







目录
ES底层索引原理
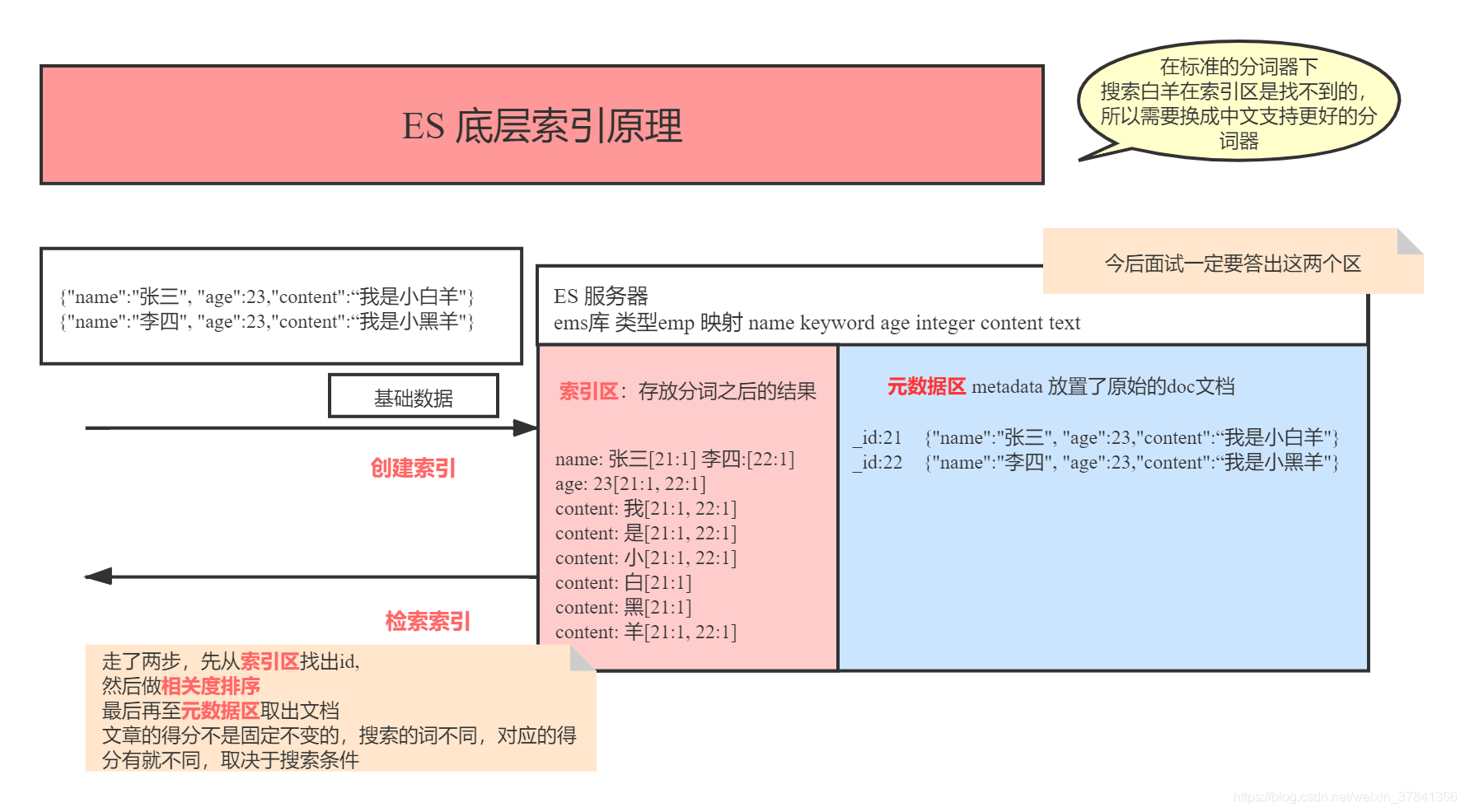
IK分词器
1. 定义:就是将一本文本中关键词拆分出来
我是小明的同学 分词器 小明 同学
分词原理: 拆分关键字 去掉停用词 和 停用词
2. ES中提供分词器
1. 默认 标准分词器 standard analyzer 英文:单词分词 中文:单字分词
2.简单 simple analyzer 英文:单词分词 去掉数字 中文:不分词
3. 测试不同的分词器
GET /_analyzer
{
"analyzer":"simple",
"text":"redis 非常好用 111"
}- standard 分词结果为 : redis 非 常 好 用 111
- simple 分词结果为: redis 非常好用
4.github 基于ES分词器IK分词器
注意:使用IK分词器和ES版本必须严格一致
5. ik_max_word和ik_smart什么区别?
