







目录
回顾Mybatis和新对象
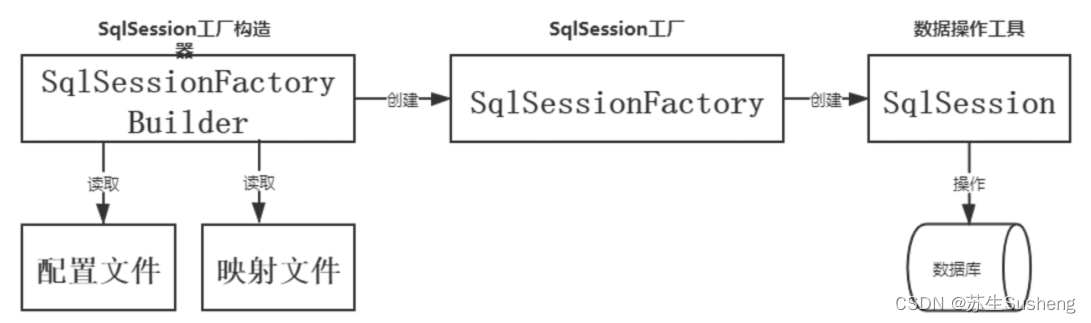
倒着来看
- 执行mapper.xml中的SQL需要先有sqlSession对象
- sqlSession对象需要sqlSessionFactory创建
- sqlSessionFactory需要SqlSessionFactoryBuilder创建
- SqlSessionFactoryBuilder需要自己new出来
- 即使是sqlSession对象,在使用时也是跟业务代码紧耦合的
思路整理
- spring解决的就是手动new 对象和紧耦合的问题,何况Mybatis核心中的这些对象呢!
- 以上流程可以全部移交给Spring来处理
- 读取配置文件、组件的创建、组件之间的依赖关系以及整个框架的生命周期都由Spring容器统一管理
- Spring框架整合其他框架的本质就是通过IOC和AOP把其他框架交给Spring框架管理,最终建立一个低耦合的应用架构
Spring和MyBatis的整合步骤
1. 创建Web工程,导入Spring和MyBatis的相关依赖
<!--数据库驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<!-- 阿里数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.9</version>
</dependency>
<!--Mybatis-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.2</version>
</dependency>
<!--日志包-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
<scope>provided</scope>
</dependency>
<!-- spring -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>5.1.9.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.1.9.RELEASE</version>
</dependency>
<!-- aop依赖 -->
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.9.6</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.1.9.RELEASE</version>
</dependency>
<!-- spring+mybatis整合 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>2.0.2</version>
</dependency>
2. 建立开发目录结构,创建实体类
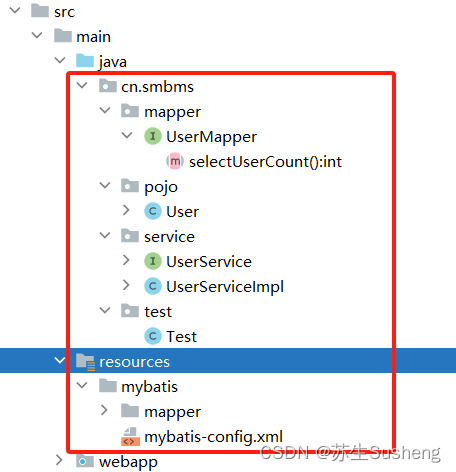
package cn.smbms.pojo;
import lombok.Data;
import lombok.ToString;
import java.io.Serializable;
import java.util.Date;
/**
* @author: zjl
* @datetime: 2024/3/23
* @desc:
*/
@Data
@ToString
public class User implements Serializable {
private long id;
private String userCode;
private String userName;
private String userPassword;
private int gender;
private Date birthday;
private String phone;
private String address;
private int userRole;
}
3. 创建数据访问接口和SQL映射语句文件
package cn.smbms.mapper;
public interface UserMapper {
int selectUserCount();
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.smbms.mapper.UserMapper">
<select id="selectUserCount" resultType="int">
SELECT COUNT(1) FROM SMBMS_USER
</select>
</mapper>
4. 使用Spring配置文件配置数据源
4.1 database.properties
jdbc.driverClassName = com.mysql.jdbc.Driver
jdbc.url = jdbc:mysql://localhost:3306/smbms?useSSL=false&characterEncoding=utf-8
