







文件系统特性
1.概述
windows98以前的微软操作系统的文件系统是FAT32
windows2000以后的微软操作系统的文件系统是NTFS
Linux的正统文件系统是Ext2(Linux second extended file system,ext2fs)
默认情况下,windows操心系统是不会认识Linux的Ext2的。
由于新技术的普及,一个分区槽可以格式化为多个文件系统(例如LVM),也能够将多个分区槽合成一个文件系统(LVM,RAID),所以,目前我们可以称呼一个可被挂载的数据为一个文件系统,而不是一个分区槽。
2.文件系统是如何运作的?
Linux操作系统的文件权限(rwx)与文件属性(拥有者、群组、时间参数等)通常会被存放在不同的区块,
-
- 权限与属性放置到inode中,
- 实际数据则放置到data block区块中。
- 超级区块(superblock)会记录整个文件系统的整体信息,包括inode与block的总量,使用量,剩余量等。
每个inode与block都有编号,至于这三个数据的意义可以简略的说明如下:
- superblock:记录此filesystem的整体信息,包括inode/block的总量,使用量,剩余量,以及文件系统的格式与相关信息等。
- inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的block号码。
- block:实际记录文件的内容,若文件太大时,会占用多个block。
因为每个inode和block都有编号,而每个文件都会占用一个inode,因此,找文件可以通过找到inode然后再读取实际数据,这是一个比较有效率的做法。---这种数据存取的方法,称为 索引式文件系统(indexed allocation)。

其他的文件系统,如FAT格式。这种文件系统没有inode存在,所以没有办法将这个文件的所有block在一开始就读取出来,每个block号码都记录在前一个block中,它的读取方式如下图:
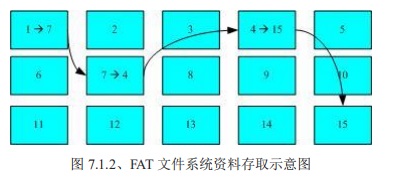
假设文件的数据依序写入1->7->4->15号的这四个block号码中,但是文件系统没有办法一口气就知道四个block号码,它需要一个个将block读出后,才知道下一个block在哪里。如果一个文件的数据写入的block过于分散,则磁盘读取头会多转好几个圈才能读取到这个文件的内容,这就有了所谓的【碎片整理】。
碎片整理的原因是文件写入的block太过于离散了,导致读取文件的效率很差。通过碎片整理可以把一个文件的block汇整在一起。
因此FAT的文件系统需要经常碎片整理一下。
Ext2是索引式文件系统,基本上不太需要常常进行碎片整理。
3.Linux的EXT2文件系统(inode)
Linux的filesystem里包含有inode/block/superblock等。
inode:记录文件的权限与相关属性;
block:记录文件的实际内容;
superblock:记录整个filesystem相关信息的地方,没有superblcok就没有filesystem;
文件系统一开始就将inode和block规划好了,除非重新格式化(或者利用resize2fs等指令变更文件系统大小),否则inode和block固定后就不再变动。
但是如果文件系统高达数百GB时,那么将所有的inode和block放一起是很不明智的,因为数量太庞大,不容易管理。
为此,EXT2文件系统在格式化的时候基本上是区分为多个区块群组(block group)的,每个区块群组都有独立的inode/block/superblock系统。
在整体规划中,文件系统最前面有一个启动扇区(boot sector),这个启动扇区内可以安装开机管理程序。

data block(资料区块)
用于放置文件内容数据的地方。在EXT2文件系统中支持的block大小有1K,2K,及4K三种。格式化的时候block的大小就已经固定了,且每个block都有编号,以方便inode的记录。block大小决定该文件系统能够支持的最大磁盘容量与最大单一文件容量。

