



 RDD的分区数主要由数据源读取时决定,例如sc.textFile通过Hadoop的InputFormat进行分区。后续窄依赖RDD保持与父RDD相同的分区数,而宽依赖RDD可以通过传入参数或使用默认的spark.default.parallelism决定。分区器不是所有RDD都有的,通常在宽依赖时出现,根据默认策略或手动设置确定。
RDD的分区数主要由数据源读取时决定,例如sc.textFile通过Hadoop的InputFormat进行分区。后续窄依赖RDD保持与父RDD相同的分区数,而宽依赖RDD可以通过传入参数或使用默认的spark.default.parallelism决定。分区器不是所有RDD都有的,通常在宽依赖时出现,根据默认策略或手动设置确定。
一、分区数如何决定
1、数据源RDD
数据源RDD的分区数由数据源的读取器决定,比如sc.textFile产生的rdd,分区数由TextInputFormat.getInputSplits()方法决定,具体源码追踪及解析如下:
val rdd1 = sc.textFile("data/tbPerson.txt")
① Ctrl + B 进入textFile
textFile底层其实就是通过hadoopFile去读文件
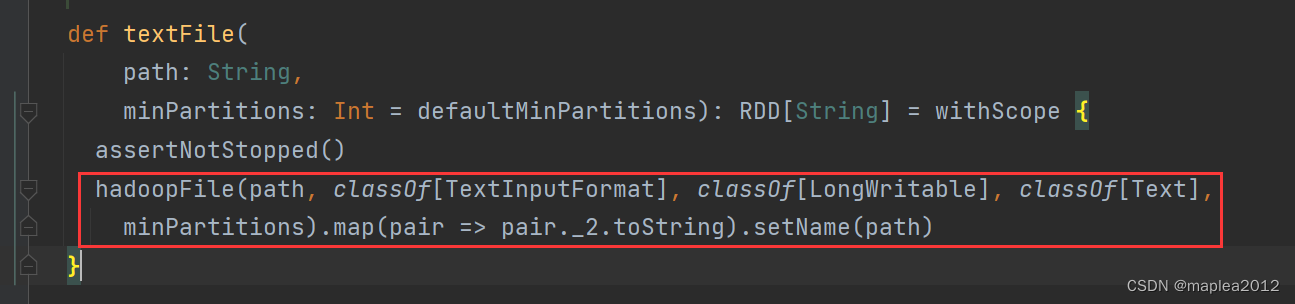
② Ctrl + B 进入hadoopFile
>>可以发现里面New了一个HadoopRDD实例
def hadoopFile[K, V](
path: String,
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int = defaultMinPartitions): RDD[(K, V)] = withScope {
assertNotStopped()
// This is a hack to enforce loading hdfs-site.xml.
// See SPARK-11227 for details.
FileSystem.getLocal(hadoopConfiguration)
// A Hadoop configuration can be about 10 KiB, which is pretty big, so broadcast it.
val confBroadcast = broadcast(new SerializableConfiguration(hadoopConfiguration))
val setInputPathsFunc = (jobConf: JobConf) => FileInputFormat.setInputPaths(jobConf, path)
new HadoopRDD(
this,
confBroadcast,
Some(setInputPathsFunc),
inputFormatClass,
keyClass,
valueClass,
minPartitions).setName(path)
}
③Ctrl + B 进入HadoopRDD类
重点关注里面的getPartitions 方法
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
// add the credentials here as this can be called before SparkContext initialized
SparkHadoopUtil.get.addCredentials(jobConf)
try {
val allInputSplits = getInputFormat(jobConf).getSplits(jobConf, minPartitions)
val inputSplits = if (ignoreEmptySplits) {
allInputSplits.filter(_.getLength > 0)
} else {
allInputSplits
}
if (inputSplits.length == 1 && inputSplits(0).isInstanceOf[FileSplit]) {
val fileSplit = inputSplits(0).asInstanceOf[FileSplit]
val path = fileSplit.getPath
if (fileSplit.getLength > conf.get(IO_WARNING_LARGEFILETHRESHOLD)) {
val codecFactory = new CompressionCodecFactory(jobConf)
if (Utils.isFileSplittable(path, codecFactory)) {
logWarning(s"Loading one large file ${path.toString} with only one partition, " +
s"we can increase partition numbers for improving performance.")
