







反爬策略
建议大家买这个《Python3网络爬虫开发实战》这本书从这儿可以直接有很多实例,本文中验证码部分是根据这个老师的来进行学习和记录的过程。
请求头伪装
主要是使用urllib和requests来定制请求头跟前面的一样,主要作用还是模拟浏览器请求。
使用
# 使用requests发送请求
import requests
# requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36'
}
url = 'https://www.baidu.com/s?wd=%E6%9E%97%E4%BF%8A%E6%9D%B0'
response = requests.get(url=url,headers=headers)
print(response.status_code,response.text)
import urllib.request,urllib.parse
url = ('https://www.baidu.com/s?wd=')
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36'
}
wd = '林俊杰'
# get 请求参数 quote 是对字符串编码
name = urllib.parse.quote(wd)
print(name)
# get 请求参数
request = urllib.request.Request(url=url+name,headers=headers)
response = urllib.request.urlopen(request)
# 获取相应数据
print(response.code,response.read().decode('utf-8'))
常用字段
| 请求头字段 | 示例值 | 说明 |
|---|---|---|
| User-Agent | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 | 标识客户端浏览器信息 |
| Accept | text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 | 声明可接受的MIME类型 |
| Accept-Language | zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7 | 声明可接受的语言 |
| Accept-Encoding | gzip, deflate, br | 声明可接受的内容编码 |
| Connection | keep-alive | 控制网络连接持久性 |
| Referer | https://www.google.com/ | 表示请求来源页面 |
| Upgrade-Insecure-Requests | 1 | 表示支持HTTPS升级 |
| Cache-Control | max-age=0 | 控制缓存行为 |
| Sec-Fetch-Dest | document | 表示请求的目标 |
| Sec-Fetch-Mode | navigate | 表示请求模式 |
| Sec-Fetch-Site | same-origin | 表示请求来源与目标的关系 |
| Sec-Fetch-User | ?1 | 表示用户触发的请求 |
| Pragma | no-cache | HTTP/1.0的缓存控制 |
| Host | www.example.com | 指定服务器域名和端口 |
| Content-Type | application/x-www-form-urlencoded | 请求体的MIME类型 |
| Cookie | sessionid=abc123; csrftoken=xyz456 | 服务器设置的cookie信息 |
| Origin | https://www.example.com | 表示跨域请求的来源 |
| X-Requested-With | XMLHttpRequest | 标识AJAX请求 |
| DNT | 1 | Do Not Track请求 |
| TE | Trailers | 指定传输编码 |
| Authorization | Bearer xyz123 | 认证凭证 |
验证码
OCR策略
安装
下载并安装配置path和TESSDATA_PREFIX(路劲为制定需要翻译的语种)
# 不用强行安装tessract 这个pytessract使用的也是tessract
pip install pytessract使用
from PIL import Image
from pytesseract import pytesseract
image = Image.open('png/captcha.png')
# 正确结果:edda 返回解析结果ed4a
result = pytesseract.image_to_string(image)
print(result)常用方法
| 方法/功能 | 语法示例 | 用途说明 | 参数说明 |
|---|---|---|---|
