






 本文深入解析SNPE框架,涵盖模型加载、验证、运行模式选择、模型处理、量化算法及自定义操作等内容,介绍如何在不同运行后端部署深度学习模型。
本文深入解析SNPE框架,涵盖模型加载、验证、运行模式选择、模型处理、量化算法及自定义操作等内容,介绍如何在不同运行后端部署深度学习模型。
SNPE提供以下高级API:
DL Container Loader: SNPE使用后缀为dlc的模型文件,提供了模型load函数;
Molde Vallidation: 检查输入模型与所选择的运行后端是否合法;
Runtime Engine: 选择运行模式的API, 包括CPU, GPU, DSP和AIP四种运行模式;
Partitioning Logic: 模型处理API, 包括检查网络layer的合法性, 调度网络的Runtime(例如让网络的一部分执行在特定的后端上: UDLs--用户自定义的layer,它只能运行在CPU runtime上, 在 CPU fallback 开启时, 可以让非UDLs部分运行在你选择的除CPU以外的后端上,而UDLs运行于CPU上,这种后端的切换会里带来一定开销);
CPU Runtime : CPU运行模型, 支持32-bit和 8-bit量化模型;
GPU Runtime: GPU运行模型, 支持混合或完整16位浮点模式;
DSP Runtime: Hexagon DSP运行模型, 使用Q6 和 hexagon NN, 在HVX上运行, 只支持8-bit量化模型;
AIP Runtime: Hexagon DSP运行模型, 使用Q6, Hexagon NN 和HTA, 只支持8-bit量化模型;
AIP Runtime
AIP模式是Q6,HVX和HTA的软件混合模式的整体抽象,当选择AIP模式运行时,该模型的一部分将在HTA上运行,而一部分在HVX上(由Q6协调),SNPE在DSP上加载一个库,该库与AIP运行时进行通信, 该DSP库包含一个执行器(用于管理HTA和HVX中的模型的执行, HTA上运行子网基于HTA驱动程序,HVX运行子网基于Hexagon NN)。执行器executor使用模型描述(model description)描述模型的哪些部分将在HTA上运行以及在HVX上运行, 这些划分的子部分称作子网络;DSP执行器在相应的内核上执行子网,并根据需要协调缓冲区交换和格式转换, 随时准备跟CPU上运行的子网络通讯。
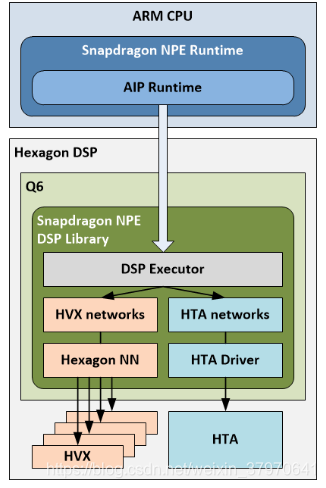
SNPE的Runtime可以是CPU模式+其他模式的混合组合,或者单独使用一种Runtime; 在模型的转化(Conversion)时可以设定具体Runtime模式,对于AIP模式,可以选择完全运行在HTA上,或者一部分运行在HTA一部分运行在HNN, 这取决于网络的op是否都被HTA支持,如果部分支持,则只能选择后者; 两种方案的选择在模型转化时由SNPE自动完成;也可以手动分解网络,但太多的子网络会影响运行速度。
SNPE Setup
英文Setup教程地址:https://developer.qualcomm.com/docs/snpe/setup.html
本机环境:Ubuntu16.04, 64位;
Caffe: 按照教程指示的分支下载安装caffe,并配置pycaffe;
Tensorflow: 我这里没有使用照教程指定的版本(版本太旧报错),使用的tf-1.14,跟我模型训练TF版本一致;
ONNX: 使用的最新版本,使用pip下载即可;
Python3.5: 我使用的是3.5版本,并更改系统Python默认版本到Python-3.5;
Android NDK: 下载对应版本NDK, libc++_shared.so没有按照教程操作,因为指定文件目录下已经存在(这块不太理解);
Android SDK: 没下载;
SNPE SDK下载:https://developer.qualcomm.com/software/qualcomm-neural-processing-sdk
下载好后解压并按照指示检查环境,并设置环境变量,此外为了能够顺利的使用SNPE SDK的相关工具,需要添加环境变量:
export PYTHONPATH=$SNPE_ROOT/lib/python
Network Models
英文文档地址:https://developer.qualcomm.com/docs/snpe/usergroup1.html
1、支持的网络Layers;
2、支持的ONNX Ops;
3、量化 vs 不量化:
CPU、GPU模式下:可以直接处理非量化模型,对于量化模型输入,需要反量化处理,增加了初始化时间,且影响精度;
DSP模式 :可直接处理量化模型,对于非量化模型输入,初始化时会进行量化处理,精度跟前者会不一样;
AIP模式 :只支持量化模型输入;
量化算法:
a、量化后区间要涵盖所有输入数据;
b、输入数据的值域大于0.01;
c、输入数据0 需要精确的表示(要与量化区间中具体的数值对应);
