





转自:帅b大佬
---恢复内容开始---
一般情况下我们使用爬虫更多的应该是爬数据或者图片吧,今天在这里和大家分享一下关于使用爬虫技术来进行视频下载的方法,不仅可以方便的下载一些体积小的视频,针对大容量的视频下载同样试用。
先上个?
requests模块的iter_content方法
这里我们使用的是python的requests模块作为例子,需要获取文本的时候我们会使用response.text获取文本信息,使用response.content获取字节流,比如下载图片保存到一个文件,而对于大个的文件我们就要采取分块读取的方式了,
requests.get方法的stream
第一步,我们需要设置requests.get的stream参数为True。
默认情况下是stream的值为false,它会立即开始下载文件并存放到内存当中,倘若文件过大就会导致内存不足的情况.
当把get函数的stream参数设置成True时,它不会立即开始下载,当你使用iter_content或iter_lines遍历内容或访问内容属性时才开始下载。需要注意一点:文件没有下载之前,它也需要保持连接。

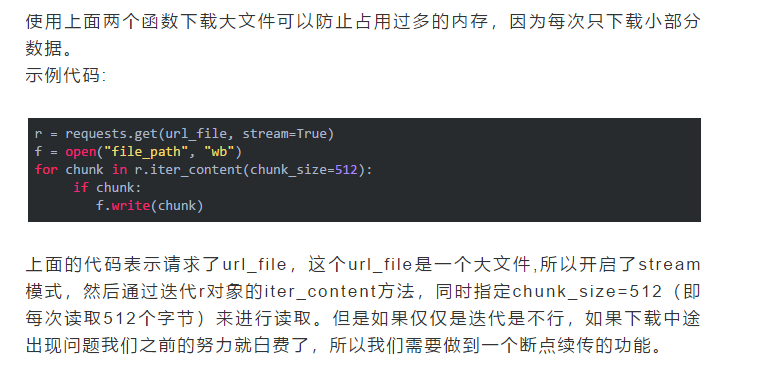
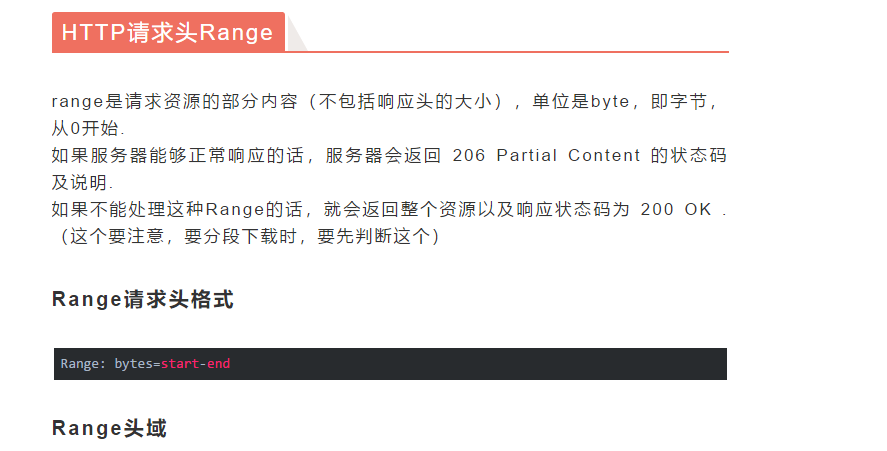
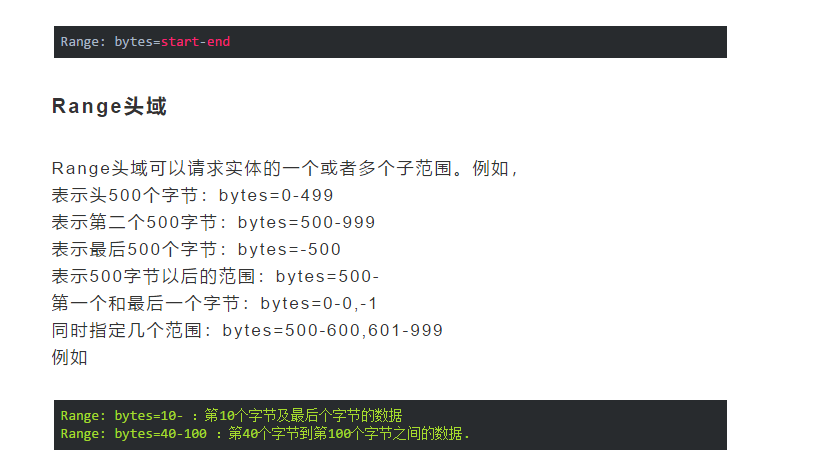

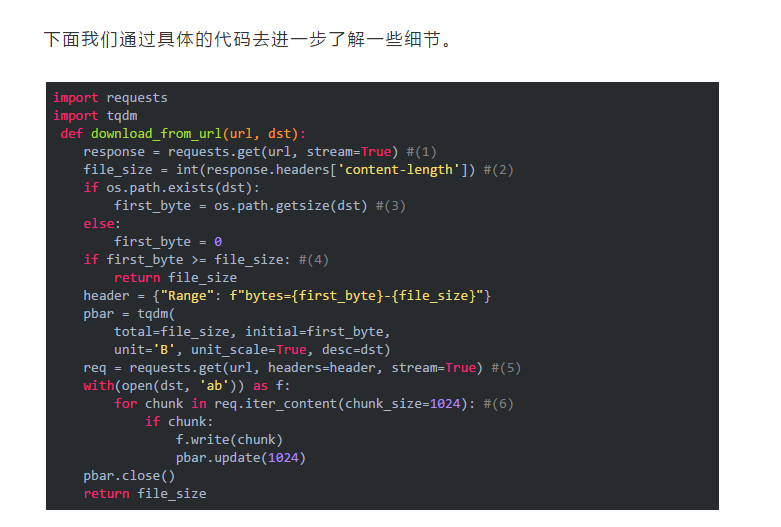
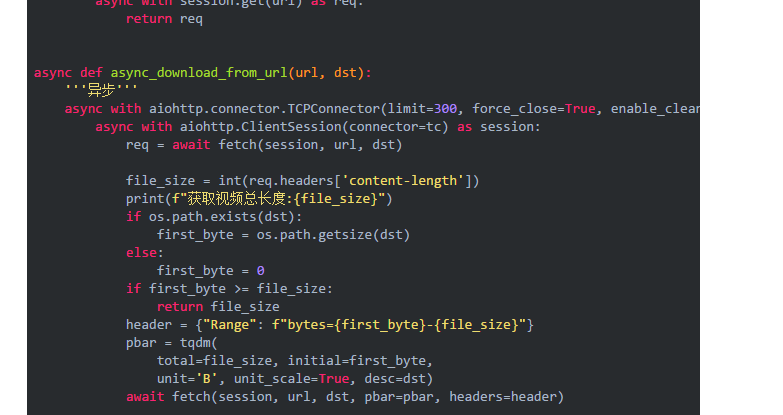
下面我们开始解读标有注释的代码:
tqdm是一个可以显示进度条的包,具体的用法可以参考官网文档:https://pypi.org/project/tqdm/
(1)设置stream=True参数读取大文件。