| 基础文字识别 | pytesseract.image_to_string(image, lang='eng') | 识别图片中的文字,返回字符串。 | image: PIL Image/文件路径;lang: 语言(如 chi_sim 中文)。 |
| 识别 + 输出为字典 | pytesseract.image_to_data(image, output_type=pytesseract.Output.DICT) | 返回识别结果的字典,包含文本、位置、置信度等。 | output_type: 指定输出格式(DICT/DATAFRAME)。 |
| 获取字符位置框 | pytesseract.image_to_boxes(image, lang='eng') | 返回每个字符的坐标框(左下角+右上角)。 | 常用于字符级定位。 |
| 识别并保留布局 | pytesseract.image_to_string(image, config='--psm 6') | 保留原始文本布局(如换行符)。 | config: 设置 Tesseract 参数(如 --psm 6 按块识别)。 |
| 仅识别数字 | pytesseract.image_to_string(image, config='--psm 6 digits') | 仅识别数字字符。 | digits: 限制输出为数字。 |
| 多语言混合识别 | pytesseract.image_to_string(image, lang='eng+chi_sim') | 同时识别英文和中文。 | 用 + 连接语言代码。 |
| 获取置信度分数 | pytesseract.image_to_data(image, output_type=Output.DICT)['conf'] | 提取每个识别结果的置信度(0-100)。 | 低置信度可能需要图像预处理。 |
| 设置识别配置 | pytesseract.image_to_string(image, config='--oem 3 --psm 4') | 自定义 OCR 引擎模式(OEM)和页面分割模式(PSM)。 | --oem 3: LSTM+传统引擎;--psm 4: 单列文本。 |
| 批量处理图片 | [pytesseract.image_to_string(img) for img in image_list] | 批量识别多张图片。 | 结合列表推导式使用。 |
| 图像预处理增强识别 | cv2.threshold(img, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] | 二值化处理图像后再识别(需 OpenCV)。 | 常用预处理:灰度化、二值化、降噪。 |
缺点
-
低分辨率/模糊文本:识别准确率显著下降。
-
复杂背景干扰:如噪声、水印、阴影等易导致错误。
-
非标准字体:手写体、艺术字等支持较差。
注意:总之就是无法处理稍微复杂一点的场景图片、必须是无干扰的这个简单了解就行。
opencv策略
场景
解决滑动部分验证码,例如滑动后登录
安装
pip install opencv-python使用
import cv2
import pyautogui
import time
import numpy as np
# 1. 读取背景图和滑块图
target = cv2.imread('start.png', 0) # 灰度图
template = cv2.imread('background.png', 0)
# 2. 边缘检测(Canny)
target_edges = cv2.Canny(target, 50, 150)
template_edges = cv2.Canny(template, 50, 150)
# 3. 轮廓匹配
result = cv2.matchTemplate(target_edges, template_edges, cv2.TM_CCOEFF_NORMED)
_, max_val, _, max_loc = cv2.minMaxLoc(result)
# 4. 计算滑动距离
slide_distance = max_loc[0] # 匹配位置的x坐标
print("滑动距离:", slide_distance)
# 3. 可视化匹配结果(在图片上画矩形)
h, w = template.shape[:2]
cv2.rectangle(target, max_loc, (max_loc[0] + w, max_loc[1] + h), (0, 255, 0), 2)
cv2.imshow('Matching Result', target)
cv2.waitKey(500) # 显示0.5秒
# 4. 使用 PyAutoGUI 模拟滑动
time.sleep(2) # 等待2秒,让你切换到需要滑动的窗口
# 获取滑块初始位置(手动设定或自动检测)
slider_pos = pyautogui.locateOnScreen('start.png', confidence=0.8)
if slider_pos:
slider_x, slider_y = slider_pos.left, slider_pos.top
else:
raise Exception("未找到滑块!")