jdbc.username = root
jdbc.password = 123456
maxActive=20
initialSize=1
maxWait=60000
minIdle=1
timeBetweenEvictionRunsMillis=60000
minEvictableIdleTimeMillis=300000
testWhileIdle=true
testOnBorrow=false
testOnReturn=false
filters=stat
4.2spring配置文件applicationContext.xml
<!--引入properties文件-->
<bean class="org.springframework.context.support.PropertySourcesPlaceholderConfigurer">
<property name="location">
<value>classpath:database.properties</value>
</property>
</bean>
<!--配置DataSource-->
<!-- <bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">-->
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close">
<property name="driverClassName" value="${jdbc.driverClassName}" />
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<!--最大连接池数量-->
<property name="maxActive" value="${maxActive}" />
<!--初始化时建立物理连接的个数-->
<property name="initialSize" value="${initialSize}" />
<!--获取连接时最大等待时间,单位毫秒-->
<property name="maxWait" value="${maxWait}" />
<!--最小连接池数量-->
<property name="minIdle" value="${minIdle}" />
<!--检测连接是否有效的超时时间,单位:秒-->
<property name="timeBetweenEvictionRunsMillis" value="${timeBetweenEvictionRunsMillis}" />
<!--连接保持空闲而不被驱逐的最小时间-->
<property name="minEvictableIdleTimeMillis" value="${minEvictableIdleTimeMillis}" />
<!--申请连接的时候检测-->
<property name="testWhileIdle" value="${testWhileIdle}" />
<!--申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。-->
<property name="testOnBorrow" value="${testOnBorrow}" />
<!--归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。-->
<property name="testOnReturn" value="${testOnReturn}" />
<!--属性类型是字符串,通过别名的方式配置扩展插件-->
<property name="filters" value="${filters}" />
</bean>
5. 使用Spring配置文件创建SqlSessionFactory
<!-- 配置SqlSessionFactoryBean -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<!-- 引用数据源组件 -->
<property name="dataSource" ref="dataSource" />
<!-- 引用MyBatis配置文件中的配置 -->
<property name="configLocation" value="classpath:mybatis/mybatis-config.xml" />
<!-- 配置SQL映射文件信息 -->
<property name="mapperLocations">
<list>
<value>classpath:mybatis/mapper/*.xml</value>
</list>
</property>
</bean>
6. 配置MyBatis应用配置文件mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- Mybatis核心配置文件 -->