Ext2文件系统的block有其他什么限制?如下:
- 原则上,block的大小和数量在格式化之后就不能再改变了;
- 每个block内最多只能够放置一个文件的数据;
- 如果文件大小大于block的大小,则一个文件会占用多个block数量;
- 若文件小于block大小,则该block的剩余空间将不能被其他文件使用;
inode table(inode 表格)
inode记录的文件数据包含以下:
- 该文件的存取模式(read/write/excute);
- 该文件的拥有者与群组(owner/group);
- 该文件的容量;
- 该文件建立或状态改变的时间(ctime);
- 最近一次读取时间(atime);
- 最近修改的时间(mtime);
- 定义文件特性的旗标(flag),比如:SetUID。。。;
- 该文件的真正内容的指向(pointer);
除此之外,inode还有其他的特色:
- 每个inode的大小均固定为128bytes(新的ext4与xfs可设定到256bytes);
- 每个文件都仅会占用一个inode;
- 文件系统能够建立的文件数量与inode的数量有关;
- 系统读取文件时需要先找到inode,分析inode所记录的权限与用户是否符合,若符合才能够开始实际读取block的内容。

12个直接指向:12 *1K =12K
间接:256*1K=256K
双间接:256*256*1K = 256^2K
三间接:256*256*256*1K = 256^3K
总额等于:16GB
所谓间接,就是再拿一个block来当作记录block号码的记录区,如果文件太大时,就会使用间接的block来记录编号。
为什么是256?
因为每笔block号码的记录会花去4bytes(1byte=8bit=8*1bit),因此1K的大小能记录256笔记录,因此一个间接(block)可以记录的文件大小=256*1K=256K。
间接:拿出一个block来记录;
双间接:第一层block指定256个第二层;每个第二层可以指定256个号码,因此总额是256*256*1K;
三间接:第一层block指定256个第二层;每个第二层指定256个第三层;每个第三层指定256个号码,因此总额是256*256*256*1K;
总额:将直接+间接+双间接+三间接 =12+256+256*256+256*256*256(k)=16GB
即:文件系统将block格式化为1k大小时,能够容纳的最大文件为16GB。
Superblock(超级区块)
记录整个filesystem相关信息的地方,没有superblcok就没有filesystem,记录的信息有:
- block与inode的总量;
- 未使用与已使用的inode/block数量;
- block与inode的大小(block为1,2,4K,inode为128bytes或256bytes);
- filesystem的挂载时间,最近一次写入数据的时间,最近一次检验磁盘(fsck)的时间等文件系统相关信息;
- 一个valid bit数值,若此文件系统已被挂载,则valid bit为0,若未被挂载,则valid bit为1.
一般来说,superblock的大小为1024bytes
Filesystem Description(文件系统描述说明)
这个区段可以描述每个block group的开始于结束的block号码,以及说明每个区段(superblock,bitmap,inodemap,datablock)分别介于哪一个block号码之间。
block bitmap(区块对照表)
block bitmap记录哪些block是空的,哪些是满的。
inode bitmap(inode 对照表)
inode bitmap记录已使用与未使用的block号码。
在文件系统中,目录与文件是如何记录数据的?
在linux下的文件系统建立一个目录时,文件系统会分配一个inode与至少一块block给该目录。其中,inode记录该目录的相关权限与属性,并可记录分配到的那块block号码;而block则是记录在这个目录下的文件名与该文件名占用的inode号码数据。
举例1:linux文件系统读取/etc/passwd的流程
1.读取根目录/的inode,检查inode规范的权限,确认有读取该block的权限rx;
2.从/的inode里读取 / 的block号码,找到该内容有etc/目录的inode号码;
3.读取etc/的inode号码,确认是否有etc/的读取权限r x;
4.读取etc/的block号码,再读取passwd文件的inode号码;
5.检查是否有passwd的读取权限r,再读取passwd的block号码;
6.从passwd的block号码块中把block内容的数据读出来。
举例2:新建一个文件或目录时,文件系统是如何处理的?
1.新增一个文件,首先确认新增文件的目录是否有w和x的权限;
2.根据inode bitmap找到没有使用的inode号码,并将新文件的权限/属性写入;
3.根据block bitmap找到没有使用中的block号码,并将实际的数据写入block中,且更新inode中的block指向数据;
4.将刚刚写入的inode与block数据同步更新inode bitmap与block bitmap,并更新superblock的内容。
上述例子牵扯出一个数据的不一致状态问题,例如:
在系统执行完第三步的时候,由于不知名的原因,导致系统中断,直接导致最后一个同步动作没有做完,这时候,就会发生metadata的内容与实际数据存放区产生不一致的情况了。
解决数据不一致状态的方法:
日志式文件系统
具体方法:
1.预备:当系统要写入一个文件时,会先在日志记录区块中记录某个文件准备要写入的信息;
2.实际写入:开始写入文件的权限与数据,开始更新metadata的数据;
3.结束:完成数据域metadata的更新后,在日志记录区块中完成该文件的记录;
这样的程序中,万一数据的记录过程中发生了问题,系统只需检查日志记录区块,就可以知道哪个文件发生了问题,针对该问题进行一致性检查即可,而不必针对整个filesystem去检查。
Linux文件系统的运作
所有的数据都要加载到内存之后,CPU才能对数据进行处理。在编辑的过程中,频繁的让系统写入磁盘会导致效率极低。因此,linux采用的是一个异步处理的方式,步骤如下:
当系统加载一个文件到内存之后,如果该文件没有被改动过,则在内存区段的文件数据被设定为干净的(clean)。
如果内存中的数据被改动过了,则标记为脏(Dirty)。此时所有动作还在内存中执行,并没有写入到磁盘中。
系统会不定时的将内存中设定为Dirty的数据写回磁盘,以保持磁盘与内存的一致性。
挂载点的意义
每个filesystem都有独立的inode/block/superblock等信息,这个文件系统需要链接到目录树,才能被用户使用。将文件系统和目录树结合的动作,称为【挂载】。
重点:挂载点一定是目录,该目录为进入该文件系统的入口。
命令: ls -lid / /boot
查看系统支持的文件系统:
cat /proc/filesystems
Linux核心是如何管理系统支持的这些文件系统的?
Linux系统通过一个名为Virtual Filesystem Switch的核心功能去读取filesystem的。即,整个Linux认识的filesystem都是VFS在进行管理。
假如 / 使用的是/dev/hda1,用的是ext3文件系统;
/home使用的是/dev/hda2,用的是reiserfs文件系统;
当用户读取数据的时候不需要指定用什么文件系统来读取,而是系统根据VFS的功能自行读取文件系统内的数据。