} else {
logWarning(s"Loading one large unsplittable file ${path.toString} with only one " +
s"partition, because the file is compressed by unsplittable compression codec.")
}
}
}
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) {
array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
} catch {
case e: InvalidInputException if ignoreMissingFiles =>
logWarning(s"${jobConf.get(FileInputFormat.INPUT_DIR)} doesn't exist and no" +
s" partitions returned from this path.", e)
Array.empty[Partition]
case e: IOException if e.getMessage.startsWith("Not a file:") =>
val path = e.getMessage.split(":").map(_.trim).apply(2)
throw new IOException(s"Path: ${path} is a directory, which is not supported by the " +
s"record reader when `mapreduce.input.fileinputformat.input.dir.recursive` is false.")
}
}
>> 拆解分析1:最终返回的是一个partition数组
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) {
array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
>> 拆解分析2:inputSplits是通过getInputFormat(jobConf).getSplits(jobConf, minPartitions)获取,所以需要进入getSplits方法。
大意就是遍历文件,按照一个blockSize大小(默认是128M)进行遍历,然后每一个blockSize文件都会作为一个split放到splits数组。
ps: split中存放的信息:splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));可知包括文件路径、起始偏移量、剩余文件大小、block块地址等。
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
FileSystem fs = path.getFileSystem(job);
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts[0], splitHosts[1]));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));
}
} else {
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
>> 拆解分析3:结合1和2,sc.textFile产生的rdd的分区数 就是文件按照blocksize切片后的数量。
2、后续窄依赖RDD
包括map、flatmap、mappartition 、filter、mapvalues等产生的rdd,分区数和父rdd保持一致
特例:val rdd2 = rdd1.coalesce(2,false)
rdd2中的一个分区映射了rdd1中多个固定分区。
3、后续宽依赖RDD
(1)传入了分区数参数
如果shuffle算子传入了分区数参数,则很显然由该参数决定,比如reduceBykey(f,4)、groupBykey(4)等
(2)未传入了分区数参数
如果没有传入参数,则优先根据spark.default.parallelism参数值作为默认分区数,如果参数没配,则参考运行时能用到的cpu核数:
- Local运行模式下:
scheduler.conf.getInt("spark.default.parallelism", totalCores) - 集群运行模式下:
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2)) - Sample-01
package com.wakedata.partitionNums
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object TextFile {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local[*]")