<configuration>
<settings>
<setting name="logImpl" value="LOG4J"/>
</settings>
<typeAliases>
<package name="cn.smbms.pojo"/>
</typeAliases>
</configuration>
7. 创建业务接口和业务实现类
package cn.smbms.service;
public interface UserService {
int getUserCount();
}
package cn.smbms.service;
import cn.smbms.mapper.UserMapper;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
/**
* @author: zjl
* @datetime: 2024/4/16
* @desc:
*/
@Service
public class UserServiceImpl implements UserService{
@Resource
private UserMapper userMapper;
@Override
public int getUserCount() {
return userMapper.selectUserCount();
}
}
8.配置扫描扫描service层bean
<context:component-scan base-package="cn.smbms.service"/>
9.配置MapperScannerConfigurer
自动扫描指定包下的Mapper接口,并将它们直接注册为MapperFactoryBean

<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.smbms.mapper" />
</bean>
10. 测试
package cn.smbms.test;
import cn.smbms.service.UserService;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
/**
* @author: zjl
* @datetime: 2024/4/16
* @desc:
*/
public class MyTest {
@Test
public void test(){
ApplicationContext act = new ClassPathXmlApplicationContext("applicationContext.xml");
UserService userService = act.getBean(UserService.class);
System.out.println(userService.getUserCount());
}
}
spring整合Mybatis后的事务处理
- 编程式事务:硬编码方式,代码繁琐,且破坏分层,代码不易维护
- 声明式事务:采用AOP的方式实现,Spring提供了声明式事务支持
声明式事务
- 声明式事务关注的核心问题是:对哪些方法,采取什么样的事务策略
- 配置步骤
- 导入tx和aop命名空间
- 定义事务管理器Bean,并为其注入数据源Bean
- 通过<tx:advice>配置事务增强,绑定事务管理器并针对不同方法定义事务规则
- 配置切面,将事务增强与方法切入点组合
示例(配置方式,本章主要用注解来实现声明式事务)
<!-- 使用xml方式实现声明式事务 -->
<tx:advice id="txAdvice">
<tx:attributes>
<tx:method name="get*" propagation="SUPPORTS" />
<tx:method name="add*" propagation="REQUIRED" />
<tx:method name="del*" propagation="REQUIRED" />
<tx:method name="update*" propagation="REQUIRED" />
<tx:method name="*" propagation="REQUIRED" />
</tx:attributes>
</tx:advice>
<!-- 定义切面 -->
<aop:config>
<aop:pointcut id="serviceMethod"
expression="execution(* cn.smbms.service..*.*(..))" />
<aop:advisor advice-ref="txAdvice" pointcut-ref="serviceMethod" />
</aop:config>
<!-- 定义事务管理器 -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"></property>
</bean>
Spring声明式事务对应事务管理器接口