# 模拟按住滑块并拖动
pyautogui.moveTo(slider_x, slider_y, duration=0.3)
pyautogui.mouseDown()
for i in range(10):
offset = slide_distance * (i + 1) / 10
pyautogui.moveTo(slider_x + offset, slider_y + np.random.randint(-2, 3), duration=0.1)
pyautogui.mouseUp()常用方法
| 方法 | 关键函数/技术 | 适用场景 | 优缺点 |
|---|---|---|---|
| 模板匹配 | cv2.matchTemplate() + cv2.minMaxLoc() | 滑块和目标缺口形状固定,背景简单。 | ✅ 速度快 ❌ 对旋转/缩放敏感 |
| 边缘检测+轮廓匹配 | cv2.Canny() + cv2.findContours() + cv2.boundingRect() | 拼图类验证码,缺口边缘清晰。 | ✅ 适应形状变化 ❌ 需调整阈值 |
| 特征点匹配 | cv2.SIFT/ORB + cv2.BFMatcher() | 复杂背景或变形滑块。 | ✅ 抗干扰强 ❌ 计算量大 |
| 二值化+投影分析 | cv2.threshold() + 水平像素投影统计 | 滑块与背景颜色对比明显。 | ✅ 简单高效 ❌ 依赖颜色对比 |
| 深度学习定位 | cv2.dnn.readNet() (YOLO/SSD) | 极端复杂验证码(扭曲、噪声)。 | ✅ 高精度 ❌ 需训练数据 |
| 动态轨迹模拟 | pyautogui.moveTo() + 加速度模拟 | 需要拟人化滑动绕过反爬。 | ✅ 绕过风控 ❌ 实现复 |
训练模型
安装
pip install torch torchvision torchaudio captcha使用
优点分析
| 优点 | 说明 | 示例/场景 |
|---|---|---|
| 高精度识别 | 深度学习模型(如CNN、LSTM)能捕捉复杂特征,对扭曲、噪声验证码表现优异。 | 识别扭曲文字、干扰线、背景噪声的验证码。 |
| 端到端训练 | 无需手动设计特征,原始图像输入即可输出识别结果。 | 使用 torchvision.transforms 直接处理图像,模型自动学习特征。 |
| 灵活架构 | PyTorch动态图机制便于调试和自定义模型结构。 | 结合CNN(提取特征)+ LSTM(处理序列)处理滑动验证码轨迹。 |
| GPU加速 | 利用CUDA大幅提升训练和推理速度。 | 使用 model.to('cuda') 将模型和数据移至GPU。 |
| 预训练模型迁移 | 可微调ResNet、EfficientNet等预训练模型,节省训练时间。 | 对小样本验证码数据,冻结部分层进行微调。 |
| 多任务支持 | 同时处理验证码分类、目标检测(如滑块位置)等任务。 | YOLOv8检测滑块位置 + CNN分类字符。 |
缺点及挑战
| 缺点 | 问题说明 | 解决方案 |
|---|---|---|
