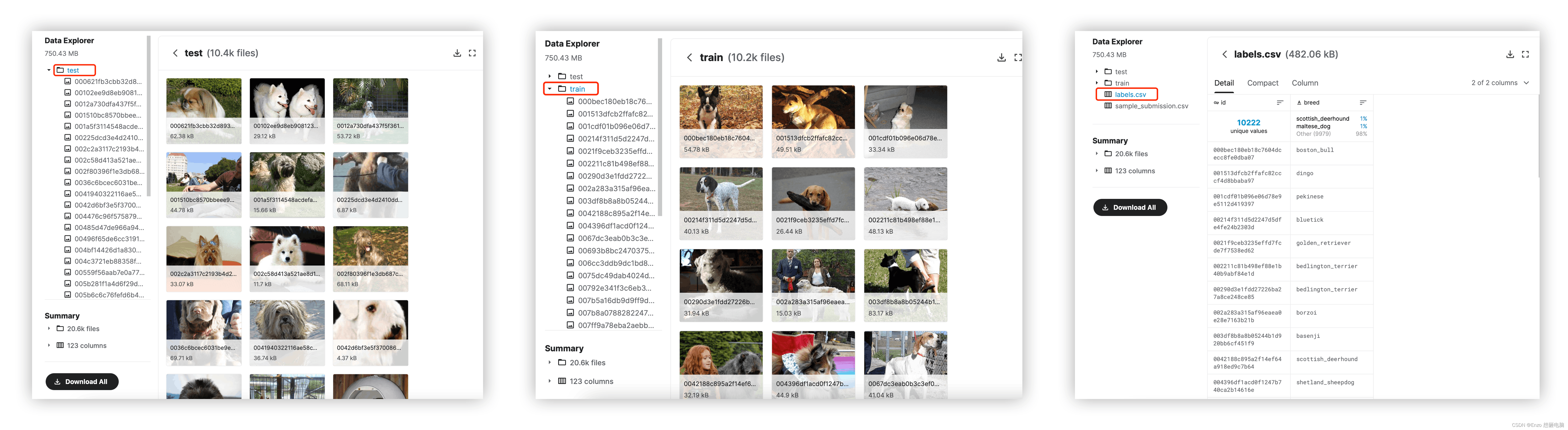
数据我下载到了项目文件夹里,重命名为 “dog_breed_original_data”

然后,我们读取 label,看下相关信息
(这里,我用了 yaml 文件,为了方便之后修改文件名或者超参数,也为了大家复制代码直接跑着方便些)
import os
import yaml
import numpy as np
import pandas as pd
from torch.utils import data
from torchvision import transforms, utils
from PIL import Image
dir_root = os.getcwd()
with open(os.path.join(dir_root, 'config.yml'), "r") as f:
y = yaml.load(f, Loader=yaml.FullLoader)
df = pd.read_csv(os.path.join(dir_root, y['file']['labels_csv']))
print(df.info())
print(df.head())
train_img_files = os.listdir(os.path.join(dir_root, y['file']['train_img'])) # 读取 训练集 中的所有文件
test_img_files = os.listdir(os.path.join(dir_root, y['file']['test_img'])) # 读取 测试集 中的所有文件
print('\ntrain_img_files number:', len(train_img_files)) # 训练集中的文件个数
print('test_img_files number:', len(test_img_files)) # 测试集中的文件个数
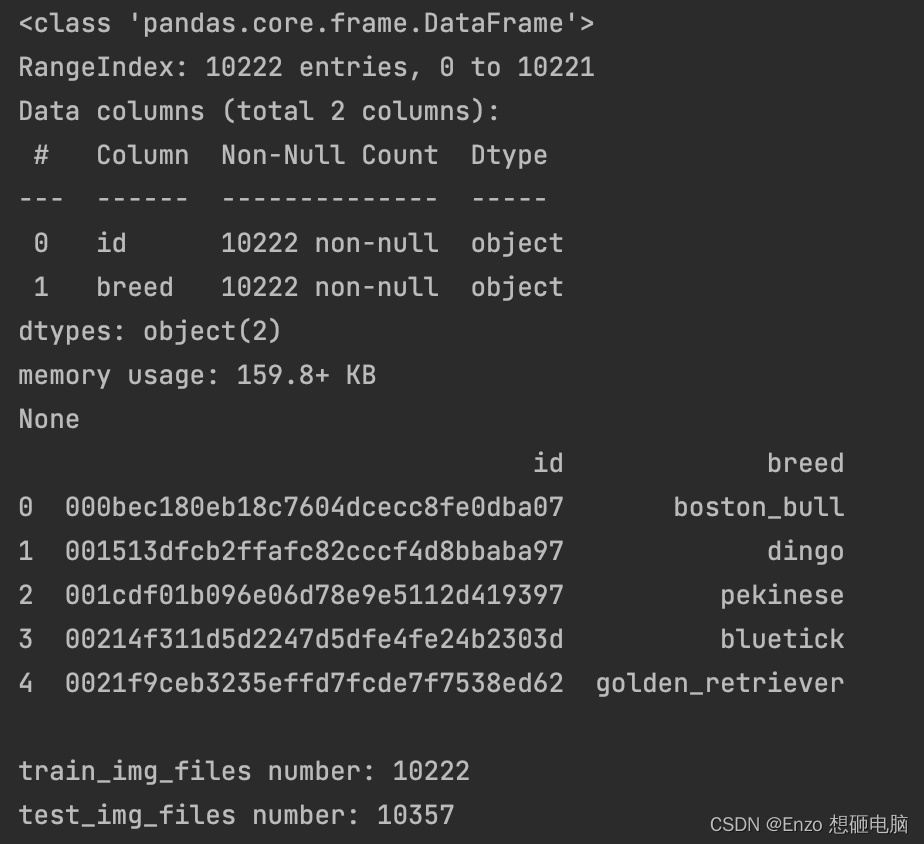
label 一共10222条,train文件夹中图片10222张,test文件夹中图片10375张。
稍后, 我们将train文件夹中的图片 8-2 分,作为 训练集 和验证集。
=======================================================
2、数据预处理
整个数据预处理包括如下2个部分
1)将图片数据分成2个部分:前80%用作训练集、后20%用作验证集(验证集)
为了保证 图片 和 label 一一对应的正确性,我们从 label.csv 中有顺的读取 id(图片的名称), 拼出图片地址。
2)标签也分成两部分,前80% 的部分对应训练集,后20% 的部分对应验证集
将犬种的名称枚举出来,并用数字一一映射表示; 再将表示犬种的label由名称映射到其对应的数字上
# -----------------------------------
# 将 label 中读出的两列,都转换成 numpy
# -----------------------------------
label_breed = pd.Series.to_numpy(df['breed'])
label_id = pd.Series.to_numpy(df['id'])
# -----------------------------------
# 将图片拆分为两部分: 训练集(80%) 和 训练集(20%)
# -----------------------------------
file = [os.path.join(dir_root, y['file']['train_img'], i + '.jpg') for i in label_id]
num = np.int(len(file)*0.8)
file_train = file[:num] # 取 80% 的数据作为训练集
file_vali = file[num:] # 取 20% 的数据作为验证集
# -----------------------------------
# 枚举品种的名称,并映射到对应的数字上
# -----------------------------------
breed_list = list(set(label_breed))
# print(len(breed_list)) # 共120个品种
dic = {}
for i in range(len(breed_list)):
dic[breed_list[i]] = i
# -----------------------------------
# 将每一个样本的 label 都映射到其对应的编号
# 并分为:训练集(80%) 和 训练集(20%)
# -----------------------------------
label_num = []
for i in range(len(label_breed)):
label_num.append(dic[label_breed[i]])