DataSourceTransactionManager类(事务管理器)中的主要方法:
- doBegin():开启事务
- doSuspend():挂起事务
- doResume():恢复挂起的事务
- doCommit():提交事务
- doRollback():回滚事务
注解实现声明式事务
- @Transactional注解添加声明式事务
- 可以加在方法上,表示对该方法实现声明式事务
- 可以加载类上,表示对该类中所有的方法实现声明式事务
@Transactional的工作原理
- @Transactional是基于AOP实现的,AOP又是基于动态代理实现的。
- 如果目标对象实现了接口,默认情况下就会采用JDK的动态代理,如果目标对象没有实现接口,会使用CGLIB的动态代理。
- @Transactional在开始执行业务之前,通过代理先开始事务,在执行成功之后再提交事务。如果中途遇见异常,则回滚事务。
- @Transactional实现思路预览:
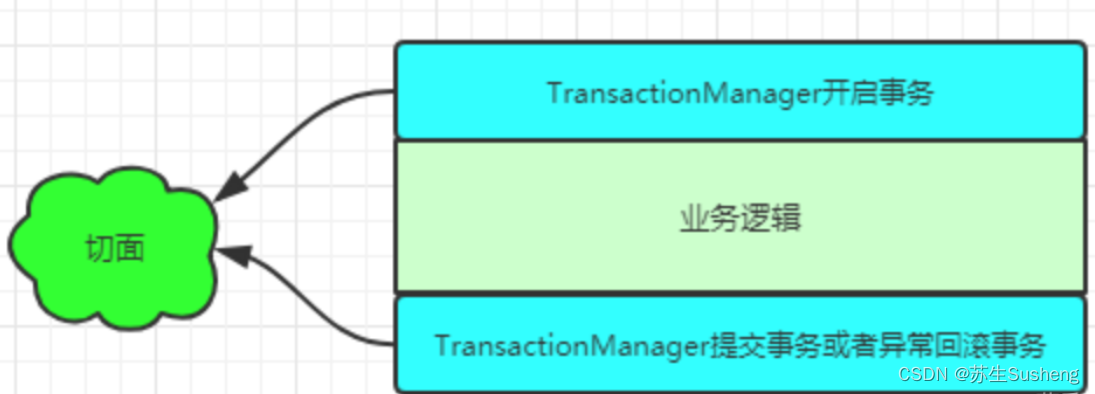
- @Transactional具体执行细节如下图所示:
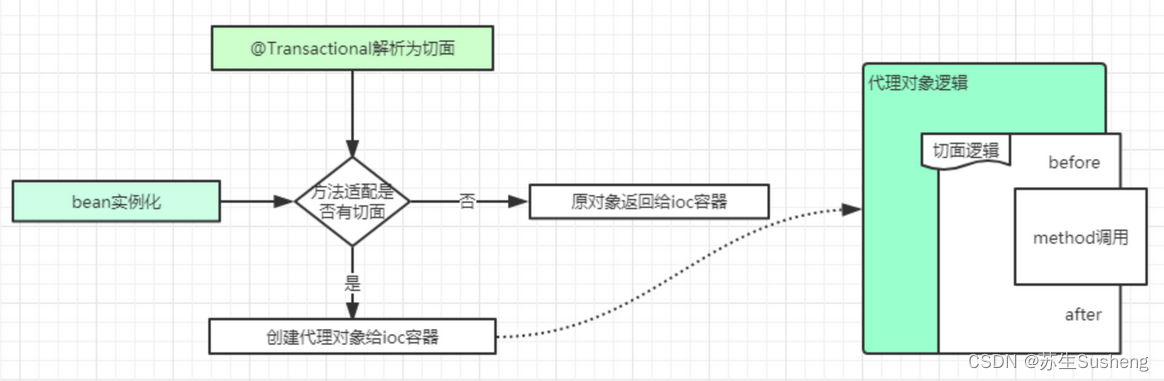
添加注解配置
<!--<tx:advice id="txAdvice">
<tx:attributes>
<tx:method name="get*" propagation="SUPPORTS" />
<tx:method name="add*" propagation="REQUIRED" />
<tx:method name="del*" propagation="REQUIRED" />
<tx:method name="update*" propagation="REQUIRED" />
<tx:method name="*" propagation="REQUIRED" />
</tx:attributes>
</tx:advice>
<!– 定义切面 –>
<aop:config>
<aop:pointcut id="serviceMethod"
expression="execution(* cn.smbms.service..*.*(..))" />
<aop:advisor advice-ref="txAdvice" pointcut-ref="serviceMethod" />
</aop:config>-->
<!-- 定义事务管理器 -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"></property>
</bean>
<!-- 使用注解实现声明式事务 -->
<tx:annotation-driven />
propagation:事务传播机制
事务的传播机制解决的是一个事务在多个节点(方法)中传递的问题:

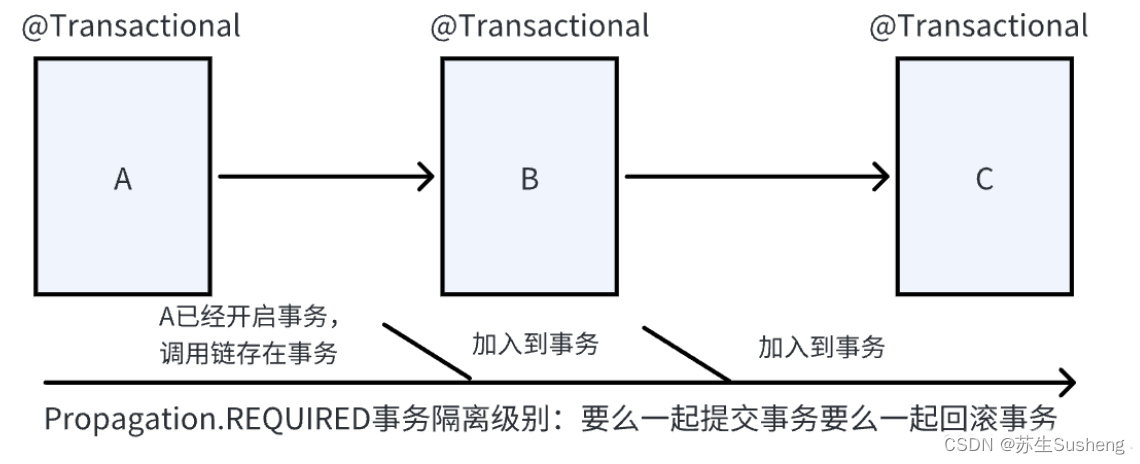
REQUIRED(默认值)
- REQUIRED是默认的事务传播行为。
- 如果当前存在事务,那么该方法将会在该事务中运行;如果当前没有事务,那么它会启动一个新的事务。
@Service
public class ServiceA {
@Autowired
private ServiceB serviceB;
// 使用REQUIRED传播机制
@Transactional(propagation = Propagation.REQUIRED)
public void methodA() {
// 方法A的业务代码...
// 调用方法B
serviceB.methodB();
// 如果methodB出现错误,那么methodA和methodB的操作都会回滚。
}
}
@Service
public class ServiceB {
@Transactional(propagation = Propagation.REQUIRED)
public void methodB() {
// 方法B的业务代码...
}
}
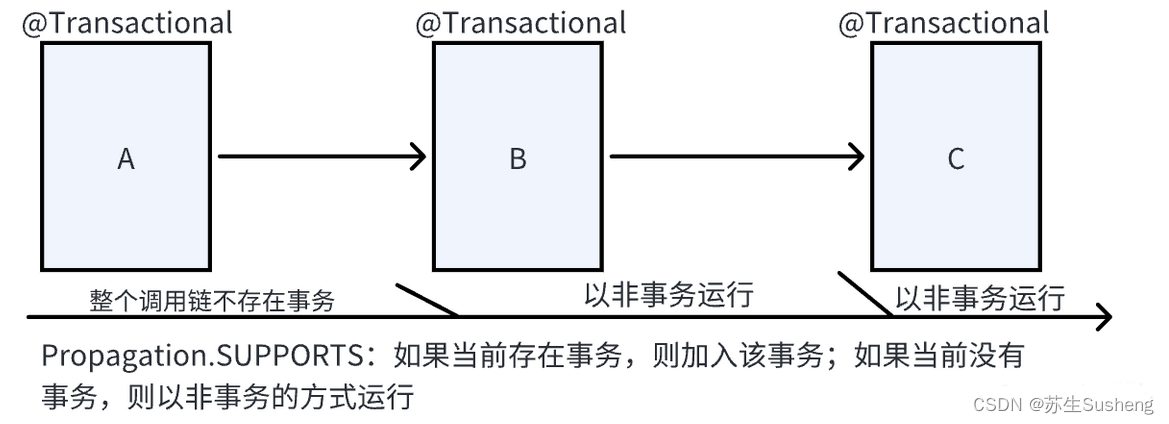
SUPPORTS
如果当前存在事务,那么该方法将会在该事务中运行;如果当前没有事务,那么它可以以非事务方式执行。
@Service
public class ServiceA {
@Autowired
private ServiceB serviceB;
@Transactional(propagation = Propagation.SUPPORTS)
public void methodA() {
// 方法A的业务代码...
serviceB.methodB();
// 无论methodB是否出现错误,methodA的操作都不会回滚。
}
}
@Service
public class ServiceB {
@Transactional(propagation = Propagation.SUPPORTS)
public void methodB() {
// 方法B的业务代码...