| 数据需求量大 | 需大量标注数据训练,人工标注成本高。 | - 数据增强(旋转、噪声等) - 生成合成验证码(使用 captcha 库)。 |
| 过拟合风险 | 小数据集易导致模型泛化能力差。 | - 添加Dropout层 - 使用早停法( EarlyStopping)。 |
| 计算资源消耗高 | 复杂模型训练需GPU支持,边缘设备部署困难。 | - 模型轻量化(如MobileNet) - 量化( torch.quantization)。 |
| 对抗攻击敏感 | 对抗样本(轻微扰动)可误导模型输出错误结果。 | - 对抗训练(Adversarial Training) - 输入规范化。 |
| 动态验证码难处理 | 对动态切换的验证码(如点选文字、滑块轨迹)需额外处理逻辑。 | - 结合OpenCV动态检测 - 使用Reinforcement Learning模拟滑动。 |
| 模型解释性差 | 黑盒特性导致难以分析错误原因。 | - 可视化注意力图(Grad-CAM) - 输出中间特征。 |
打码平台
使用第三方打码平台,根据条数来扣钱,解析失败不扣钱。打码平台太多了网上搜一下全是。可以自己注册一个试试 我这儿穷鬼一个就试试免费的了,记住关注超级鹰公众号他会送你1000积分够你测试用的了,第三方还是蛮好用的。
-
超级鹰(我注册了,代码中的例子都是从官网直接下载的证明是可以的)
-
云打码
-
若快打码
方式对比
| 方法 | 优点 | 缺点 | 适用场景 | 识别准确率 | 成本 | 速度 |
|---|---|---|---|---|---|---|
| OCR(如Tesseract) | 1. 开源免费 2. 部署简单 3. 对简单文字验证码有效 | 1. 对扭曲、干扰线验证码效果差 2. 无法处理复杂验证码 3. 依赖预处理(二值化等) | 简单的数字/字母验证码(无干扰) | 低-中(30-70%) | 免费 | 快 |
| OpenCV图像处理 | 1. 开源免费 2. 可定制预处理流程(去噪、分割等) 3. 配合OCR可提升效果 | 1. 需要手动调参 2. 复杂验证码仍需人工干预 3. 泛化能力差 | 中等复杂度的验证码(需分割/去噪) | 中(50-80%) | 免费 | 中 |
| 深度学习(CNN/RNN) | 1. 自动学习特征 2. 可处理复杂验证码(滑动、点选等) 3. 高准确率(需足够数据) | 1. 需要大量标注数据 2. 训练成本高 3. 模型维护复杂 | 复杂验证码(如Google reCAPTCHA、行为验证) | 高(80-99%) | 高(GPU成本) | 中-慢(依赖模型大小) |
| 打码平台(如超级鹰) | 1. 无需开发 2. 人工识别准确率高 3. 支持几乎所有验证码类型 | 1. 按次收费(长期成本高) 2. 依赖第三方服务 3. 可能有延迟 | 1. 临时需求 2. 极高准确率要求 3. 无法自研的情况 | 极高(95-99%) | 按次收费(0.5-5元/次) | 依赖网络(通常3-10秒) |
IP代理
注册快代理然后根据提示来即可 这部分也是注册有时效性12个小时,自己注册试试吧。
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36'