label_num = np.array(label_num)
train_label = label_num[:num]
vali_label = label_num[num:]
3、重写Dataset,并配置数据迭代器 DataLoader
# -----------------------------------
# 重写 Dataset
# -----------------------------------
class TrainSet(data.Dataset):
def __init__(self):
self.images = file_train
self.labels = train_label
self.preprocess = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=y['mean'], std=y['std'])])
def __getitem__(self, index):
file_name = self.images[index]
img_pil = Image.open(file_name)
img_pil = img_pil.resize((224, 224))
img_tensor = self.preprocess(img_pil)
label = self.labels[index]
return img_tensor, label
def __len__(self):
return len(self.images)
train_data = TrainSet()
train_loader = data.DataLoader(train_data, batch_size=4, shuffle=True)
for i, train_data in enumerate(train_loader):
print('i:', i)
img, label = train_data
print(img)
print(label)
4、完整版汇总
import os
import yaml
import numpy as np
import pandas as pd
from torch.utils import data
from torchvision import transforms, utils
from PIL import Image
dir_root = os.getcwd()
with open(os.path.join(dir_root, 'config.yml'), "r") as f:
y = yaml.load(f, Loader=yaml.FullLoader)
df = pd.read_csv(os.path.join(dir_root, y['file']['labels_csv']))
# print(df.info())
# print(df.head())
train_img_files = os.listdir(os.path.join(dir_root, y['file']['train_img'])) # 读取 训练集 中的所有文件
test_img_files = os.listdir(os.path.join(dir_root, y['file']['test_img'])) # 读取 测试集 中的所有文件
# print('\ntrain_img_files number:', len(train_img_files)) # 训练集中的文件个数
# print('test_img_files number:', len(test_img_files)) # 测试集中的文件个数
# -----------------------------------
# 将 label 中读出的两列,都转换成 numpy
# -----------------------------------
label_breed = pd.Series.to_numpy(df['breed'])
label_id = pd.Series.to_numpy(df['id'])
# -----------------------------------
# 将图片拆分为两部分: 训练集(80%) 和 训练集(20%)
# -----------------------------------
file = [os.path.join(dir_root, y['file']['train_img'], i + '.jpg') for i in label_id]
num = np.int(len(file)*0.8)
file_train = file[:num] # 取 80% 的数据作为训练集
file_vali = file[num:] # 取 20% 的数据作为验证集
# -----------------------------------
# 枚举品种的名称,并映射到对应的数字上
# -----------------------------------
breed_list = list(set(label_breed))