}
}
REQUIRES_NEW
REQUIRES_NEW传播行为总是会启动一个新的事务。如果有一个事务正在运行,那么这个事务将会被挂起。
@Service
public class ServiceA {
@Autowired
private ServiceB serviceB;
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void methodA() {
// 方法A的业务代码...
serviceB.methodB();
// methodB在新的事务中运行,无论是否出错,都不会影响methodA的事务。
}
}
@Service
public class ServiceB {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void methodB() {
// 方法B的业务代码...
}
}
MANDATORY
MANDATORY传播行为要求方法必须在一个现有的事务中执行,如果没有事务就抛出异常。
@Service
public class ServiceA {
@Autowired
private ServiceB serviceB;
@Transactional(propagation = Propagation.MANDATORY)
public void methodA() {
// 方法A的业务代码...
serviceB.methodB();
// 如果没有现有事务,会抛出异常。
}
}
@Service
public class ServiceB {
@Transactional(propagation = Propagation.MANDATORY)
public void methodB() {
// 方法B的业务代码...
}
}
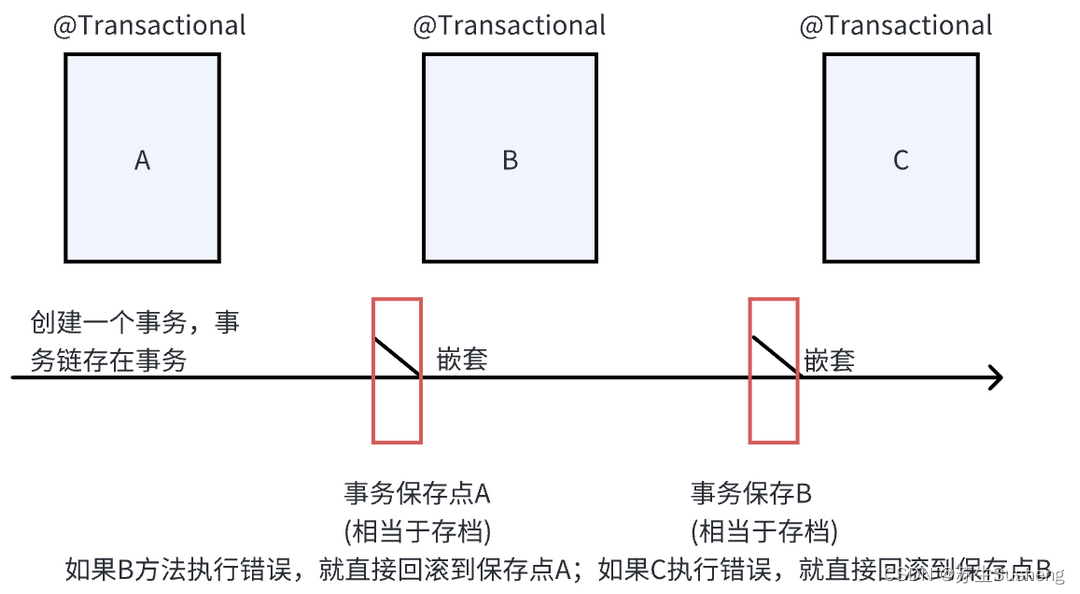
NESTED
NESTED传播行为在一个嵌套事务中执行,如果一个事务正在运行,那么它将在一个嵌套事务中执行。这个嵌套事务是可以独立提交或回滚的。
@Service
public class ServiceA {
@Autowired
private ServiceB serviceB;
@Transactional(propagation = Propagation.NESTED)
public void methodA() {
// 方法A的业务代码...
serviceB.methodB();
// methodB在嵌套事务中运行,如果出错,只有嵌套事务会回滚,不会影响methodA的事务。
}
}
@Service
public class ServiceB {
@Transactional(propagation = Propagation.NESTED)
public void methodB() {
// 方法B的业务代码...
}
}
NOT_SUPPORTED
NOT_SUPPORTED传播行为总是以非事务方式执行,如果有一个事务正在运行,那么这个事务将会被挂起。
@Service
public class ServiceA {
@Autowired
private ServiceB serviceB;
@Transactional(propagation = Propagation.NOT_SUPPORTED)
public void methodA() {
// 方法A的业务代码...
serviceB.methodB();
// 无论methodB是否出错,methodA的操作都不会回滚,因为它们不在同一个事务中。
}
}
@Service
public class ServiceB {
@Transactional(propagation = Propagation.NOT_SUPPORTED)
public void methodB() {
// 方法B的业务代码...