}
# 基础写法在添加延迟
proxies = {
'http': 'http://ip1:port1',
'https': 'https://ip2:port2'
}
# 添加多个ip地址即可
response = requests.get(url, proxies=proxies, headers=headers)
import time
import random
time.sleep(random.uniform(1, 3)) # 随机延迟1-3秒抓包工具
概念
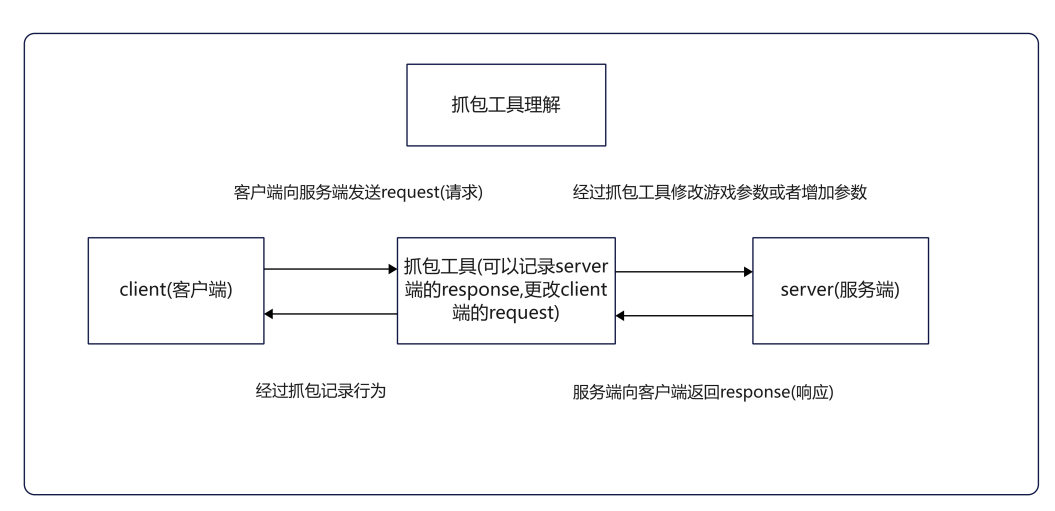
抓包工具的主要作用是捕获、分析和修改网络数据包,用于网络调试、安全测试、性能优化和协议研究等场景
理解
常用抓包工具
Wireshark
概念
官网:一款开源的网络协议分析工具,可以捕获、解析、显示网络数据包。(讲解建议听一下“技术爬爬虾”这个作者讲的很详细,抖音或者youtube都可以搜索到,需要时间消化知识太多了我还没缓过来,先直接简单了解命令和使用),wireshark免费,开源。
安装
官网下载,下载后如果安装到C盘没什么说的如果不是C盘,cmd命令wireshark --version 即可查看,如果不是命令将自定义的位置增加到path即可,命令不知道使用wireshark --help即可查看所有命令。
使用
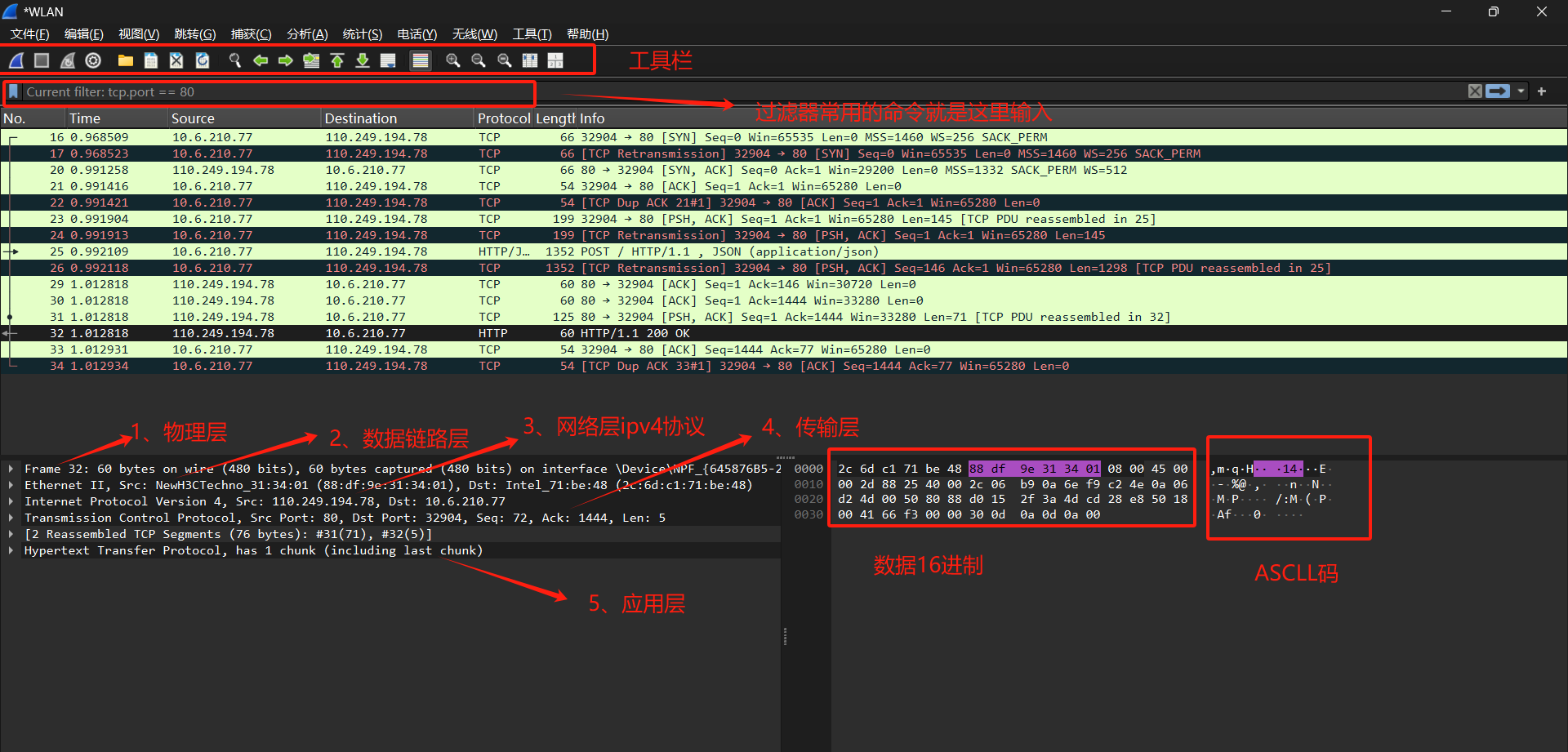
启动:cmd中输入wireshark即可调用起来。
常用命令
这里说的常用命令是过滤那边的命令哈
| 命令/过滤表达式 | 作用 | 示例 | 适用场景 |
|---|---|---|---|
http | 过滤所有 HTTP 流量 | http | Web 调试、API 分析 |
tcp.port == 80 | 抓取 TCP 80 端口(HTTP)流量 | tcp.port == 80 | HTTP 服务监控 |
ip.addr == x.x.x.x | 过滤特定 IP 的流量(源或目标) | ip.addr == 192.168.1.1 | 定位主机通信 |
tcp | 只显示 TCP 协议流量 | tcp | TCP 连接分析 |
udp | 只显示 UDP 协议流量 | udp | DNS/VoIP/游戏流量分析 |
dns | 抓取 DNS 查询/响应 | dns | 域名解析问题排查 |
icmp | 抓取 Ping/ICMP 包 | icmp | 网络连通性测试 |
tcp.flags.syn == 1 | 抓取 TCP SYN 包(扫描或握手分析) | tcp.flags.syn == 1 | 端口扫描检测 |
tcp.stream eq <编号> | 分析指定 TCP 会话流 | tcp.stream eq 0 | 单次会话完整追踪 |
frame contains "关键词" | 抓取包含关键词的明文数据 | frame contains "password" | 敏感信息泄露检测 |
ssl | 抓取 SSL/TLS 流量(需配置密钥解密) | ssl | HTTPS 调试 |
