







A2C Advantage Actor-Critic
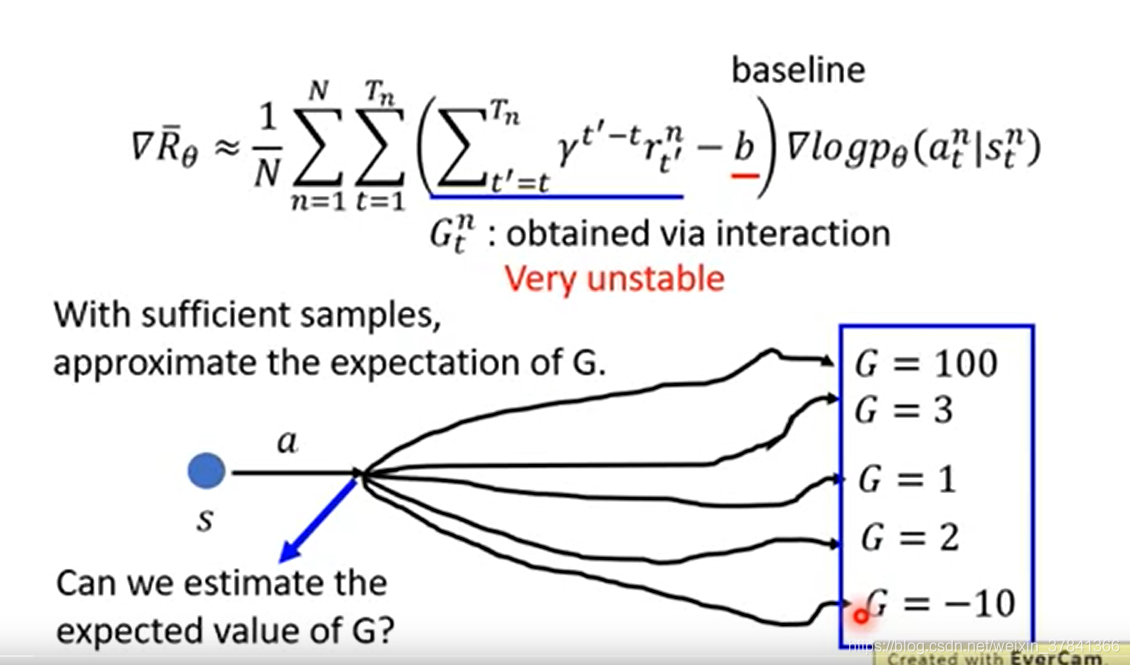
是一个随机变量,在采样数据不非常充足的情况下,方差会很大,如何提高训练的稳定性呢?直接估算G的期望值, 让期望值去代替采样到的值。
在Q-learning中有两种Critic
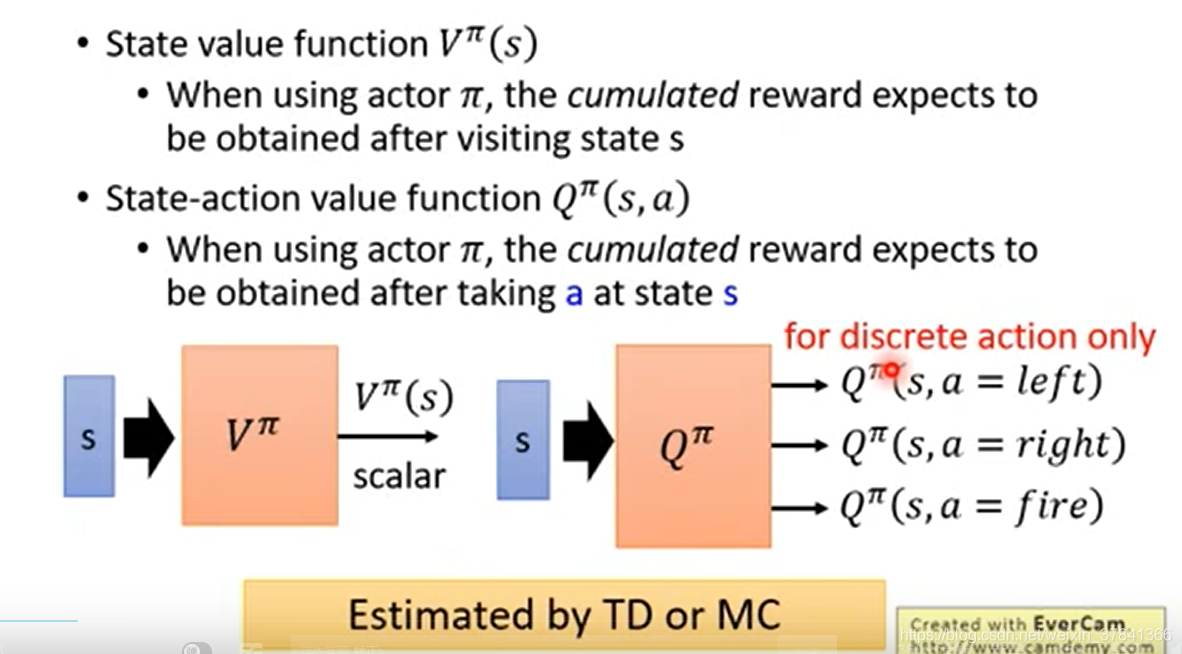
用MC会更精确但TD会更稳定。