}
}
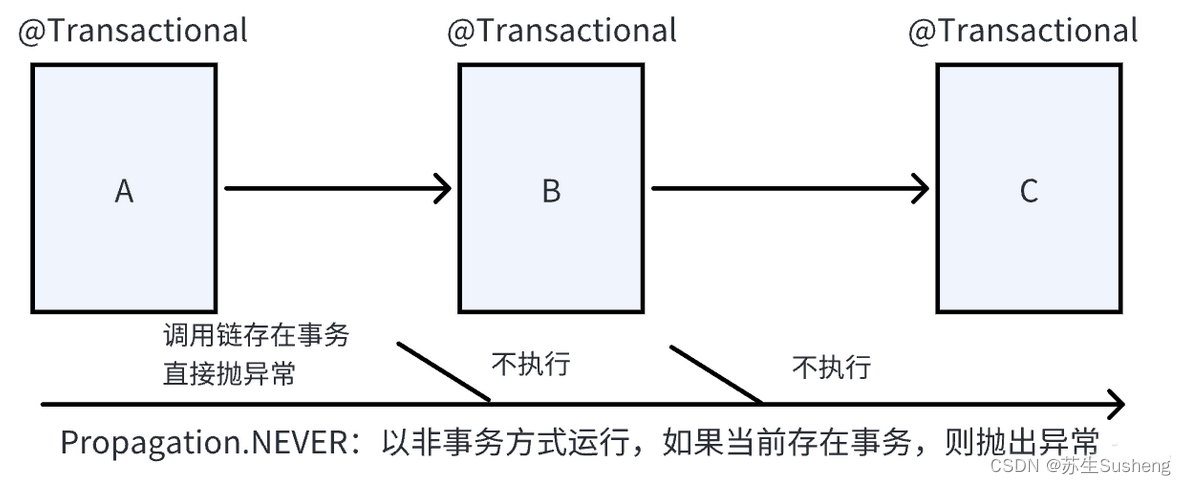
NEVER
NEVER传播行为要求方法以非事务方式执行,如果有一个事务正在运行,将会抛出异常。
@Service
public class ServiceA {
@Autowired
private ServiceB serviceB;
@Transactional(propagation = Propagation.NEVER)
public void methodA() {
// 方法A的业务代码...
serviceB.methodB();
// 如果有事务正在运行,会抛出异常。
}
}
@Service
public class ServiceB {
@Transactional(propagation = Propagation.NEVER)
public void methodB() {
// 方法B的业务代码...
}
}
并发场景下,事务引发的问题
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对统一数据进行操作)。并发虽然是必须的,但是可能会导致以下的问题。
脏读(Dirty Read)
当一个事务正在访问数据并且对数据进行了修改,此时还未提交到数据库中,这时另一个事务也访问并使用了这个数据,由于上个事务还未提交,此时他读到的就是“脏数据”,根据“脏数据”所做的操作可能时不正确的。
产生原因
-
并发事务未提交: 一个事务在进行更新操作但尚未提交时,另一个事务已经读取了被更新的数据。这样读取到的数据就是未提交的“脏数据”。
-
缺乏事务隔离机制: 如果数据库系统的事务隔离级别设置较低,如读取未提交数据(Read Uncommitted),则允许事务读取到其他事务尚未提交的数据,从而导致脏读问题。
解决方案
-
使用事务隔离级别: 将数据库的事务隔离级别设置为合适的级别,如可重复读(Repeatable Read)或串行化(Serializable),这样可以确保一个事务在读取数据时不会读取到其他事务尚未提交的数据,从而避免脏读问题的发生。
-
加锁: 在进行读取操作时,可以使用行级锁或表级锁来锁定数据,防止其他事务对数据进行修改,确保读取到的数据是一致的。
-
优化事务设计: 在设计应用程序时,避免长时间持有事务或数据库连接,尽量缩短事务的执行时间,减少脏读发生的可能性。
-
谨慎使用未提交读(Read Uncommitted): 如果必须使用未提交读隔离级别,应该在应用程序中谨慎使用,并且清楚了解可能带来的风险。
总结
脏读问题可能导致系统产生错误的结果,因此在设计和实现数据库系统时,必须采取适当的措施来防止脏读的发生。通过设置合适的事务隔离级别、加锁以及优化事务设计,可以有效地避免脏读问题,确保系统的数据一致性和完整性
丢失修改(Lost of Modify)
- 指一个事务读取到一个数据,另一个事务也访问了该数据。那么在第一个事务修改了这个数据后,第二个事务也进行了修改,此时第一个事务的修改结果就被覆盖了,也就是丢失了,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
- 当两个或多个事务同时修改同一数据时,后提交的事务可能会覆盖前一个事务所做的修改,导致前一个事务的更新被丢失,这可能会导致数据不一致性或意外的结果
产生原因
- 并发更新: 多个事务同时对同一数据进行更新操作,由于没有正确的并发控制机制,可能导致后提交的事务覆盖了先前事务的修改。
- 缺乏锁机制: 如果系统没有实现有效的锁机制来保护共享数据,不同的事务可能会同时对同一数据进行修改,从而导致丢失更新问题。
解决方案
- 使用锁机制: 引入锁机制,如行级锁或表级锁,可以确保同时只有一个事务可以对特定的数据进行修改操作,从而避免丢失更新的问题。
- 乐观并发控制: 采用乐观并发控制方法,如版本控制或时间戳控制。每个事务在修改数据时,先获取数据的版本信息或时间戳,并在提交时检查数据是否发生变化,如果发生变化则进行回滚或者重新尝试。
- 使用事务隔离级别: 设置合适的事务隔离级别,如可重复读或串行化隔离级别,以确保一个事务在读取和修改数据时,不会被其他事务的更新所影响,从而避免丢失更新问题。
- 应用程序设计: 在应用程序设计阶段,尽量避免长时间持有数据库连接或事务,减少并发操作的可能性,从而减少丢失更新问题的发生。
总结
丢失更新问题在并发事务处理中是一个常见的挑战,但通过合适的并发控制机制和事务管理策略,可以有效地解决这一问题,确保数据的一致性和完整性。数据库管理员和开发人员需要充分了解丢失更新问题的原因和解决方法,并在设计和实现数据库系统时采取相应的措施,以提高系统的稳定性和可靠性。
死锁(Deadlock)
- 两个或多个事务相互等待对方释放资源,导致系统无法继续执行。这种情况下,只能通过终止其中一个事务或者回滚来解决死锁。
产生原因
- 资源竞争: 多个事务同时请求获取相同的资源,但由于资源被其他事务占用而无法立即获取,导致事务之间相互等待。