conf.setAppName("textFile");
val sc = new SparkContext(conf);
val rdd2: RDD[(Char, Int)] = sc.parallelize(Seq(
('a', 1),
('b', 4),
('d', 3),
('c', 2),
('e', 2),
));
println("rdd2的分区器", rdd2.partitioner);
println("rdd2的分区数", rdd2.getNumPartitions);
rdd2.collect();
val rdd3 = rdd2.groupBy(s => s._1);
println("rdd3的分区器", rdd3.partitioner);
println("rdd3的分区数", rdd3.getNumPartitions);
rdd3.collect();
}
}
>>分区数为8,因为Local运行模式下,且未设置spark.default.parallelism参数,最终会取主机的cores数量作为分区数。

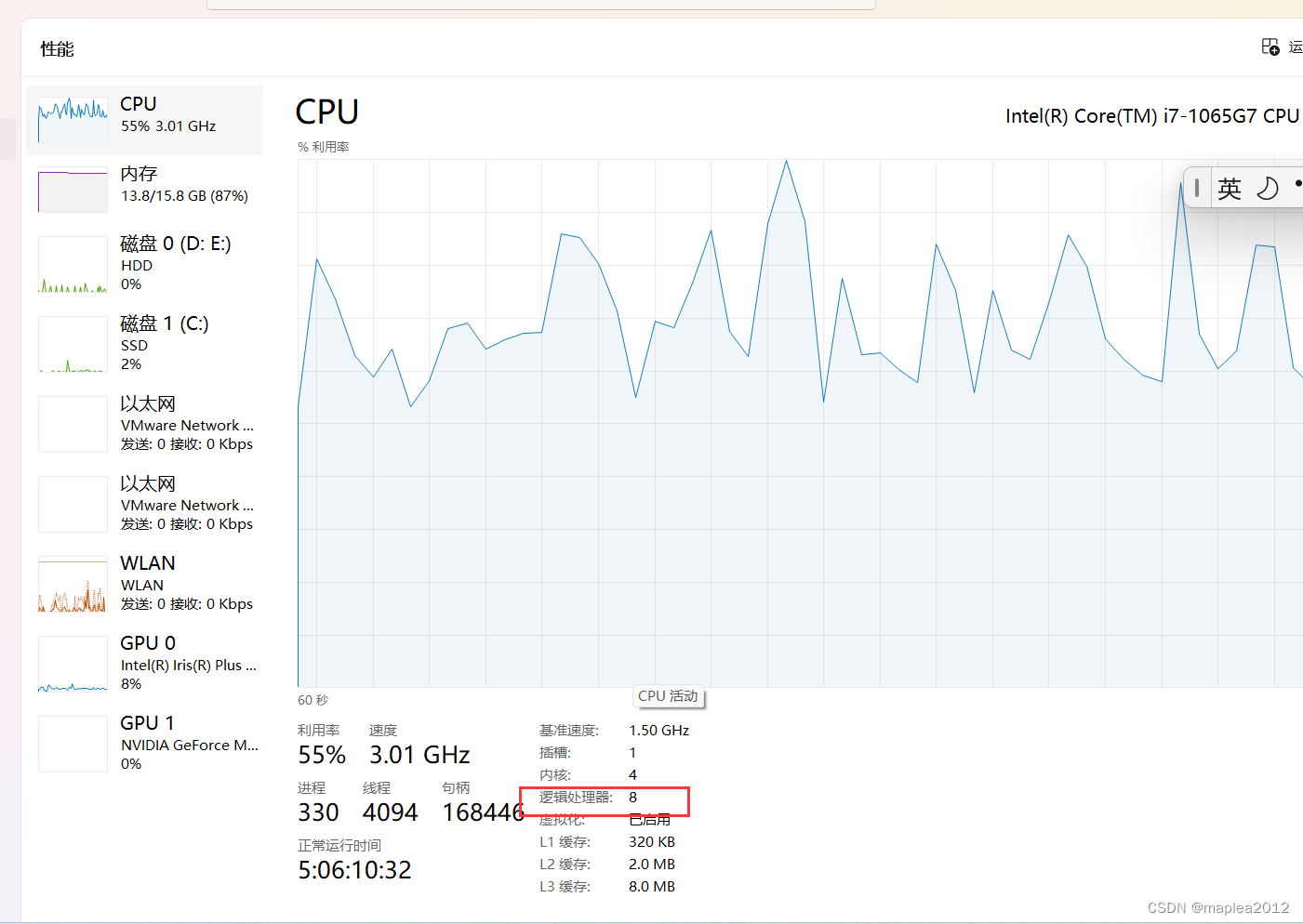
- Sample-02,如果设置spark.default.parallelism的值
package com.wakedata.partitionNums
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object TextFile2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local[*]")
conf.setAppName("textFile");
conf.set("spark.default.parallelism","4");
val sc = new SparkContext(conf);
val rdd2: RDD[(Char, Int)] = sc.parallelize(Seq(
('a', 1),
('b', 4),
('d', 3),
('c', 2),
('e', 2),
));
println("rdd2的分区器", rdd2.partitioner);
println("rdd2的分区数", rdd2.getNumPartitions);
rdd2.collect();
val rdd3 = rdd2.groupBy(s => s._1);
println("rdd3的分区器", rdd3.partitioner);
println("rdd3的分区数", rdd3.getNumPartitions);
rdd3.collect();
}
}

如上所示,分区数量会变成4
二、分区器如何决定
1、并非所有RDD都有分区器
- 数据源RDD通过数据源读取器的内在机制进行分区,不需要Partitioner;
- 窄依赖rdd,直接一对一依赖于前面rdd的分区,没有发生任何数据分布的变化,因此也不需要Partitioner;
- 宽依赖才会需要Partitioner(但并非一定有Partitioner),可以手动传入,也可以取默认值,具体逻辑如下:
//求默认分区器的策略和方法
def defaultPartitioner(rdd: RDD[_], others: RDD[_]*): Partitioner = {
//合并所有父rdd(多个rdd Join场景)成为一个序列
val rdds = (Seq(rdd) ++ others)
//筛选出拥有分区器的父rdd
val hasPartitioner = rdds.filter(_.partitioner.exists(_.numPartitions > 0))
//拥有分区器的父rdd中,分区数最大的rdd
val hasMaxPartitioner: Option[RDD[_]] = if (hasPartitioner.nonEmpty) {
Some(hasPartitioner.maxBy(_.partitions.length))
} else {
None
}
// 默认分区数:如果有设置参数,则取其值,如果没有则取父rdd中(包括不含分区器的父rdd)最大的分区数
val defaultNumPartitions = if (rdd.context.conf.contains("spark.default.parallelism")) {
rdd.context.defaultParallelism
} else {
rdds.map(_.partitions.length).max
}
// If the existing max partitioner is an eligible one, or its partitions number is larger
// than or equal to the default number of partitions, use the existing partitioner.
//如果父rdd中至少一个拥有分区器,同时[所有父rdd最大分区数]/ [拥有分区器的父rdd中最大的分区数] < 10 | 默认分区数 小于等于 拥有分区器的父rdd的最大的分区数],则取拥有分区器的父rdd中最大的分区数 作为最后的分区数
