







MySQL通过B+树来实现索引。
B+树
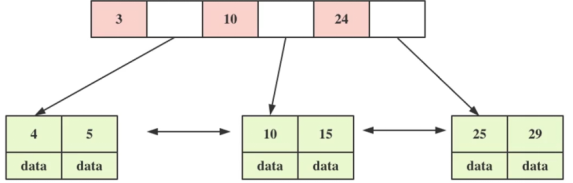
- 1.n叉树,每一级可以存储多个节点,降低了树的高度
- 2.非叶子节点只存储key,不存储数据
- 叶子节点存储key和数据
- 叶子节点的内部,存在多条数据,根据索引进行了有序排列,满足了范围查找
- 叶子节点之间通过一个双向链表,进行相互连接
- 索引失效的情况下,可以按照叶子节点进行顺序遍历
- B+Tree每次建立一个节点的同时,直接申请一个页的空间,将一个节点的大小设为等于一个页
- 这样每个节点只需要一次I/O就可以完全载入。
索引
- 索引查找过程中,产生磁盘I/O消耗,而I/O速度相当之慢
- 换句话说,索引的机构组织要尽量减少查找过程中磁盘I/O的存取次数,减少磁盘IO的次数能很大程度的提高MySQL性能。
- 页
- 从磁盘读取数据时,系统会将逻辑地址发给磁盘,磁盘将逻辑地址转换为物理地址-哪个磁道,哪个扇区。磁头进行进行机械运动,先找到相应磁道,再找该磁道的对应扇区,扇区是磁盘的最小存储单元。
- 主存和磁盘以页为单位交换数据,通常为4KB大小。
需要查找key为6的数据

- 1. 将磁盘块0加载到内存,发生一次IO,在内存中用二分查找确定6在3和9之间;
- 2. 通过指针P2的磁盘地址,将磁盘2加载到内存,发生第二次IO,再在内存中进行二分查找找到6,结束
- 3. 这里只进行了两次IO,实际上,每个页块大小为4K,3层的B+树就可以表示上百万的数据,也就是每次查找最多3次IO,所以索引对性能的提高将是巨大的
为什么不用哈希索引(因为是一个散列的情况,并没有进行一个顺序地存储)
- 1. 哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序,不支持任何范围查询,例如WHERE price > 100(需要对每一条数据都进行hash操作,几乎是遍历整张表了,所以性能会很低,基本没什么提高)
- 2. 当出现哈希冲突的时候,存储引擎必须遍历链表中所有的行指针,逐行进行比较,直到找到所有符合条件的行数据。















 685
685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