- 循环等待: 事务之间存在循环的资源依赖关系,每个事务都在等待其他事务所持有的资源,形成了循环等待的局面。
解决方案
-
加锁顺序: 设计良好的应用程序应该按照相同的顺序请求和释放资源,从而降低死锁发生的可能性。通过统一的加锁顺序,可以减少资源竞争和循环等待的情况。
-
超时机制: 引入超时机制,当事务在一定时间内无法获取所需资源时,自动释放已经获取的资源并进行回滚操作,从而打破死锁的局面。
-
检测和回滚: 实现死锁检测算法,定期检测系统中是否存在死锁,并采取自动回滚或者手动干预的方式来解除死锁。
-
事务监控: 监控事务的执行情况,及时发现可能导致死锁的事务,并对其进行优化或者调整,从而降低死锁的发生概率。
总结
死锁是数据库并发处理中的一个重要问题,需要引起开发人员和数据库管理员的高度重视。通过合理设计事务和加锁机制、实现死锁检测和处理算法,以及进行事务监控和优化,可以有效地预防和解决死锁问题,确保数据库系统的稳定性和可靠性。
不可重复读(Unrepeatableread)
一个事务在读取某个数据后,另一个事务修改了该数据并提交。当第一个事务再次读取同一数据时,得到的结果与之前不一致。因此称为不可重复读。
产生原因
- 并发事务更新: 当一个事务在读取数据后,另一个事务对同一行数据进行了更新操作,导致第一个事务在后续读取同一行数据时,得到了不一致的结果。
- 并发事务删除: 当一个事务在读取数据后,另一个事务对同一行数据进行了删除操作,导致第一个事务在后续读取同一行数据时,发现数据已经不存在了。
解决方案
-
使用合适的事务隔离级别: 将数据库的事务隔离级别设置为合适的级别,如可重复读(Repeatable Read)或串行化(Serializable),这样可以确保一个事务在读取数据时,不会受到其他事务的更新或删除操作的影响,从而避免不可重复读问题的发生。
-
加锁: 在进行读取操作时,可以使用行级锁或表级锁来锁定数据,防止其他事务对数据进行修改或删除,确保读取到的数据是一致的。
-
优化事务设计: 在设计应用程序时,尽量减少事务的持续时间,缩短事务执行的时间窗口,从而减少并发操作对数据的影响。
总结
不可重复读问题可能导致系统产生不一致的结果,因此在设计和实现数据库系统时,必须采取适当的措施来防止不可重复读的发生。通过设置合适的事务隔离级别、加锁以及优化事务设计,可以有效地避免不可重复读问题,确保系统的数据一致性和完整性。
幻读(Phantom read)
幻读与不可重复读类似,它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
产生原因
-
并发事务插入或删除: 当一个事务在查询数据后,另一个事务对相同的条件的数据进行了插入或删除操作,导致第一个事务在后续查询相同条件的数据时,发现了新增或减少的数据,产生了幻读现象。
-
并发事务更新: 当一个事务在查询数据后,另一个事务对相同条件的数据进行了更新操作,导致第一个事务在后续查询相同条件的数据时,发现了数据内容的改变,也会产生幻读问题。
解决方案
-
使用合适的事务隔离级别: 将数据库的事务隔离级别设置为合适的级别,如串行化(Serializable),这样可以确保一个事务在读取数据时,不会受到其他事务的插入、更新或删除操作的影响,从而避免幻读问题的发生。
-
使用行级锁或范围锁: 在进行查询操作时,可以使用行级锁或范围锁来锁定数据,防止其他事务对数据进行插入、更新或删除操作,确保查询到的数据集是一致的。
-
优化事务设计: 在设计应用程序时,尽量减少事务的持续时间,缩短事务执行的时间窗口,从而减少并发操作对数据的影响,降低出现幻读问题的可能性。
总结
- 幻读问题可能导致系统产生不一致的结果,因此在设计和实现数据库系统时,必须采取适当的措施来防止幻读的发生。通过设置合适的事务隔离级别、使用锁机制以及优化事务设计,可以有效地避免幻读问题,确保系统的数据一致性和完整性。
- 不可重复度和幻读的区别:不可重复读的重点是修改,幻读的重点在于新增或者删除。
- 例1(同样的条件, 你读取过的数据, 再次读取出来发现值不一样了 ):事务1中的A先生读取自己的工资为 1000的操作还没完成,事务2中的B先生就修改了A的工资为2000,导 致A再读自己的工资时工资变为 2000;这就是不可重复读。
- 例2(同样的条件, 第1次和第2次读出来的记录数不一样 ):假某工资单表中工资大于3000的有4人,事务1读取了所有工资大于3000的人,共查到4条记录,这时事务2 又插入了一条工资大于3000的记录,事务1再次读取时查到的记录就变为了5条,这样就导致了幻读。
Spring声明式事务中的事务隔离:isolation
事务隔离级别:解决的是多个事务同时调用数据库的问题

DEFAULT(默认值)
READ_COMMITTED:读已提交
允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
READ_UNCOMMITTED:读未提交