if (hasMaxPartitioner.nonEmpty && (isEligiblePartitioner(hasMaxPartitioner.get, rdds) ||
defaultNumPartitions <= hasMaxPartitioner.get.getNumPartitions)) {
hasMaxPartitioner.get.partitioner.get
} else {
//否则就取 默认分区数作为最后的分区数
new HashPartitioner(defaultNumPartitions)
}
}
private def isEligiblePartitioner(
hasMaxPartitioner: RDD[_],
rdds: Seq[RDD[_]]): Boolean = {
val maxPartitions = rdds.map(_.partitions.length).max
log10(maxPartitions) - log10(hasMaxPartitioner.getNumPartitions) < 1
}
2、场景举例
(1)父rdd至少一个存在分区器,但是所有父rdd最大分区数 / 拥有分区器的父rdd中最大的分区数 > 10 且 默认分区数(只有一种场景,即设置了参数)大于拥有分区器的父rdd中最大的分区数。此时子rdd的分区器是hasMaxPartitioner,并且分区数是默认分区数。【本地主机只有8核,无法模拟所有父rdd最大分区数 / 拥有分区器的父rdd中最大的分区数 > 10 】
(2)父RDD1 有分区器且分区数为2,父RDD2没有分区器且分区数为8,不设置spark.default.parallelism参数,则defaultNumPartitions为8,然后父RDD中有一个存在分区器,并且isEligiblePartitioner满足条件,因此子RDD的是 hasMaxPartitioner.get.partitioner.get,即分区器为:父RDD的分区器 & 分区数为2
package com.wakedata.partitionNums
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DependencyPartitioner {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local[*]")
conf.setAppName("textFile");
// conf.set("spark.default.parallelism","4");
val sc = new SparkContext(conf);
val rdd1: RDD[(Char, Int)] = sc.parallelize(Seq(
('a', 1),
('b', 4),
('d', 3),
('c', 2),
('e', 2),
));
//第一个父rdd,分区数为2
val rdd2: RDD[(Char, Iterable[Int])] = rdd1.groupByKey(
numPartitions = 2
);
//第二个父rdd,没有分区器且分区数是 8(CPU逻辑为8,最大也只能分8个区)
// val rdd3: RDD[(Char, Int)] = rdd1.coalesce(100)
val rdd3: RDD[(Char, Int)] = rdd1.coalesce(8)
println("rdd3分区数",rdd3.getNumPartitions);
val rdd2_3_join = rdd2.join(rdd3)
//rdd2_3_join的分区数应该是 2
println(rdd2_3_join.getNumPartitions)
//rdd2_3_join的分区器是Hashpartioner
println(rdd2_3_join.partitioner)
}
}
(3)父RDD1 有分区器且分区数为2,父RDD2没有分区器且分区数为8,设置spark.default.parallelism参数为4,则defaultNumPartitions为4, 然后父RDD中有一个存在分区器,并且isEligiblePartitioner满足条件,因此子RDD的是 hasMaxPartitioner.get.partitioner.get,即分区器为:父RDD的分区器 & 分区数为2
package com.wakedata.partitionNums
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DependencyPartitioner02 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local[*]")
conf.setAppName("textFile");
conf.set("spark.default.parallelism","4");
val sc = new SparkContext(conf);