- ik_max_word:会将文本做最细粒度的拆分,比如会将"我是小明的同学"拆分为"我是小明的同学", "我是","我是小明","小明的同学","同学",会穷尽各种可能的组合我是小明的同学
- ik_smart:会做最粗粒度的拆分,比如会将"我是小明的同学",拆分为"我是小明的同学”
PUT /emp
{
"mappings":{
"emp":{
"properties":{
"name":{
"type":"text",
"analyzer":"ik_max_word"
},
"age":{
"type":"integer"
},
"bir":{
"type":"date"
},
"content":{
"type":"text",
"analyzer":"ik_max_word"
},
"address":{
"type":"keyword"
}
}
}
}
}IK中自定义配置扩展词和停用词
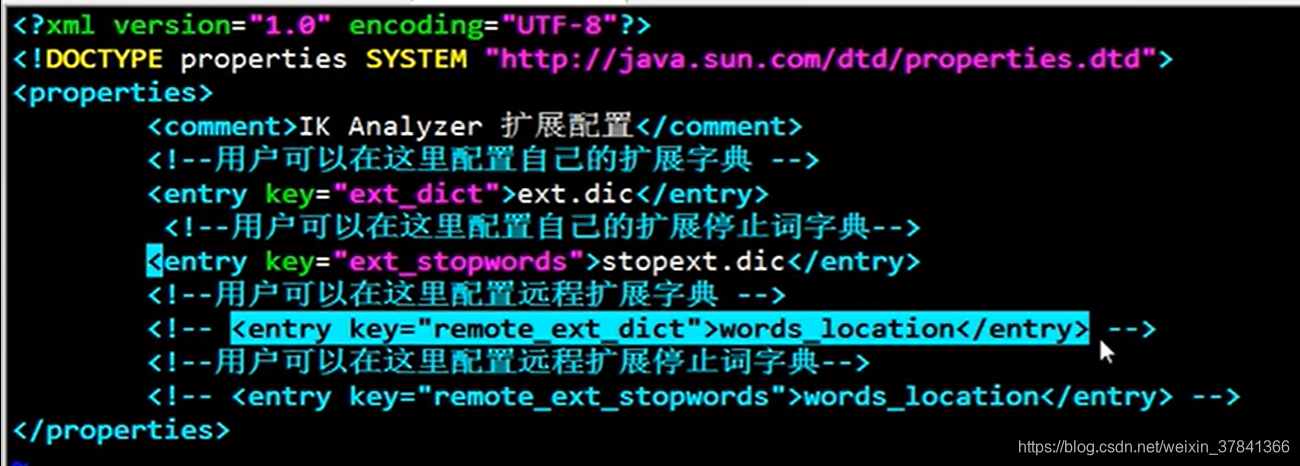
1. 扩展词
定义:现有ik分词器无法将这个词切分成一个关键词,但是又希望某个词成为关键词
ik 分词器 等都可以被拆分成关键词,比如一些热门流行的网络词
配置IK的配置文件: ES安装目录下/plugins/ik/config 目录中名字 :IKAnalyzer.cfg.xml
修改配置文件加入如下配置:
<!--用户可以在这里配置自己的扩展字典>
<entry key="ext_dict">ext.dic</entry>
2. 停用词
定义:现有ik分词器将一个关键词切分成一个词,但是出于某种原因这个词不能作为关键词出现
<entry key="ext_stopwords">stopext.dic</entry>
3.配置远程扩展词典
ES中Query
1. Query String ! Query DSL查询
关键词查询 -----> 计算得分 排序 等一系列
2. Filter Quey 过滤查询 效率比较高
筛选出符合条件的数据 --------> 不会计算文档 得分 排序, 常用Filter 自动常用fiter结果
必须使用bool表达式将两种query组合在一起
注意:当filterQuery 和query组合使用时先执行fiterQuery中语句 然后再去执行query中语句
过滤适合在大范围筛选数据,而查询则适合精确匹配数据。一般应用时,应先使用过滤数据,然后使用查询匹配数据。















 1933
1933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