# print(len(breed_list)) # 共120个品种
dic = {}
for i in range(len(breed_list)):
dic[breed_list[i]] = i
# -----------------------------------
# 将每一个样本的 label 都映射到其对应的编号
# 并分为:训练集(80%) 和 训练集(20%)
# -----------------------------------
label_num = []
for i in range(len(label_breed)):
label_num.append(dic[label_breed[i]])
label_num = np.array(label_num)
train_label = label_num[:num]
vali_label = label_num[num:]
# -----------------------------------
# 重写 Dataset
# -----------------------------------
class TrainSet(data.Dataset):
def __init__(self):
self.images = file_train
self.labels = train_label
self.preprocess = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=y['mean'], std=y['std'])])
def __getitem__(self, index):
file_name = self.images[index]
img_pil = Image.open(file_name)
img_pil = img_pil.resize((224, 224))
img_tensor = self.preprocess(img_pil)
label = self.labels[index]
return img_tensor, label
def __len__(self):
return len(self.images)
train_dataset = TrainSet()
train_loader = data.DataLoader(train_dataset, batch_size=4, shuffle=True)
for i, train_data in enumerate(train_loader):
print('i:', i)
img, label = train_data
print(img)
print(label)
yaml 配置文件
file:
train_img: 'dog_breed_original_data/train'
test_img: 'dog_breed_original_data/test'
labels_csv: 'dog_breed_original_data/labels.csv'
mean: [0.485, 0.456, 0.406] # ImageNet上的均值和方差
std: [0.229, 0.224, 0.225] # ImageNet上的均值和方差
import numpy as np
import torch
from torch.utils import data
class TestDataset(data.Dataset):
def __init__(self):
self.Data = np.asarray([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
self.Label = np.asarray([9, 8, 7, 6, 5])
def __getitem__(self, index):
txt = torch.from_numpy(self.Data[index])
label = torch.tensor(self.Label[index])
return txt, label
def __len__(self):
return len(self.Data)
test = TestDataset()
print(test[2])
print(test.__len__())
# (tensor([3, 4]), tensor(7))
# 5
test_loader = data.DataLoader(test, batch_size=2, shuffle=False)
for i, testdata in enumerate(test_loader):
print('i:', i)
data, label = testdata
print(data)
print(label)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