val rdd1: RDD[(Char, Int)] = sc.parallelize(Seq(
('a', 1),
('b', 4),
('d', 3),
('c', 2),
('e', 2),
));
//第一个父rdd,分区数为2
val rdd2: RDD[(Char, Iterable[Int])] = rdd1.groupByKey(
numPartitions = 2
);
//第二个父rdd,没有分区器且分区数是 8(CPU逻辑为8,最大也只能分8个区)
// val rdd3: RDD[(Char, Int)] = rdd1.coalesce(100)
val rdd3: RDD[(Char, Int)] = rdd1.coalesce(8)
println("rdd3分区数",rdd3.getNumPartitions);
val rdd2_3_join = rdd2.join(rdd3)
//rdd2_3_join的分区数应该是 2
println(rdd2_3_join.getNumPartitions)
//rdd2_3_join的分区器是Hashpartioner
println(rdd2_3_join.partitioner)
}
}

(4)父RDD1 没有分区器且分区数为2,父RDD2没有分区器且分区数为3,没有设置 spark.default.parallelism参数,则defaultNumPartitions为3, 子RDD是new hasMaxPartitioner,分区数是3.
package com.wakedata.partitionNums
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DependencyPartitioner03 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local[*]")
conf.setAppName("textFile");
// conf.set("spark.default.parallelism","4");
val sc = new SparkContext(conf);
// 第一个父rdd,没有分区器
val rdd1: RDD[(Char, Int)] = sc.parallelize(Seq(
('a', 1),
('b', 4),
('d', 3),
('c', 2),
('e', 2),
),2);
// 第二个父rdd,没有分区器
val rdd2: RDD[(Char, Int)] = sc.parallelize(Seq(
('f', 1),
('g', 4),
('h', 3),
('i', 2),
('j', 2),
),3);
val rdd_join = rdd1.join(rdd2);
//join的分区器应该是HashPartitioner
println(rdd_join.partitioner)
//join的分区数量应该是3
println(rdd_join.getNumPartitions)
}
}

(5)父RDD1 没有分区器且分区数为2,父RDD2没有分区器且分区数为3,且设置 spark.default.parallelism = 4,则defaultNumPartitions为4, 子RDD是new hasMaxPartitioner,分区数是4.
package com.wakedata.partitionNums
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DependencyPartitioner04 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local[*]")
conf.setAppName("textFile");
conf.set("spark.default.parallelism","4");
val sc = new SparkContext(conf);
// 第一个父rdd,没有分区器
val rdd1: RDD[(Char, Int)] = sc.parallelize(Seq(
('a', 1),
('b', 4),
('d', 3),
('c', 2),
('e', 2),
),2);
// 第二个父rdd,没有分区器
val rdd2: RDD[(Char, Int)] = sc.parallelize(Seq(
('f', 1),
('g', 4),
('h', 3),
('i', 2),
('j', 2),
),3);
val rdd_join = rdd1.join(rdd2);
//join的分区器应该是HashPartitioner
println(rdd_join.partitioner)
//join的分区数量应该是4
println(rdd_join.getNumPartitions)
}
}


















 802
802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