http.request.method == "GET" | 过滤 HTTP GET 请求 | http.request.method == "GET" | 特定请求类型分析 |
tcp.analysis.retransmission | 检测 TCP 重传(网络丢包) | tcp.analysis.retransmission | 网络延迟/拥塞排查 |
ip.src == x.x.x.x && ip.dst == y.y.y.y | 组合条件过滤 | ip.src == 192.168.1.1 && tcp.port == 443 | 精准定位流量 |
!(arp or icmp or dns) | 排除干扰协议(ARP/ICMP/DNS) | !(arp or dns) | 聚焦核心业务流量 |
sip 或 rtp | 抓取 VoIP 语音流量(SIP/RTP) | rtp | 语音通话质量分析 |
dhcp | 抓取 DHCP 请求/分配过程 | dhcp | IP 地址分配问题 |
http.content_type contains "octet-stream" | 过滤文件下载流量 | http.content_type contains "zip" | 文件传输监控 |
Fiddler
概念
官网:Fiddler 是一款 HTTP/HTTPS 抓包与调试工具。
作用
-
Web 开发调试:捕获浏览器、移动端的 HTTP/HTTPS 请求和响应。
-
API 测试:查看和修改接口数据(GET/POST/PUT 等)。
-
性能分析:统计请求耗时、流量大小。
-
安全测试:拦截和篡改数据包(如修改参数、测试漏洞)。
安装
直接下载网盘上的吧,或者根据这个“网络抓包与爬虫”的下载和安装即可。网上看了很多这个哥们写的测试可用,其他的官网或者什么的下载免费的很费劲,别试了浪费时间。
使用
cmd安装后配置path,使用命令fiddler即可启动。
常用命令
| 命令/操作 | 作用 | 示例/用法 | 适用场景 |
|---|---|---|---|
F12(启动/停止捕获) | 开始或停止抓包 | 点击界面右上角 Capturing 按钮 | 基础抓包控制 |
Clear All | 清空当前捕获的所有会话 | 快捷键 Ctrl + X 或右键菜单 | 清理旧数据重新抓包 |
Filter 面板 | 按域名、状态码等过滤流量 | 勾选 Show only the following Hosts,输入 example.com | 聚焦目标网站流量 |
Inspectors 标签页 | 查看请求/响应的详细内容(Headers、JSON等) | 选中会话 → 查看 Headers 或 JSON 标签 | 调试 API 接口 |
Composer 标签页 | 手动构造和发送 HTTP 请求 | 输入 URL、Method(GET/POST),点击 Execute | 模拟客户端请求 |
AutoResponder | 拦截请求并返回自定义响应 | 添加规则:example.com/api → 映射到本地 test.json | 模拟接口响应或前端资源替换 |
Rules > Customize Rules | 编写 FiddlerScript 脚本扩展功能 | 修改 OnBeforeRequest 函数篡改请求 | 动态修改请求/响应逻辑 |