最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
REPEATABLE_READ:可重复读
对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
SERIALIZABLE:可串行化
最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
√:会出现,×:不会出现
| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|---|---|---|---|
| READ-UNCOMMITTED | √ | √ | √ |
| READ-COMMITTED | × | √ | √ |
| REPEATABLE-READ | × | × | √ |
| SERIALIZABLE | × | × | × |
补充
- MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)
- 需要注意的是:与 SQL 标准不同的地方在于InnoDB 存储引擎在 REPEATABLE-READ(可重读) 事务隔离级别下,允许应用使用 Next-Key Lock 锁算法来避免幻读的产生。这与其他数据库系统(如 SQL Server)是不同的。所以说虽然 InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读) ,但是可以通过应用加锁读(例如 select * from table for update 语句)来保证不会产生幻读,而这个加锁度使用到的机制就是 Next-Key Lock 锁算法。从而达到了 SQL 标准的 SERIALIZABLE(可串行化) 隔离级别。
- 因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是READ-COMMITTED(读取提交内容):,但是你要知道的是InnoDB 存储引擎默认使用 REPEATABLE-READ(可重读) 并不会有任何性能损失。
- InnoDB 存储引擎在 分布式事务 的情况下一般会用到SERIALIZABLE(可串行化) 隔离级别。
事务属性
- timeout:事务超时时间,允许事务运行的最长时间,以秒为单位。默认值为-1,表示不超时
- read-only:事务是否为只读,默认值为false
- rollback-for:设定能够触发回滚的异常类型
- Spring默认只在抛出runtime exception时才标识事务回滚
- 可以通过全限定类名指定需要回滚事务的异常,多个类名用逗号隔开
- no-rollback-for:设定不触发回滚的异常类型
- Spring默认checked Exception不会触发事务回滚
- 可以通过全限定类名指定不需回滚事务的异常,多个类名用英文逗号隔开
| 属性 | 类型 | 说明 |
|---|---|---|
| propagation | 枚举型:Propagation | 可选的传播性设置。使用举例: @Transactional(propagation=Propagation.REQUIRES_NEW) |
| isolation | 枚举型:Isolation | 可选的隔离性级别。使用举例: @Transactional(isolation=Isolation.READ_COMMITTED) |
| readOnly | 布尔型 | 是否为只读型事务。使用举例:@Transactional(readOnly=true) |
| timeout | int型(以秒为单位) | 事务超时。使用举例:Transactional(timeout=10) |
| rollbackFor | 一组 Class 类的实例,必须是Throwable的子类 | 一组异常类,遇到时 必须 回滚。使用举例:@Transactional(rollbackFor={SQLException.class}),多个异常用逗号隔开 |
| rollbackForClassName | 一组 Class 类的名字,必须是Throwable的子类 | 一组异常类名,遇到时 必须 回滚。使用举例:@Transactional(rollbackForClassName={“SQLException”}),多个异常用逗号隔开 |
| noRollbackFor | 一组 Class 类的实例,必须是Throwable的子类 | 一组异常类,遇到时 必须不 回滚 |
| noRollbackForClassName | 一组 Class 类的名字,必须是Throwable的子类 | 一组异常类名,遇到时 必须不 回滚 |















 5739
5739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