获取输入数据的最大最小值i_max, i_min,如果两者的差小于0.01,则更新最大值i_max为max(i_max, i_min + 0.01), 以8-bit量化为例,此时求得区间刻度step = (i_max - i_min) / 255, 此时计算(0 - i_min) / (i_max - i_min) * 255 是否为整数,若不是,将i_max, i_min同时移动n * step刻度;
算法优化:一种方案是忽略异常的极端值,特别大或者特别小的值;另一种方案也是优化最大最小值的选择,具体怎么做的不知道,由于量化容易损失精度,所以量化的同时还引进了CLE(跨层均衡)和BC(偏置校正);CLE和BC通常同时使用,CLE 对网络结构有要求,一个输出不能被多个Op操作,也就是不能有分支结构,这几乎等于没啥用了就,同时不支持Relu6, 会自动将其转化为Relu,精度下降;CLE要求在转换为DLC之前,原始模型中必须存在BatchNorm(特指可检测到批量标准中beta / gamma数据)才能运行完整算法并重新获得最大的准确性。CLE速度很快,BC很慢,几分钟到几小时都有可能;
User-defined Operations(自定义OP)
英文教程链接:https://developer.qualcomm.com/docs/snpe/udo_overview.html
比较麻烦,需要配置UDO Package Description文件,指定输入输出的数据格式,运行后端等描述性信息;然后通过generator工具生成源文件,但是对于每个运行后端的具体执行函数需要自己编写(函数声明已经写好,只需把定义添上就行),然后编译生成对应与各种Runtime的.so库文件,在模型转换时候,可以添加UDO参数(--udo_config_paths),指定要使用的so文件;运行时也需要指定库文件,详细见教程;
Model Conversion(模型转换)
英文教程链接:https://developer.qualcomm.com/docs/snpe/usergroup3.html
根据教程使用命令行,运行/$SNPE_ROOT/bin/x86_64-linux-clang文件夹下的工具完成转化即可,详情见教程;
注意:对于Tensorflow,需要重新训练去掉网络中的关于is_training 状态的placeholder,并使用False替代,且最好将batch_size同时设置为1,方便后续的量化操作;
Quantizing a Model
英文教程链接:https://developer.qualcomm.com/docs/snpe/model_conversion.html
按照教程命令行运行即可,注意--enable_hta参数,大概率添加此参数后转换会失败(SUB, MUL, Reducation, Stride_Slice都不支持),但仍会生成dlc文件,但是不会包含运行在HTA上的子网络,因为--enable_hta参数默认会最大化HTA子网络,让网络的更多部分运行在HTA,这种情况下HTA与HVX同时工作,如果开启CPU Fallback,则AIP任何未处理的部分都可以回退到CPU处理;当然,你还可以手动选取HTA分区,详见教程;
参数--input_list image_file_list.txt中存储着与训练输入数据相同格式的二进制图像数据的地址,一行存储一张图;
图片转二进制:
from PIL import Image
import numpy as np
img = Image.open("path of image")
img = np.array(img)
img = img.astype(np.float32)
##也许需要一些处理,例如channel调整顺序、减去均值、除以方差等##
img.tofile("path/{}.raw".format("name of binary file"))Input Image Formatting
SNPE对输入图像格式的要求是NHWC; 但是,推理过程中使用的通道顺序必须与训练过程中使用的通道顺序相同。例如,在Caffe中训练的Imagenet模型需要BGR的频道顺序。
Running Nets
英文教程链接:https://developer.qualcomm.com/docs/snpe/tutorial_inceptionv3.html (Tensorflow Inception V3)
按教程命令行运行即可,生成结果会保存到output文件夹下的.raw文件中,使用np.fromfile("file‘s path", dtype=np.float32)即可提取输出,根据网络输出格式进行解读即可;
注意:snpe-net-run时可能会显示无法连接到libSNPE.so, 添加环境变量即可:
export LD_LIBRARY_PATH =$SNPE_ROOT/lib/x86_64-linux-clang/libSNPE.so
Build the Sample with C++
英文教材链接:https://developer.qualcomm.com/docs/snpe/cplus_plus_tutorial.html