Breakpoints(断点) | 暂停请求/响应以手动修改内容 | 菜单栏 Rules > Automatic Breakpoints > Before Requests | 调试请求篡改漏洞 |
Timeline 视图 | 可视化请求时间轴(性能分析) | 查看请求瀑布图,分析加载瓶颈 | 优化网页性能 |
Log HTTP/3 Traffic | 捕获 HTTP/3(QUIC)流量(需配置) | 勾选 Preferences > HTTP/3 | 调试 HTTP/3 协议 |
Decrypt HTTPS Traffic | 解密 HTTPS 流量(需安装证书) | Tools > Options > HTTPS → 勾选所有选项 | 分析加密流量 |
Stream 模式 | 实时流模式(默认缓冲模式关闭) | 取消勾选 File > Capture Traffic 的缓冲选项 | 监控实时流媒体数据 |
常用抓包工具对比
| 工具名称 | 类型 | 热度 | 适用场景 | 特点 |
|---|---|---|---|---|
| Wireshark | 通用抓包 | ★★★★★ | 网络分析、协议调试、安全审计 | 开源跨平台,支持千种协议解码,图形化界面强大,适合深度分析 |
| Fiddler | HTTP/HTTPS代理 | ★★★★☆ | Web开发、API调试、移动端抓包 | 易用性强,支持HTTPS解密,可修改请求/响应,Windows为主(有跨平台版本) |
| Charles | HTTP/HTTPS代理 | ★★★★ | Web/移动端调试、接口测试 | 类似Fiddler但支持macOS更好,可视化强,收费工具 |
| Burp Suite | Web安全测试 | ★★★★☆ | 渗透测试、Web安全审计 | 专业级Web漏洞扫描,支持拦截修改请求,社区版免费(Pro版收费) |
| tcpdump | 命令行抓包 | ★★★★ | 服务器/网络设备调试、无GUI环境 | Linux/Unix默认工具,轻量高效,需配合Wireshark分析 |
| mitmproxy | HTTPS代理 | ★★★☆ | 安全测试、自动化流量拦截 | 开源命令行工具,支持Python脚本扩展,适合开发/测试人员 |
| Postman | API调试 | ★★★★ | API开发、接口测试 | 非传统抓包工具,但集成代理捕获功能,适合前后端联调 |
| TShark | 命令行分析 | ★★★ | Wireshark命令行版 | 适合自动化处理抓包数据,与脚本集成 |
| Proxyman | HTTP/HTTPS代理 | ★★★ | macOS/iOS开发 | 类似Charles的轻量工具,对Apple生态优化 |
| Omnipeek | 网络分析 | ★★☆ | 企业级网络监控 | 商业工具,深度协议分析,多用于大型网络诊断 |
代码位置day29下的captcha文件夹,29天下的其他文件为爬虫练习项目。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