(2)通过header的content-length属性可以获取文件的总容量。
(3)获取本地已经下载的部分文件的容量,方便继续下载,当然需要判断文件是否存在,如果不存在就从头开始下载。
(4)本地已下载文件的总容量和网络文件的实际容量进行比较,如果大于或者等于则表示已经下载完成,否则继续。
(5)开始请求视频文件了
(6)循环读取每次读取一个1024个字节,当然你也可以设置512个字节
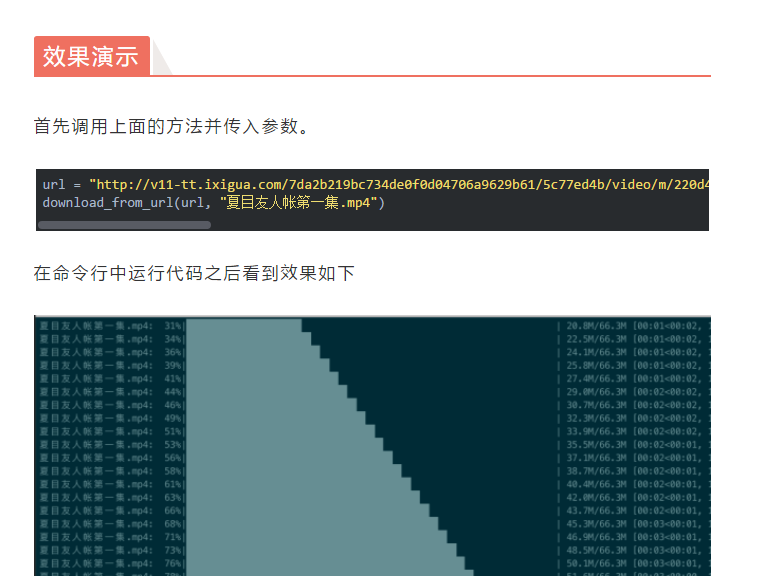
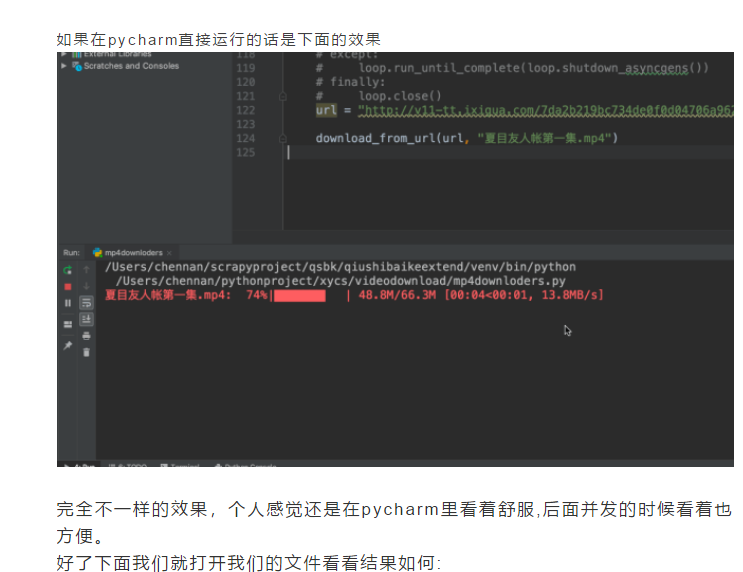
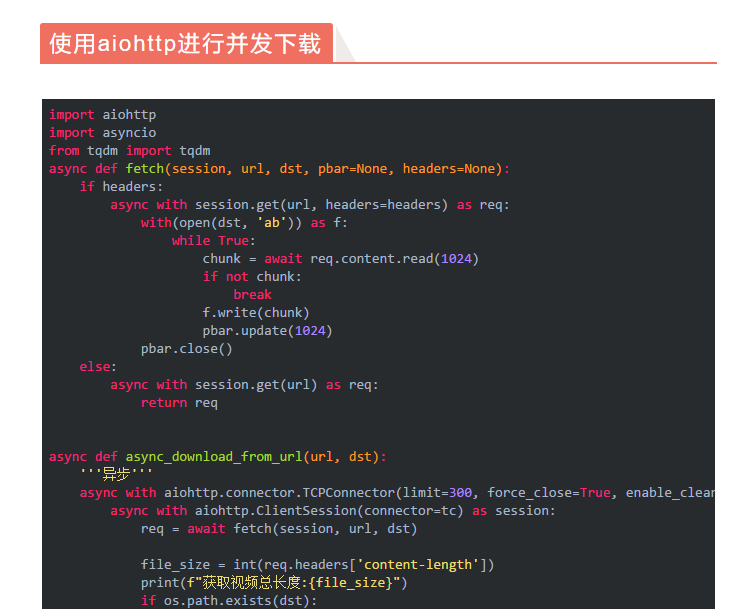
---恢复内容结束---















 724
724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









