







背景
因公司业务架构变更,需要对原有账户累计收益进行备份,削弱老业务对新业务的影响。而原有用户累计收益数据约为7000w,因为处于业务过渡阶段,所以希望以一种临时的手段去存储数据,最终讨论得出,在用户表新增一个字段old_balance来存储这个数据。
大表加字段

从图中看到,member表数据空间占用11.12G。另外也发现索引占用的空间比数据还大,可见索引的创建需要慎重。
一开始以为加字段会锁表,使得线上服务不可用。但后来发现是不需要的。
Mysql支持在增加列的过程中并发DML。
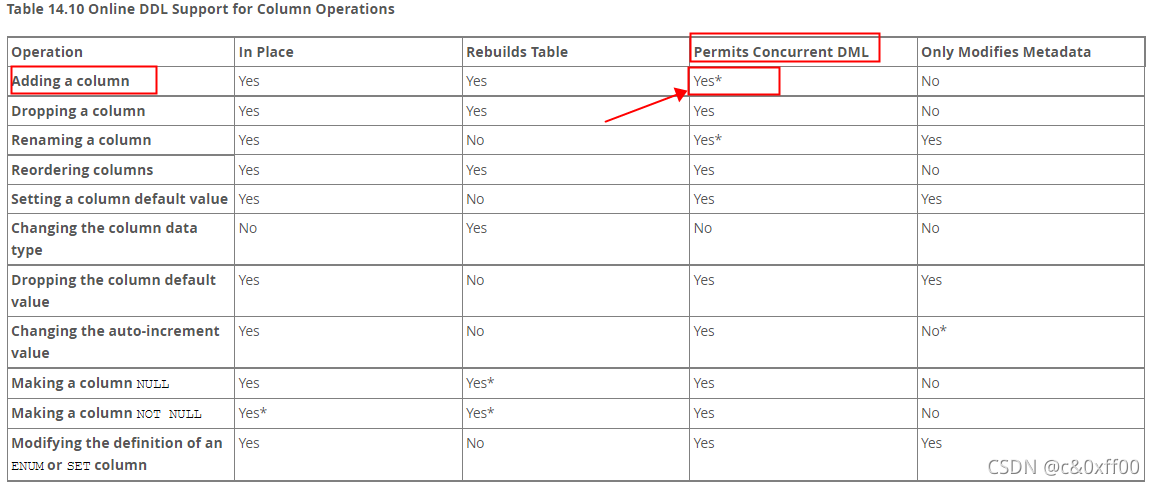
Mysql5.6官方文档 https://dev.mysql.com/doc/refman/5.6/en/innodb-online-ddl-operations.html#online-ddl-column-operations
大致流程是:重建临时表,数据拷贝到临时表中,然后删除原表,将临时表的表名更改为原表。
可惜,十几个G的member大表增加bigInt字段,花了两个多小时,最终算是成功了,有惊无险。
批量数据更新
需要更新的数据是通过原有接口获取的,然后再更新到member表中,虽然一条数据花费时间不会很久,但当数据量到千万级,累计起来还是很可观的。
相信很多同学都想到了,并行执行。
如果单线程执行,更新一条数据大于20ms,则7000w * 20ms / 1000 * 86400 约等于16天,为了尽快完成任务,推动账户迁移项目的进度,
我就加大线程数,将数据加到线程池中处理,一开始单机起了40个线程,处理速度还是太慢。
然后线程数40 -> 逐步改成了400,批量处理速度的确比较快,1分钟能处理10w数据。
但一看数据库:
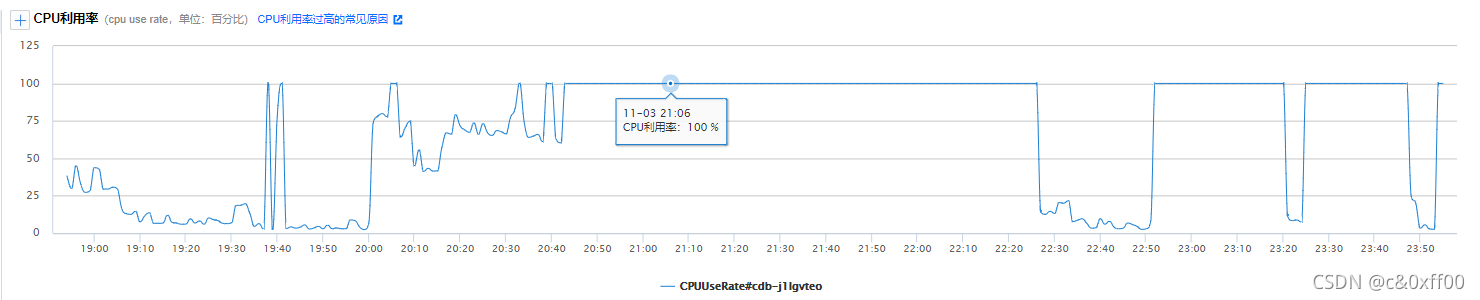
cpu已经飙到了100%,线上系统也出现了告警
后来发现,这除了和并行执行有关,还和分页查询的性能有关。
类似于对全量数据的分页扫描,可以采用主键Id进行分页,如:
select * from tableName where id between (pageNo-1)*pageSize and pageNo*pageSize;
不要使用
// 随着数据量的增多,limit后面会越来越大,性能急剧降低,损耗性能
select * from tableName order by id limit (pageNo-1)*pageSize ,pageSize;
这种方法,随着数据量的增多,limit后面会越来越大,扫描的数据越来越大,性能急剧降低,损耗性能
小贴士
select * from tableName order by id limit pageSize offset (pageNo-1)*pageSize;
等价于
select * from tableName order by id limit (pageNo-1)*pageSize ,pageSize;
都表示从(pageNo-1)*pageSize开始往后查找pageSize个
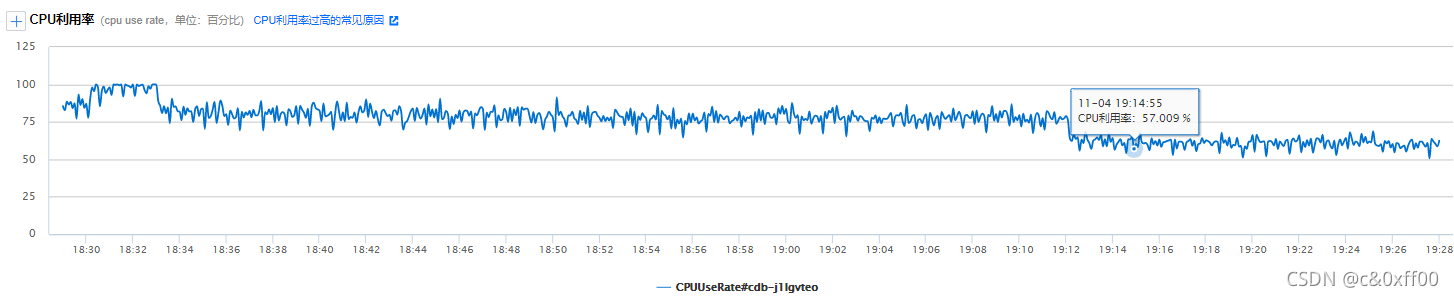
所以后来修改了查询sql,同时根据Mysql压力情况调整并发线程数。
使得CPU控制在安全范围内。
小结
批量处理超大数量的数据,我们会考虑使用多线程。同时需要考虑系统的性能状况合理控制并发度。














 2473
2473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