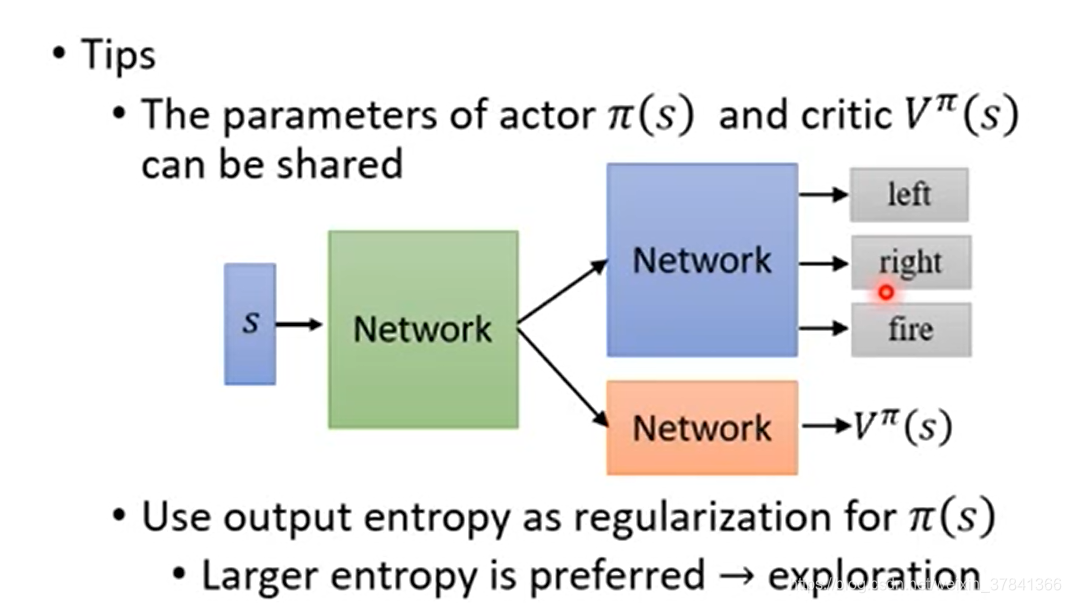
上图在实做时需要训练两个网络Q和V, 更大可能性的引入估算的偏差, 如何转换为只估算一个网络呢?

只需要估算一个V就可以,但坏处是会引入一定的随机性, 因为引入了.

先用TD或者MC去估算, 再用
去更新得到新的
, 再用新的
和环境做互动得到新的资料再去更新
。
A3C Asynchronous Advantage Actor-Critic(A3C)
目的:增加训练的速度
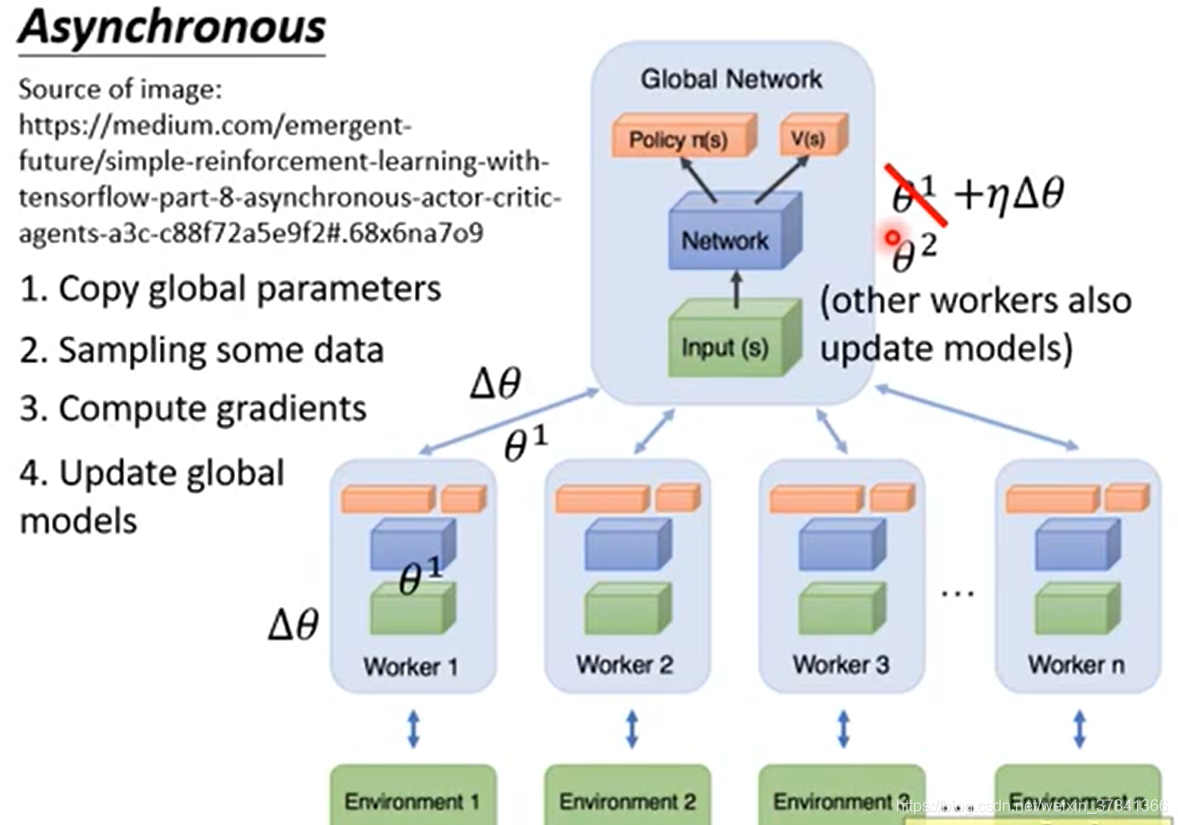
每个Worker对应一个CPU, 首先从全局网络拷贝参数至worker,然后每个worker单独采样数据,计算梯度,然后传回给中央的控制中心,中央控制中心会拿
去更新原来的参数值。每个worker在自己的环境中各自做各自的,彼此互不干扰。














 35万+
35万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