简单的C++ 调用demo,如果涉及UDL, UDO则详见教程。
// 获取Runtime后端
zdl::DlSystem::Runtime_t checkRuntime()
{
static zdl::DlSystem::Version_t Version = zdl::SNPE::SNPEFactory::getLibraryVersion();
static zdl::DlSystem::Runtime_t Runtime;
std::cout << "SNPE Version: " << Version.asString().c_str() << std::endl;
if (zdl::SNPE::SNPEFactory::isRuntimeAvailable(zdl::DlSystem::Runtime_t::GPU)) {
Runtime = zdl::DlSystem::Runtime_t::GPU;
} else {
Runtime = zdl::DlSystem::Runtime_t::CPU;
}
return Runtime;
}
// 基于Runtime初始化SNPE
void initializeSNPE(zdl::DlSystem::Runtime_t runtime) {
// 声明container指向导入的dlc模型
std::unique_ptr<zdl::DlContainer::IDlContainer> container;
// load
container = zdl::DlContainer::IDlContainer::open("/path/to/model.dlc");
// 实例化一个SNPE Builder
zdl::SNPE::SNPEBuilder snpeBuilder(container.get());
// 使用了ITensors模式
snpe = snpeBuilder.setOutputLayers({})
.setRuntimeProcessor(runtime)
.setUseUserSuppliedBuffers(false)
.setPerformanceProfile(zdl::DlSystem::PerformanceProfile_t::HIGH_PERFORMANCE)
.build();
}
// 加载输入数据
std::unique_ptr<zdl::DlSystem::ITensor> loadInputTensor(std::unique_ptr<zdl::SNPE::SNPE> &snpe, std::vector<float> inputVec) {
// 定义ITensors格式的input作为网络输入的容器
std::unique_ptr<zdl::DlSystem::ITensor> input;
// 获取网络输入name
const auto &strList_opt = snpe->getInputTensorNames();
if (!strList_opt) throw std::runtime_error("Error obtaining Input tensor names");
const auto &strList = *strList_opt;
const auto &inputDims_opt = snpe->getInputDimensions(strList.at(0));
const auto &inputShape = *inputDims_opt;
input = zdl::SNPE::SNPEFactory::getTensorFactory().createTensor(inputShape);
std::copy(inputVec.begin(), inputVec.end(), input->begin());
return input;
}
// 执行并返回输出ITensors
zdl::DlSystem::ITensor* executeNetwork(std::unique_ptr<zdl::SNPE::SNPE>& snpe,
std::unique_ptr<zdl::DlSystem::ITensor>& input) {
static zdl::DlSystem::TensorMap outputTensorMap;
snpe->execute(input.get(), outputTensorMap);
zdl::DlSystem::StringList tensorNames = outputTensorMap.getTensorNames();
const char* name = tensorNames.at(0);
auto tensorPtr = outputTensorMap.getTensor(name);
return tensorPtr;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