XFS文件系统简介
从CentOS7 开始,预设的文件系统从EXT4转为XFS文件系统了。原因如下:
EXT家族支持度最广,但是格式化超慢!遇到超大容量或者虚拟化技术,EXT4没有xfs来的合适。
xfs是被开发出来用于高容量磁盘以及高性能文件系统之用,相当适合现在的系统环境。几乎所有EXT4文件系统有的功能,xfs都具备。
xfs文件系统在资料的分布上主要划分为三个部分,数据区(data section),文件系统活动登录区(log section)以及一个实时运作区(realtime section)。
数据区(data section)
相当于Ext家族的block group,包含了整个文件系统的superblock,剩余空间管理机制,inode的分配与追踪等。另外由于inode与block是系统用到时才动态配置的,所以格式化动作超级快。
此外,与ext家族不同的是,xfs的block与inode有多种不同的容量可供设定,block容量范围512bytes~64K,inode容量范围256bytes~2M。
文件系统活动登录区(log section)
用于记录文件系统的变化,有点像日志区。文件的变化在这里记录下来,直到变化完整地写入数据区,该笔记录才会被终结。如果因为意外情况中断,则系统会检查登录区,借以快速修复文件系统。
因为系统所有动作都会在这个区块做记录,因此这个区块的磁盘活动非常频繁。而xfs可以指定外部的磁盘来作为xfs系统的日志区块,例如SSD磁盘作为xfs的登录区。
实时运作区(realtime section)
当有文件需要被新建的时候,xfs会在这个区段找到一个到数个extent区块,将文件放置在这个区块内,等分配完成,再写入到data section的inode与block中去。这个extent区块的大小在格式化的时候就先指定,最小值是4K,最大可以到1G。
文件系统的简单操作
1.磁盘与目录的容量
df:列出文件系统的整体磁盘使用量;
du:苹果文件系统的磁盘使用量(常用在推估目录所占容量);
















 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









